标签:draw comm 根据 child format array 列表 转变 特殊
一、主题式网络爬虫设计方案
1.主题式网络爬虫名称
爬取当当网新书排行榜数据分析
2.主题式网络爬虫爬取的内容与数据特征分析
爬取新书书名和价格、折扣
数据之间有线性关系,
3.主题式网络爬虫设计方案概述
思路:分析html页面,找到所需内容所在节点,爬取采集数据,将数据可视化,最后做线性回归。
技术难点:分析源代码,数据类型的转变,数据线性回归。
二、主题页面的结构特征分析
1.主题页面的结构与特征分析

2.Htmls页面解析

3.节点(标签)查找方法与遍历方法
print("所有的标题:",soup.select("title")) #查看网站的id=link1后的所有兄弟节点标签 print("id=link1后的所有兄弟节点标签:",soup.select("body a")) #查看a标签,其类属性为sister的标签 print("a标签,其类属性为sister的标签:",soup.select("#link1 ~.sister")) #查看a标签中具有href属性的标签 print("a标签中具有href属性的标签:",soup.select(‘a[href]‘)) #查看a标签中的父节点 print("a标签中的父节点:",soup.a.parent) #查看p标签中的子节点 print("p标签中的子节点:",soup.p.children)
三、网络爬虫程序设计
爬虫程序主体要包括以下各部分,要附源代码及较详细注释,并在每部分程序后面提供输出结果的截图。
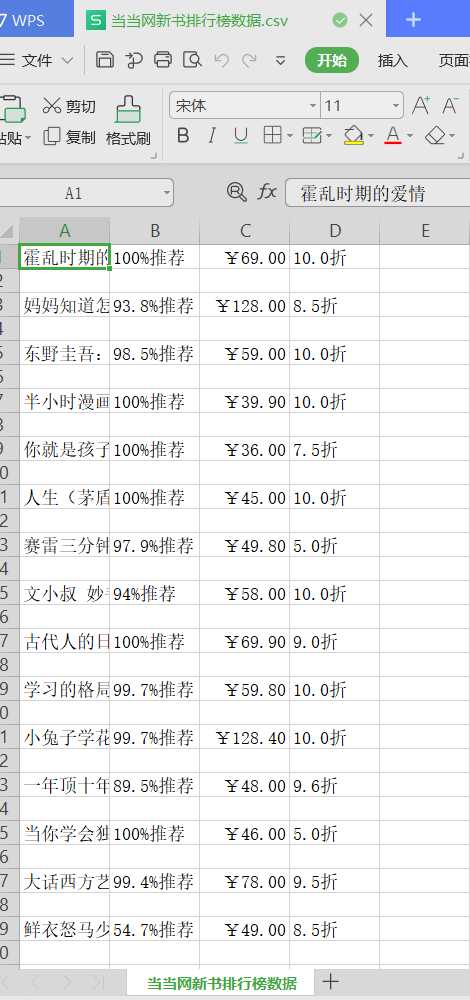
1.数据爬取与采集
数据采集
import numpy as np import matplotlib.pyplot as plt import matplotlib as mpl from scipy.optimize import leastsq import requests from bs4 import BeautifulSoup import pandas as pd import csv import jieba import wordcloud #数据采集(爬取在最后主程序) def data_collcation(soup,bookname,recommendindex,price,discount): #发现在网页结构中书名保存在“class=”name“中,索引标签爬取信息 for i in soup.find_all(class_="name"): bookname.append(i.get_text().strip()) #发现在网页结构中推荐指数保存在“class=”tuijian“中,索引标签爬取信息 for j in soup.find_all(class_="tuijian"): recommendindex.append(j.get_text().strip()) #发现在网页结构中购买价格保存在“class=”price_r“中,索引标签爬取信息 for k in soup.find_all(class_="price_r"): price.append(k.get_text().strip()) #发现在网页结构中购买折扣保存在“class=”price_s“中,索引标签爬取信息 for l in soup.find_all(class_="price_s"): discount.append(l.get_text().strip()) #写入数据 def csv_fi(v): #把文件转换成二维表 data=np.array(v.T) csv_1=open("C:\python\\当当网新书排行榜数据.csv", "w", encoding="utf-8") #把二维表写入CSV文件中 writer=csv.writer(csv_1) for i in data: writer.writerow(i) #关闭文件 csv_1.close()

2.对数据进行清洗和处理
