标签:params rank pac 提取 header 根据 agg 存储 def
一、主题式网络爬虫设计方案
1,主题式网络爬虫名称:
爬取猫眼电影TOP100
2,主题式网络爬虫爬取的内容与数据特征分析:
爬取内容为:电影名,得分,
数据特征分析:将其储存于xlsx文件中
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
实现思路:首先进行对网页源代码的访问分析,用BeautifulSoup进行HTML的解析和信息的爬取,后续对爬取下来的信息用pandas进行绘图数据分析
技术难点:爬取信息时对标签的查找,写出查找所需标签的代码,对数据进行相应的分析
二、主题页面的结构特征分析
1.首先是对页面的解析
1 import matplotlib as mpl 2 mpl.use(‘agg‘) 3 import requests 4 import re 5 import pandas as pd 6 import time 7 import seaborn as sns 8 sns.set() 9 mpl.rcParams[‘font.sans-serif‘]=[u‘SimHei‘] 10 mpl.rcParams[‘axes.unicode_minus‘]=False 11 def get_one_page(url, headers): 12 ‘‘‘ 13 抓取单个网页的源码 14 ‘‘‘ 15 # 添加headers参数,伪装成浏览器 16 response = requests.get(url, headers=headers) 17 # 200意味着成功的请求 18 if response.status_code == 200: 19 return response.content.decode(‘utf-8‘) 20 return None 21 # 设置猫眼电影TOP100的url 22 23 urls = [‘http://maoyan.com/board/4?offset={0}‘.format(i) for i in range(0, 100, 10)] 24 25 26 headers = { 27 ‘User-Agent‘: ‘Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36‘ 28 } 29 # 先把所有网页源码爬下来 30 data = [] 31 for url in urls: 32 tmp = get_one_page(url, headers=headers) 33 if not tmp == None: 34 data.append(tmp) 35 time.sleep(0.5) 36 # 查看一下爬取的网页数量是否符合预期 37 print(‘{0} pages crawled‘.format(len(data)))
2.分析节点,打开网址https://maoyan.com/board/4,F12或右键点击检查
三、网络爬虫程序设计
1.数据爬取与采集
1 # 利用正则表达式,解析电影名、主演、排名、上映时间、分数数据 2 # 使用re.compile将各个正则表达式封装成正则表达式对象,方便后边解析使用。re.S参数是为了让‘.‘能匹配空格。 3 actor_pattern = re.compile(‘<p\sclass="star">\s*(.*?)\s*</p>‘, re.S) 4 title_pattern = re.compile(‘class="name".*?movieId.*?>(.*?)</a></p>‘, re.S) 5 index_pattern = re.compile(‘<dd>.*?board-index.*?>(\d+)</i>‘, re.S) 6 time_pattern = re.compile(‘<p\sclass="releasetime">(.*?)</p>‘, re.S) 7 score_pattern = re.compile(‘<p\sclass="score"><i\sclass="integer">(\d+)\.