标签:filename 可视化 href csv文件 sci window 信息 任务 爬虫设计
一、主题式网络爬虫设计方案
1.主题式网络爬虫名称:爬取微博热搜榜
2.主题式网络爬虫爬取的内容:微博热搜前十
3.主题式网络爬虫设计方案概述:确定爬取网页,将爬取数据保存到csv文件中,并对数据进行清理处理,将数据进行可视化并建立回归方程。知识掌握不充分,对网页爬取还有很多不懂。
二、主题页面的结构特征分析
1.主题页面的结构与特征分析
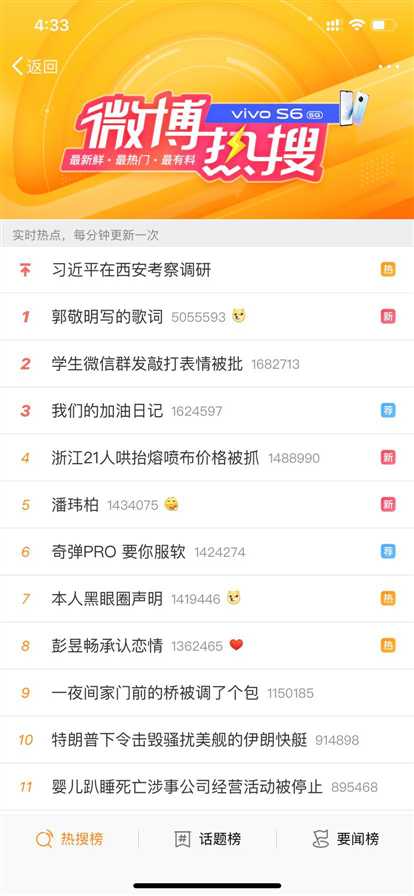
2.Htmls页面解析
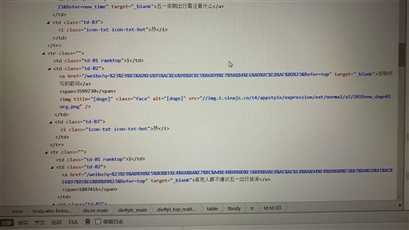
三、网络爬虫程序设计
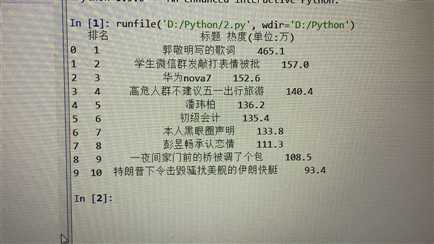
1.数据爬取与采集
import requests
from bs4 import BeautifulSoup
import pandas as pd
import numpy as np
import reurl = ‘https://tophub.today/n/KqndgxeLl9‘
headers = { ‘User-Agent‘:‘Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36‘}
response = requests.get(url,headers=headers)
html = response.content.decode(‘utf-8‘)
html = response.text
titles = re.findall(‘<a href=.*? target="_blank" .*?>(.*?)</a>‘,html)[3:13]
hot = re.findall(‘<td>(.*?)</td>‘,html)[0:10]
a = []#创建空列表
for i in range(10):
a.append([i+1,titles[i],hot[i][:-1]])
#完成创建
file = pd.DataFrame(a,columns = [‘排名‘,‘标题‘,‘热度(单位:万)‘])
print(file)
file.to_csv(‘微博热搜.csv‘)#保存文件
2.对数据进行清洗和处理
s = pd.DataFrame(pd.read_csv(‘微博热搜.csv‘))
s.head()
s.drop(‘热度(单位:万)‘,axis = 1,inplace=True)#删除无效列
s.head()
s.duplicated()#查找重复值
s.isna().head()#统计缺失值NaN
s.describe()#使用describe查看统计信息
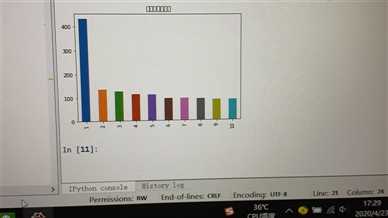
4.数据分析与可视化
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams[‘font.sans-serif‘]=[‘Arial Unicode Ms‘]#用来正常显示中文标签
plt.rcParams[‘axes.unicode_minus‘]=False#用来正确显示负号
data=np.array([431.3,135.5,128.0,114.0,112.8,97.0,95.5,93.1,89.9,89.3])
index=[‘1‘,‘2‘,‘3‘,‘4‘,‘5‘,‘6‘,‘7‘,‘8‘,‘9‘,‘10‘]
s = pd.Series(data,index)
s.name=‘微博热搜条形图‘
s.plot(kind=‘bar‘,title=‘微博热搜条形图‘)
plt.show()
5.根据数据之间的关系,分析两个变量之间的相关系数,画出散点图,并建立变量之间的回归方程(一元或多元)
import numpy as np
import scipy as sp
import matplotlib.pyplot as plt
import matplotlib
from scipy.optimize import leastsq
filename = ‘微博热搜.csv‘
colnames=["排名","热度(单位:万)","标题"]
df = pd.read_csv(filename,skiprows=1,names=colnames)
X=df.排名
Y=df.标题
def fit_func(p,x):
a,b,c=p
return a*x*x+b*x+c
def error_func(p,x,y):
return fit_func(p,x)-y
p0=[2,4,6]
para=leastsq(error_func,p0,args=(X,Y))
a,b,c=para[0]
plt.figure(figsize=(8,4))
plt.scatter(X,Y,color="pink",label=u"热搜数据",linewidth=2)
x=np.linspace(0,25,20)