def dataclear(): data_2=pd.read_csv("C:\python\\当当网新书排行榜数据.csv", names=["书名","推荐指数","购买价格","购买折扣"]) #查看文件 print(data_2) try: #查找是否有空值 print(data_2.isnull().value_counts()) #把空值都变为零 data_2.fillna(0) except: print("没有空值") try: #查看重复值 print(data_2.duplicated()) #删除重复值 data_2.drop_duolicated() except: print("没有重复值") try: #查看异常值 print(data_2.describe()) except: print("无法查看异常值") #再次查看数据 print(data_2) #穿件空列表 recommendindex2=[] price2=[] discount2=[] #删除“推荐指数”中不需要的文字 for i in data_2["推荐指数"]: recommendindex=i.strip(‘%推荐‘) recommendindex2.append(recommendindex) #删除“购买价格”中不需要的符号 for j in data_2["购买价格"]: price=j.strip(‘¥‘) price2.append(price) #删除“购买折扣”中不需要的文字 for k in data_2["购买折扣"]: discount=k.strip(‘折‘) discount2.append(discount) bookname2=np.array(data_2["书名"]) #整合新数据 newdata=[bookname2,recommendindex2,price2,discount2] #设置数据标题 index2=["书名","推荐指数","购买价格","购买折扣"] #把数据用DataFrame转变成一个二维列表 v2=pd.DataFrame(newdata,index2) v3=v2.T #打开创建好的文件 csv_2=open("C:\python\\当当网新书排行榜清洗数据.csv", "w", encoding="utf-8") headers=["书名","推荐指数","购买价格","购买折扣"] #把清洗好的数据写入CSV文档中 v3.to_csv(csv_2, header=headers, index=False, mode="a+") #关闭文件 csv_2.close() #把书名写入一个txt文档为了方便进行文档分析 def txt_new(bookname): fi=open("C:\python\\当当网新书书名.txt", "w", encoding="utf-8") #把书名一行行的写进文档中 for p in bookname: fi.write("".join(p)+"\n") #关闭文件 fi.close()
二维表(输出代码在主程序)

有无重复值

查看异常值

表格
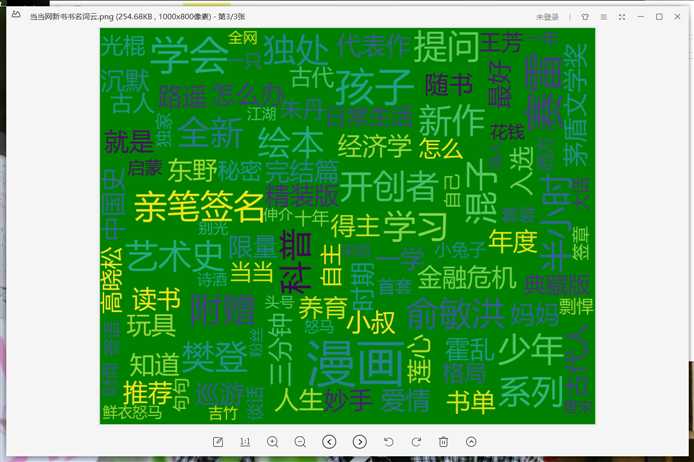
3.文本分析
def cloud(): #打开之前保存的文本txt txt=open("C:\python\\当当网新书书名.txt","rb").read() #解码 txt_1=txt.decode() #把txt文本中的特殊符号换成空格 for ch in ‘:...()“”、?!?,‘: txt_1=txt_1.replace(ch," ") #对文本进行分词 txt_2=jieba.lcut(txt_1) print(txt_2) #设置词云的参数 w=wordcloud.WordCloud(width=1000, height=800, font_path="msyh.ttc", min_font_size=30, max_font_size=100, font_step=5, background_color="green") #把文本的内容进行分词,并生成词云 w.generate(" ".join(txt_2)) #保存到本地 w.to_file("C:\python\\当当网新书书名词云.png")
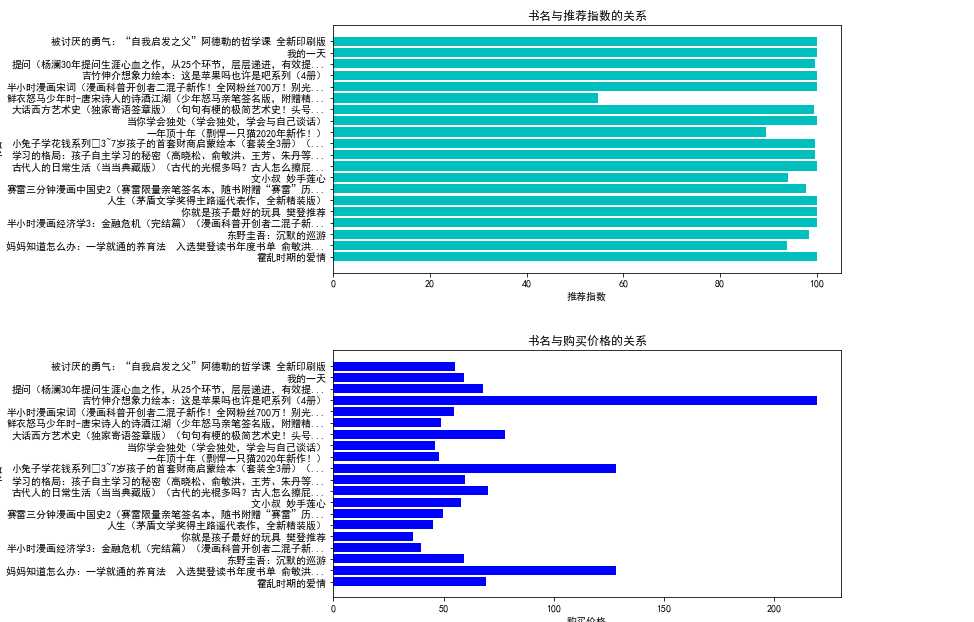
4.数据分析与可视化
“书名”和“推荐指数”的,“书名”和“购买价格”条形图