</i><i\sclass="fraction">(\d+)</i></p>‘, re.S) 8 9 # 使用列表来存储数据 10 indexes = [] 11 actors = [] 12 titles = [] 13 release_times = [] 14 scores = [] 15 16 # 循环解析十个网页,将解析出来的数据附加在对应的列表中 17 for page in data: 18 indexes.extend(re.findall(index_pattern, page)) 19 titles.extend(re.findall(title_pattern, page)) 20 actors.extend(re.findall(actor_pattern, page)) 21 release_times.extend(re.findall(time_pattern, page)) 22 scores.extend(re.findall(score_pattern, page)) 23 # 清洗主演、上映时间、上映国家或地区、评分数据 24 actors = [i.strip(‘主演:‘) for i in actors] 25 26 #将这些默认缺失的部分补充为‘中国‘ 27 locs = [i.strip(‘上映时间:‘)[10:].strip(‘()‘) if len(i.strip(‘上映时间:‘)) > 10 else ‘中国‘ for i in release_times] 28 29 # 我们把字符串中‘上映时间:’这些没用的去掉,然后取十位 30 31 release_times = [i.strip(‘上映时间:‘)[:10] for i in release_times] 32 33 # 处理一下解析的时候分开提取的分数的个位数与小数 34 scores = [int(i) + int(j)/10 for i, j in scores] 35 # 生成DataFrame 36 df = pd.DataFrame({ 37 ‘rank‘: indexes, 38 ‘title‘: titles, 39 ‘actor‘: actors, 40 ‘release_time‘: release_times, 41 ‘score‘: scores, 42 ‘location‘: locs 43 }) 44 # 修改列名 45 df = df[[‘rank‘, ‘title‘, ‘actor‘, ‘score‘, ‘location‘, ‘release_time‘]]
2.保存到excel文件中
1 df.to_excel(‘./maoyan_top100_movie.xlsx‘, index=False) 2 3 # 展示一下数据 4 df.head()
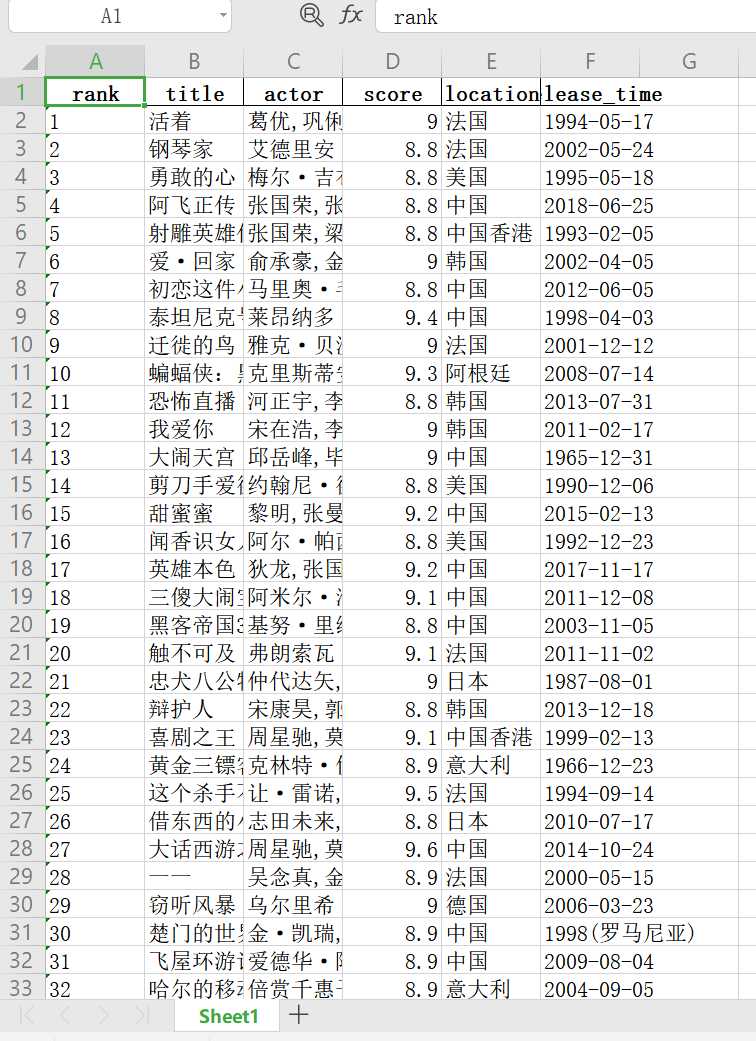
保存成功
3.对数据的处理
#数据可视化
1 import pandas as pd 2 df = pd.DataFrame(pd.read_excel(‘D:\kfc\maoyan_top100_movie.xlsx‘)) 3 print(df.head(10))

#异常值观察
1 df = pd.DataFrame(pd.read_excel(‘D:\kfc\maoyan_top100_movie.xlsx‘)) 2 print(df.describe())
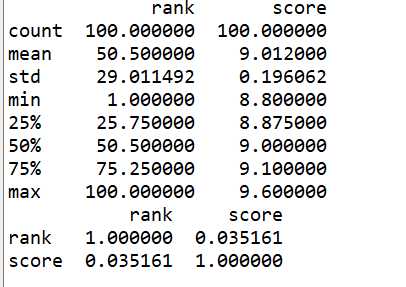
#查看相关系数
1 df = pd.DataFrame(pd.read_excel(‘D:\kfc\maoyan_top100_movie.xlsx‘)) 2 print(df.corr())

4.数据分析
#导入各库
1 import pandas as pd 2 from matplotlib import pyplot as plt 3 import seaborn as sns 4 import numpy as np 5 from scipy.optimize import leastsq
#绘制散点图