y=a*x*x+b*x+c
plt.plot(x,y,color="blue",label=u"拟合直线",linewidth=2)
plt.title("微博热搜回归方程")
plt.legend()
plt.show()
7.将以上各部分的代码汇总,附上完整程序代码
import requests
from bs4 import BeautifulSoup
import pandas as pd
import numpy as np
import re
url = ‘https://tophub.today/n/KqndgxeLl9‘
headers = { ‘User-Agent‘:‘Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36‘}
response = requests.get(url,headers=headers)
html = response.content.decode(‘utf-8‘)
html = response.text
#print(html)
#解析网页与抓取信息
titles = re.findall(‘<a href=.*? target="_blank" .*?>(.*?)</a>‘,html)[3:13]#正则表达
hot = re.findall(‘<td>(.*?)</td>‘,html)[0:10]
a = []#创建空列表
for i in range(10):
a.append([i+1,titles[i],hot[i][:-1]])
#完成创建
file = pd.DataFrame(a,columns = [‘排名‘,‘标题‘,‘热度(单位:万)‘])
print(file)file.to_csv(‘微博热搜.csv‘)#保存文件
s = pd.DataFrame(pd.read_csv(‘微博热搜.csv‘))
s.head()
s.drop(‘热度(单位:万)‘,axis = 1,inplace=True)#删除无效列
s.head()
s.duplicated()#查找重复值
s.isna().head()#统计缺失值NaN
s.describe()#使用describe查看统计信息
#绘制条形图
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams[‘font.sans-serif‘]=[‘Arial Unicode Ms‘]#用来正常显示中文标签
plt.rcParams[‘axes.unicode_minus‘]=False#用来正确显示负号
data=np.array([431.3,135.5,128.0,114.0,112.8,97.0,95.5,93.1,89.9,89.3])
index=[‘1‘,‘2‘,‘3‘,‘4‘,‘5‘,‘6‘,‘7‘,‘8‘,‘9‘,‘10‘]
s = pd.Series(data,index)
s.name=‘微博热搜条形图‘
s.plot(kind=‘bar‘,title=‘微博热搜条形图‘)
plt.show()
#绘制拟合曲线
import numpy as np
import scipy as sp
import matplotlib.pyplot as plt
import matplotlib
from scipy.optimize import leastsq
filename = ‘微博热搜.csv‘
colnames=["排名","热度(单位:万)","标题"]
df = pd.read_csv(filename,skiprows=1,names=colnames)
X=df.排名
Y=df.标题
def fit_func(p,x):
a,b,c=p
return a*x*x+b*x+c
def error_func(p,x,y):
return fit_func(p,x)-y
p0=[2,4,6]
para=leastsq(error_func,p0,args=(X,Y))
a,b,c=para[0]
plt.figure(figsize=(8,4))
plt.scatter(X,Y,color="pink",label=u"热搜数据",linewidth=2)
x=np.linspace(0,25,20)
y=a*x*x+b*x+c
plt.plot(x,y,color="blue",label=u"拟合直线",linewidth=2)
plt.title("微博热搜回归方程")
plt.legend()
plt.show()
四、结论
1.经过对主题数据的分析与可视化,可以得到哪些结论?
这有助于我们清晰的了解微博热搜的变化
2.对本次程序设计任务完成的情况做一个简单的小结。
通过这次任务,我了解到了自身许多的不住还有许多需要改进的地方
标签:filename 可视化 href csv文件 sci window 信息 任务 爬虫设计
原文地址:https://www.cnblogs.com/Redbigbaby/p/12762668.html