def drawing(): #打开清洗好的数据 data=pd.read_csv("C:\python\\当当网新书排行榜清洗数据.csv") #读取数据 X=np.array(data.loc[:,"书名"]) Y1=np.array(data.loc[:,"推荐指数"]) Y2=np.array(data.loc[:,"购买价格"]) Y3=np.array(data.loc[:,"购买折扣"]) #设计画布的大小 plt.figure(figsize=(20,10)) #设置画布的位置 plt.subplot(2,2,1) #绘制“书名”和“推荐指数”的条形图 plt.barh(X, Y1, align="center", color="c") #设置标题 plt.title("书名与推荐指数的关系") #设置x轴的标题 plt.xlabel("推荐指数") #设置y轴的标题 plt.ylabel("书名") #展示条形图 plt.show() #设置画布大小 plt.figure(figsize=(20,10)) #设置画布位置 plt.subplot(2,2,2) #绘制“书名”和“购买价格”的条形图 plt.barh(X, Y2, align="center", color="blue")
#设置总标题 plt.title("书名与购买价格的关系") #设置x轴的标题 plt.xlabel("购买价格") #设置y轴的标题 plt.ylabel("书名") #展示条形图 plt.show() #设置画布大小 plt.figure(figsize=(20,10)) #设置画布位置 plt.subplot(2,1,2) #绘制“书名”和“购买折扣”的条形图 plt.barh(X, Y3, align="center", color="orange") #设置总标题 plt.title("书名与购买折扣的关系") #设置x轴标题 plt.xlabel("购买折扣") #设置y轴标题 plt.ylabel("书名") #展示条形图 plt.show()
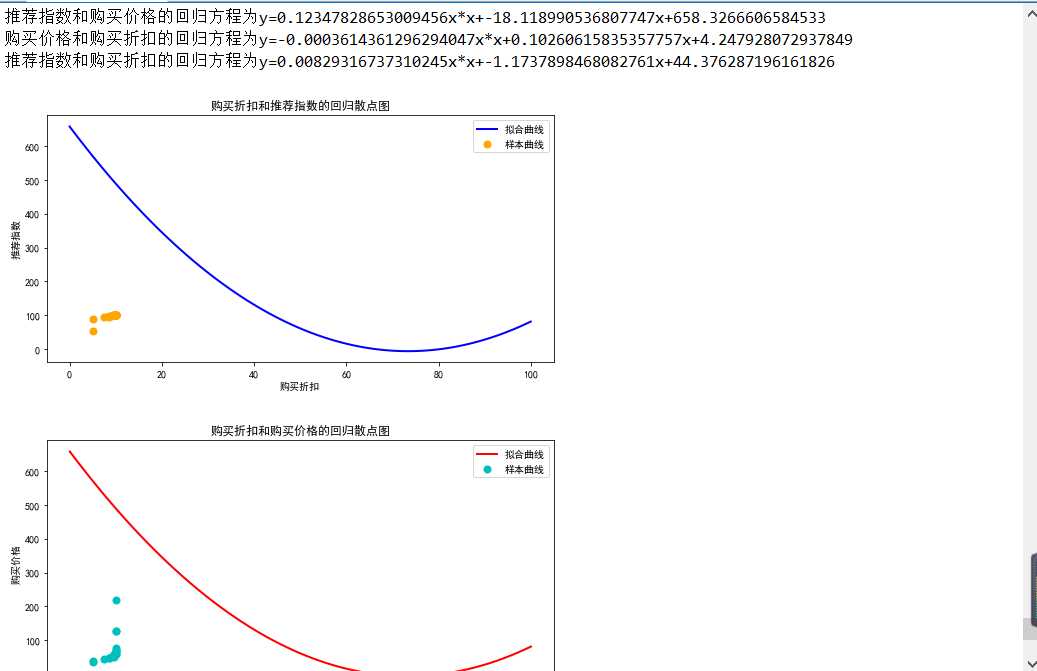
5.根据数据之间的关系,分析两个变量之间的相关系数,画出散点图,并建立变量之间的回归方程
建立回归方程
def Regressionanalysis(): #打开清洗好的数据 data=pd.read_csv("C:\python\\当当网新书排行榜清洗数据.csv") #读取数据 X=np.array(data.loc[:,"书名"]) Y1=np.array(data.loc[:,"推荐指数"]) Y1.sort() Y2=np.array(data.loc[:,"购买价格"]) Y2.sort() Y3=np.array(data.loc[:,"购买折扣"]) Y3.sort() #设置计酸最小二乘法的函数 def fit_func(p,x): a,b,c=p return a*x*x+b*x+c def error_func(p,x,y): return fit_func(p,x)-y #设置初始值 p0=[1,2,3] #使用leastsq计算最小二乘法 para=leastsq(error_func,p0,args=(Y1,Y2)) #描写回归方程 a,b,c=para[0] print(‘推荐指数和购买价格的回归方程为y={0}x*x+{1}x+{2}‘.format(a,b,c)) #设置初始值 p0_2=[1,2,3] #使用leastsq计算最小二乘法 para_2=leastsq(error_func,p0_2,args=(Y2,Y3)) #描写回归方程 a2,b2,c2=para_2[0] print(‘购买价格和购买折扣的回归方程为y={0}x*x+{1}x+{2}‘.format(a2,b2,c2)) #设置初始值 p0_3=[1,2,3] #使用leastsq计算最小二乘法 para_3=leastsq(error_func,p0_3,args=(Y1,Y3)) #描写回归方程 a3,b3,c3=para_3[0] print(‘推荐指数和购买折扣的回归方程为y={0}x*x+{1}x+{2}‘.format(a3,b3,c3)) 绘制购买折扣和推荐指数的回归散点图