def Sspot(): df = pd.DataFrame(pd.read_excel(‘D:\kfc\maoyan_top100_movie.xlsx‘)) #赋予x,y所对应的值 x = df.title[:10] y = df.score[:10] plt.xlabel("电影名") plt.ylabel("得分") plt.scatter(x,y,color="green",label="散点",s=50) plt.title("猫眼电影得分") plt.legend() plt.show() Sspot()
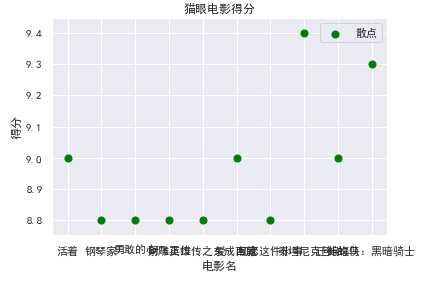
#绘制扇形图
1 def Pspot(): 2 df = pd.DataFrame(pd.read_excel(‘D:\kfc\maoyan_top100_movie.xlsx‘)) 3 x = df.title 4 y = df.score 5 #前五名的电影标题 6 name = [x[0],x[1],x[2],x[3],x[4]] 7 math = [y[0],y[1],y[2],y[3],y[4]] 8 explode=[0.1,0.1,0.1,0.1,0.1] 9 plt.pie(math,labels=name,colors=["r","g","c","b","y"],explode=explode) 10 plt.axis("equal") 11 plt.title("猫眼电影得分") 12 plt.show() 13 Pspot()
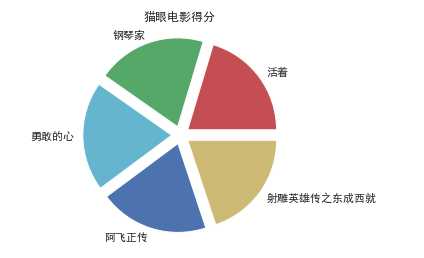
#绘制猫眼的条形图
def Tspot(): df = pd.DataFrame(pd.read_excel(‘D:\kfc\maoyan_top100_movie.xlsx‘)) x = df.title[:10] y = df.score[:10] plt.xlabel("电影名") plt.ylabel("得分") plt.bar(x,y,color="green") plt.title("猫眼电影得分的条形图") plt.show() Tspot()
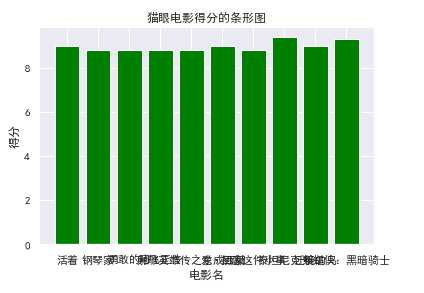
#绘制折线图
1 def Zspot(): 2 df = pd.DataFrame(pd.read_excel(‘D:\kfc\maoyan_top100_movie.xlsx‘)) 3 x = df.title[:10] 4 y = df.score[:10] 5 plt.xlabel("电影名") 6 plt.ylabel("得分") 7 plt.plot(x,y,color="green",label="折线") 8 plt.title("猫眼电影得分的折线图") 9 plt.legend() 10 plt.show() 11 Zspot()
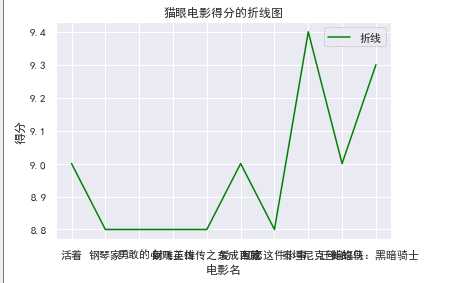
#回归直线图
1 c=sns.regplot(x=‘rank‘,y=‘score‘,data=df) 2 print(c)
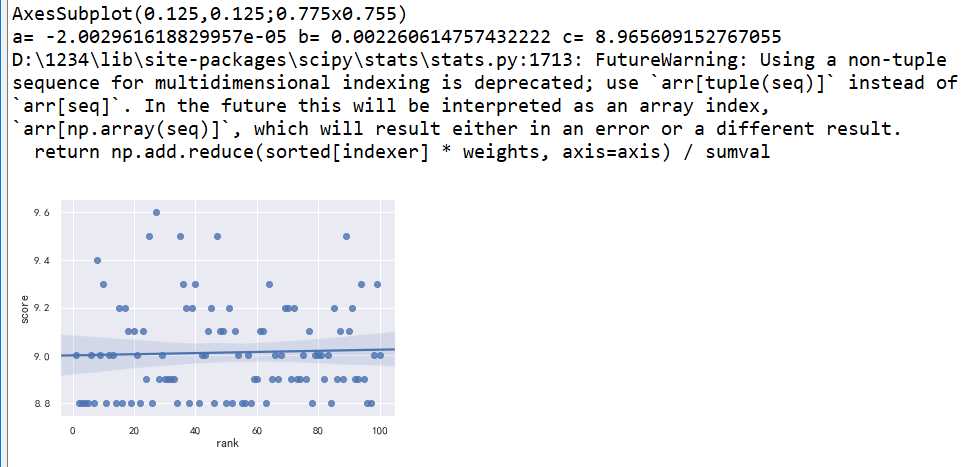
#回归方程
1 X=df.loc[:,‘rank‘] 2 Y=df.loc[:,‘score‘] 3 def func(params,x): 4 a,b,c=params 5 return a*x*x+b*x+c 6 def error_func(params,x,y): 7 return func(params,x)-y 8 P0=[1,9.0] 9 def main(): 10 plt.figure(figsize=(8,6)) 11 P0=[1,9.0,1] 12 Para=leastsq(error_func,P0,args=(X,Y)) 13 a,b,c=Para[0] 14 print("a=",a, "b=",b, "c=",c) 15 plt.scatter(X,Y,color="green",label="样本数据",linewidth=2) 16 x=np.linspace(1,100,40) 17 y=a*x*x+b*x+c 18 plt.plot(x,y,color="red",label="拟合曲线",linewidth=2) 19 plt.xlabel(‘排名‘) 20 plt.ylabel(‘得分‘) 21 plt.title("排名与得分回归方程") 22 plt.grid() 23 plt.legend() 24 plt.show() 25 main()