plt.figure(figsize=(20,10)) #设置画布位置 plt.subplot(2,2,1) #设置样本曲线参数 plt.scatter(Y3, Y1, color="orange", label="样本曲线", lw=2) #设置拟合曲线参数 X1=np.linspace(0,100,100) Y1=a*X1*X1+b*X1+c plt.plot(X1,Y1, color="blue", lw=2, label="拟合曲线") #展示图像 plt.xlabel("购买折扣") plt.ylabel("推荐指数") plt.title("购买折扣和推荐指数的回归散点图") plt.legend() plt.show() #绘制购买折扣和购买价格的回归散点图 plt.figure(figsize=(20,10)) #设置画布位置 plt.subplot(2,2,2) #设置样本曲线参数 plt.scatter(Y3, Y2, color="c", label="样本曲线", lw=2) #设置拟合曲线参数 X1=np.linspace(0,100,100) Y1=a*X1*X1+b*X1+c plt.plot(X1, Y1, color="r", lw=2, label="拟合曲线") #展示图像 plt.xlabel("购买折扣") plt.ylabel("购买价格") plt.title("购买折扣和购买价格的回归散点图") plt.legend() plt.show()
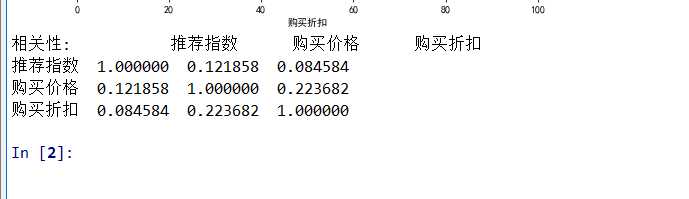
相关性计算 Corre=data.corr() print("相关性:",Corre)
完整代码
1 #导入第三方库 2 import numpy as np 3 import matplotlib.pyplot as plt 4 import matplotlib as mpl 5 from scipy.optimize import leastsq 6 import requests 7 from bs4 import BeautifulSoup 8 import pandas as pd 9 import csv 10 import jieba 11 import wordcloud 12 13 14 #网页结构 15 def constitute(soup): 16 #显示完整网页结构 17 print(soup.prettify()) 18 #查看网站的标题 19 print("所有的标题:",soup.select("title")) 20 #查看网站的id=link1后的所有兄弟节点标签 21 print("id=link1后的所有兄弟节点标签:",soup.select("body a")) 22 #查看a标签,其类属性为sister的标签 23 print("a标签,其类属性为sister的标签:",soup.select("#link1 ~.sister")) 24 #查看a标签中具有href属性的标签 25 print("a标签中具有href属性的标签:",soup.select(‘a[href]‘)) 26 #查看a标签中的父节点 27 print("a标签中的父节点:",soup.a.parent) 28 #查看p标签中的子节点 29 print("p标签中的子节点:",soup.p.children) 30 31 32 33 34 #数据采集 35 def data_collcation(soup,bookname,recommendindex,price,discount): 36 #发现在网页结构中书名保存在“class=”name“中,索引标签爬取信息 37 for i in soup.find_all(class_="name"): 38 bookname.append(i.get_text().strip()) 39 #发现在网页结构中推荐指数保存在“class=”tuijian“中,索引标签爬取信息 40 for j in soup.find_all(class_="tuijian"): 41 recommendindex.append(j.get_text().strip()) 42 #发现在网页结构中购买价格保存在“class=”price_r“中,索引标签爬取信息 43 for k in soup.find_all(class_="price_r"): 44 price.append(k.get_text().strip()) 45 #发现在网页结构中购买折扣保存在“class=”price_s“中,索引标签爬取信息 46 for l in soup.find_all(class_="price_s"): 47 discount.append(l.get_text().strip()) 48 49 50 51 52 #写入数据 53 def csv_fi(v): 54 #把文件转换成二维表 55 data=np.array(v.T) 56 csv_1=open("C:\python\\当当网新书排行榜数据.csv", 57 "w", 58 encoding="utf-8") 59 #把二维表写入CSV文件中 60 writer=csv.writer(csv_1) 61 for i in data: 62 writer.writerow(i) 63 #关闭文件 64 csv_1.close() 65 66 67 68 69 #数据清洗 70 def dataclear(): 71 data_2=pd.read_csv("C:\python\\当当网新书排行榜数据.csv", 72 names=["书名","推荐指数","购买价格","购买折扣"]) 73 #查看文件 74 print(data_2) 75 try: 76 #查找是否有空值 77 print(data_2.isnull().value_counts()) 78 #把空值都变为零 79 data_2.fillna(0) 80 except: 81 print("没有空值") 82 try: 83 #查看重复值 84 print(data_2.duplicated()) 85 #删除重复值 86 data_2.drop_duolicated() 87 except: 88 print("没有重复值") 89 try: 90 #查看异常值 91 print(data_2.describe()) 92 except: 93 print("无法查看异常值") 94 #再次查看数据 95 print(data_2) 96 #穿件空列表 97 recommendindex2=[] 98 price2=[] 99 discount2=[] 100 #删除“推荐指数”中不需要的文字 101 for i in data_2["推荐指数"]: 102 recommendindex=i.strip(‘%推荐‘) 103 recommendindex2.append(recommendindex) 104 #删除“购买价格”中不需要的符号 105 for j in data_2["购买价格"]: 106 price=j.strip(‘¥‘) 107 price2.append(price) 108 #删除“购买折扣”中不需要的文字 109 for k in data_2["购买折扣"]: 110 discount=k.strip(‘折‘) 111 discount2.append(discount) 112 bookname2=np.array(data_2["书名"]) 113 #整合新数据 114 newdata=[bookname2,recommendindex2,price2,discount2] 115 #设置数据标题 116 index2=["书名","推荐指数","购买价格","购买折扣"] 117 #把数据用DataFrame转变成一个二维列表 118 v2=pd.DataFrame(newdata,index2) 119 v3=v2.T 120 #打开创建好的文件 121 csv_2=open("C:\python\\当当网新书排行榜清洗数据.csv",122 "w",123 encoding="utf-8") 124 headers=["书名","推荐指数","购买价格","购买折扣"] 125 #把清洗好的数据写入CSV文档中 126 v3.to_csv(csv_2,127 header=headers,128 index=False,129 mode="a+") 130 #关闭文件 131 