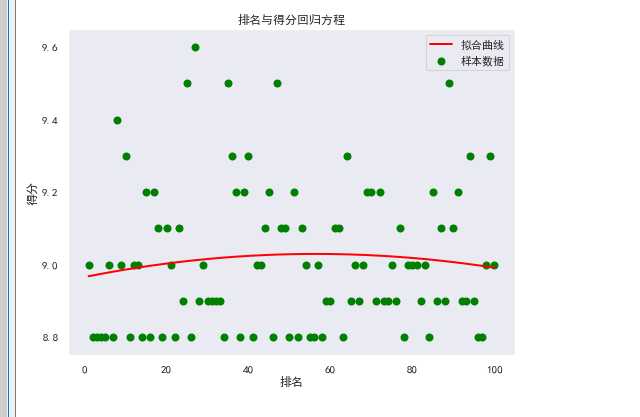
5.代码汇总
1 import matplotlib as mpl 2 mpl.use(‘agg‘) 3 import requests 4 import re 5 import pandas as pd 6 import time 7 import seaborn as sns 8 9 from matplotlib import pyplot as plt 10 11 import numpy as np 12 from scipy.optimize import leastsq 13 sns.set() 14 mpl.rcParams[‘font.sans-serif‘]=[u‘SimHei‘] 15 mpl.rcParams[‘axes.unicode_minus‘]=False 16 def get_one_page(url, headers): 17 ‘‘‘ 18 抓取单个网页的源码 19 ‘‘‘ 20 # 添加headers参数,伪装成浏览器 21 response = requests.get(url, headers=headers) 22 # 200意味着成功的请求 23 if response.status_code == 200: 24 return response.content.decode(‘utf-8‘) 25 return None 26 # 设置猫眼电影TOP100的url 27 28 urls = [‘http://maoyan.com/board/4?offset={0}‘.format(i) for i in range(0, 100, 10)] 29 30 31 headers = { 32 ‘User-Agent‘: ‘Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36‘ 33 } 34 # 先把所有网页源码爬下来 35 data = [] 36 for url in urls: 37 tmp = get_one_page(url, headers=headers) 38 if not tmp == None: 39 data.append(tmp) 40 time.sleep(0.5) 41 # 查看一下爬取的网页数量是否符合预期 42 print(‘{0} pages crawled‘.format(len(data))) 43 44 45 # 利用正则表达式,解析电影名、主演、排名、上映时间、分数数据 46 # 使用re.compile将各个正则表达式封装成正则表达式对象,方便后边解析使用。re.S参数是为了让‘.‘能匹配空格。 47 actor_pattern = re.compile(‘<p\sclass="star">\s*(.*?)\s*</p>‘, re.S) 48 title_pattern = re.compile(‘class="name".*?movieId.*?>(.*?)</a></p>‘, re.S) 49 index_pattern = re.compile(‘<dd>.*?board-index.*?>(\d+)</i>‘, re.S) 50 time_pattern = re.compile(‘<p\sclass="releasetime">(.*?)</p>‘, re.S) 51 score_pattern = re.compile(‘<p\sclass="score"><i\sclass="integer">(\d+)\.