csv_2.close() 132 133 134 135 136 #把书名写入一个txt文档为了方便进行文档分析 137 def txt_new(bookname): 138 fi=open("C:\python\\当当网新书书名.txt",139 "w",140 encoding="utf-8") 141 #把书名一行行的写进文档中 142 for p in bookname: 143 fi.write("".join(p)+"\n") 144 #关闭文件 145 fi.close() 146 147 148 149 150 #文本分析 151 def cloud(): 152 #打开之前保存的文本txt 153 txt=open("C:\python\\当当网新书书名.txt","rb").read() 154 #解码 155 txt_1=txt.decode() 156 #把txt文本中的特殊符号换成空格 157 for ch in ‘:...()“”、?!?,‘: 158 txt_1=txt_1.replace(ch," ") 159 #对文本进行分词 160 txt_2=jieba.lcut(txt_1) 161 print(txt_2) 162 #设置词云的参数 163 w=wordcloud.WordCloud(width=1000,164 height=800,165 font_path="msyh.ttc",166 min_font_size=30,167 max_font_size=100,168 font_step=5,169 background_color="green") 170 #把文本的内容进行分词,并生成词云 171 w.generate(" ".join(txt_2)) 172 #保存到本地 173 w.to_file("C:\python\\当当网新书书名词云.png") 174 175 176 177 178 179 #数据可视化 180 def drawing(): 181 #打开清洗好的数据 182 data=pd.read_csv("C:\python\\当当网新书排行榜清洗数据.csv") 183 #读取数据 184 X=np.array(data.loc[:,"书名"]) 185 Y1=np.array(data.loc[:,"推荐指数"]) 186 Y2=np.array(data.loc[:,"购买价格"]) 187 Y3=np.array(data.loc[:,"购买折扣"]) 188 #设计画布的大小 189 plt.figure(figsize=(20,10)) 190 #设置画布的位置 191 plt.subplot(2,2,1) 192 #绘制“书名”和“推荐指数”的条形图 193 plt.barh(X,194 Y1,195 align="center",196 color="c") 197 #设置标题 198 plt.title("书名与推荐指数的关系") 199 #设置x轴的标题 200 plt.xlabel("推荐指数") 201 #设置y轴的标题 202 plt.ylabel("书名") 203 #展示条形图 204 plt.show() 205 #设置画布大小 206 plt.figure(figsize=(20,10)) 207 #设置画布位置 208 plt.subplot(2,2,2) 209 #绘制“书名”和“购买价格”的条形图 210 plt.barh(X,211 Y2,212 align="center",213 color="blue") 214 #设置总标题 215 plt.title("书名与购买价格的关系") 216 #设置x轴的标题 217 plt.xlabel("购买价格") 218 #设置y轴的标题 219 plt.ylabel("书名") 220 #展示条形图 221 plt.show() 222 #设置画布大小 223 plt.figure(figsize=(20,10)) 224 #设置画布位置 225 plt.subplot(2,1,2) 226 #绘制“书名”和“购买折扣”的条形图 227 plt.barh(X,228 Y3,229 align="center",230 color="orange") 231 #设置总标题 232 