</i><i\sclass="fraction">(\d+)</i></p>‘, re.S) 52 53 # 使用列表来存储数据 54 indexes = [] 55 actors = [] 56 titles = [] 57 release_times = [] 58 scores = [] 59 60 # 循环解析十个网页,将解析出来的数据附加在对应的列表中 61 for page in data: 62 indexes.extend(re.findall(index_pattern, page)) 63 titles.extend(re.findall(title_pattern, page)) 64 actors.extend(re.findall(actor_pattern, page)) 65 release_times.extend(re.findall(time_pattern, page)) 66 scores.extend(re.findall(score_pattern, page)) 67 # 清洗主演、上映时间、上映国家或地区、评分数据 68 actors = [i.strip(‘主演:‘) for i in actors] 69 70 #将这些默认缺失的部分补充为‘中国‘ 71 locs = [i.strip(‘上映时间:‘)[10:].strip(‘()‘) if len(i.strip(‘上映时间:‘)) > 10 else ‘中国‘ for i in release_times] 72 73 # 我们把字符串中‘上映时间:’这些没用的去掉,然后取十位 74 75 release_times = [i.strip(‘上映时间:‘)[:10] for i in release_times] 76 77 # 处理一下解析的时候分开提取的分数的个位数与小数 78 scores = [int(i) + int(j)/10 for i, j in scores] 79 # 生成DataFrame 80 df = pd.DataFrame({ 81 ‘rank‘: indexes, 82 ‘title‘: titles, 83 ‘actor‘: actors, 84 ‘release_time‘: release_times, 85 ‘score‘: scores, 86 ‘location‘: locs 87 }) 88 # 修改列名 89 df = df[[‘rank‘, ‘title‘, ‘actor‘, ‘score‘, ‘location‘, ‘release_time‘]] 90 # 保存到本地excel文件中 91 df.to_excel(‘./maoyan_top100_movie.xlsx‘, index=False) 92 93 # 展示一下数据 94 df.head() 95 96 #数据可视化 97 df = pd.DataFrame(pd.read_excel(‘D:\kfc\maoyan_top100_movie.xlsx‘)) 98 print(df.head(10)) 99 #异常值的观察 100 df = pd.DataFrame(pd.read_excel(‘D:\kfc\maoyan_top100_movie.xlsx‘)) 101 print(df.describe()) 102 #查看相关系数 103 df = pd.DataFrame(pd.read_excel(‘D:\kfc\maoyan_top100_movie.xlsx‘)) 104 print(df.corr()) 105 #散点图 106 def Sspot(): 107 df = pd.DataFrame(pd.read_excel(‘D:\kfc\maoyan_top100_movie.xlsx‘)) 108 #赋予x,y所对应的值 109 x = df.title[:10] 110 y = df.score[:10] 111 plt.xlabel("电影名") 112 plt.ylabel("得分") 113 plt.scatter(x,y,color="green",label="散点",s=50) 114 plt.title("猫眼电影得分") 115 plt.legend() 116 plt.show() 117 Sspot() 118 #绘制扇形图 119 def Pspot(): 120 df = pd.DataFrame(pd.read_excel(‘D:\kfc\maoyan_top100_movie.xlsx‘)) 121 x = df.title 122 y = df.score 123 #前五名的电影标题 124 name = [x[0],x[1],x[2],x[3],x[4]] 125 math = [y[0],y[1],y[2],y[3],y[4]] 126 explode=[0.1,0.1,0.1,0.1,0.1] 127 plt.pie(math,labels=name,colors=["r","g","c","b","y"],explode=explode) 128 plt.axis("equal") 129 plt.title("猫眼电影得分") 130 plt.show() 131 Pspot() 132 #猫眼电影得分的条形图 133 def Tspot(): 134 df = pd.DataFrame(pd.read_excel(‘D:\kfc\maoyan_top100_movie.xlsx‘)) 135 x = df.title[:10] 136 y = df.score[:10] 137 plt.xlabel("电影名") 138 plt.ylabel("得分") 139 plt.bar(x,y,color="green") 140 plt.title("猫眼电影得分的条形图") 141 plt.show() 142 Tspot() 143 #猫眼电影得分的折线图 144 def Zspot(): 145 df = pd.DataFrame(pd.read_excel(‘D:\kfc\maoyan_top100_movie.xlsx‘)) 146 x = df.title[:10] 147 y = df.score[:10] 148 plt.xlabel("电影名") 149 plt.ylabel("得分") 150 plt.plot(x,y,color="green",label="折线") 151 plt.title("猫眼电影得分的折线图") 152 plt.legend() 153 plt.show() 154 Zspot() 155 156 #回归图 157 c=sns.regplot(x=‘rank‘,y=‘score‘,data=df) 158 print(c) 159 #回归方程 160 X=df.loc[:,‘rank‘] 161 Y=df.loc[:,‘score‘] 162 def func(params,x): 163 a,b,c=params 164 return a*x*x+b*x+c 165 def error_func(params,x,y): 166 return func(params,x)-y 167 P0=[1,9.0] 168 def main(): 169 plt.figure(figsize=(8,6)) 170 P0=[1,9.0,1] 171 Para=leastsq(error_func,P0,args=(X,Y)) 172 a,b,c=Para[0] 173 print("a=",a, "b=",b, "c=",c) 174 plt.scatter(X,Y,color="green",label="样本数据",linewidth=2) 175 x=np.linspace(1,100,40) 176 y=a*x*x+b*x+c 177 plt.plot(x,y,color="red",label="拟合曲线",linewidth=2) 178 plt.xlabel(‘排名‘) 179 plt.ylabel(‘得分‘) 180 plt.title("排名与得分回归方程") 181 plt.grid() 182 plt.legend() 183 plt.show() 184 main()
四、结论
根据图形可以看出,排名靠前的不一定就是得分最高的,通过对图形的观察,可以发现很多平时难以发现的细节。
小结:在完成猫眼爬虫和数据可视化的过程中,有过很多困难,在经过上网查找资料,阅读课内教材,同学之间地探讨,这些问题最终都迎刃而解。也让我认识到了python的不简单,对我以后的学习有了很大的帮助。
标签:params rank pac 提取 header 根据 agg 存储 def
原文地址:https://www.cnblogs.com/Kingdom-day/p/12762664.html