plt.title("书名与购买折扣的关系") 233 #设置x轴标题 234 plt.xlabel("购买折扣") 235 #设置y轴标题 236 plt.ylabel("书名") 237 #展示条形图 238 plt.show() 239 240 241 242 243 def Regressionanalysis(): 244 #打开清洗好的数据 245 data=pd.read_csv("C:\python\\当当网新书排行榜清洗数据.csv") 246 #读取数据 247 X=np.array(data.loc[:,"书名"]) 248 Y1=np.array(data.loc[:,"推荐指数"]) 249 Y1.sort() 250 Y2=np.array(data.loc[:,"购买价格"]) 251 Y2.sort() 252 Y3=np.array(data.loc[:,"购买折扣"]) 253 Y3.sort() 254 #设置计酸最小二乘法的函数 255 def fit_func(p,x): 256 a,b,c=p 257 return a*x*x+b*x+c 258 def error_func(p,x,y): 259 return fit_func(p,x)-y 260 #设置初始值 261 p0=[1,2,3] 262 #使用leastsq计算最小二乘法 263 para=leastsq(error_func,p0,args=(Y1,Y2)) 264 #描写回归方程 265 a,b,c=para[0] 266 print(‘推荐指数和购买价格的回归方程为y={0}x*x+{1}x+{2}‘.format(a,b,c)) 267 268 269 #设置初始值 270 p0_2=[1,2,3] 271 #使用leastsq计算最小二乘法 272 para_2=leastsq(error_func,p0_2,args=(Y2,Y3)) 273 #描写回归方程 274 a2,b2,c2=para_2[0] 275 print(‘购买价格和购买折扣的回归方程为y={0}x*x+{1}x+{2}‘.format(a2,b2,c2)) 276 #设置初始值 277 p0_3=[1,2,3] 278 #使用leastsq计算最小二乘法 279 para_3=leastsq(error_func,p0_3,args=(Y1,Y3)) 280 #描写回归方程 281 a3,b3,c3=para_3[0] 282 print(‘推荐指数和购买折扣的回归方程为y={0}x*x+{1}x+{2}‘.format(a3,b3,c3)) 283 284 285 #绘制购买折扣和推荐指数的回归散点图 286 plt.figure(figsize=(20,10)) 287 #设置画布位置 288 plt.subplot(2,2,1) 289 #设置样本曲线参数 290 plt.scatter(Y3,291 Y1,292 color="orange",293 label="样本曲线",294 lw=2) 295 #设置拟合曲线参数 296 X1=np.linspace(0,100,100) 297 Y1=a*X1*X1+b*X1+c 298 plt.plot(X1,Y1,299 color="blue",300 lw=2,301 label="拟合曲线") 302 #展示图像 303 plt.xlabel("购买折扣") 304 plt.ylabel("推荐指数") 305 plt.title("购买折扣和推荐指数的回归散点图") 306 plt.legend() 307 plt.show() 308 309 310 #绘制购买折扣和购买价格的回归散点图 311 plt.figure(figsize=(20,10)) 312 #设置画布位置 313 plt.subplot(2,2,2) 314 #设置样本曲线参数 315 plt.scatter(Y3,316 Y2,317 color="c",318 label="样本曲线",319 lw=2) 320 #设置拟合曲线参数 321 X1=np.linspace(0,100,100) 322 Y1=a*X1*X1+b*X1+c 323 plt.plot(X1,324 Y1,325 color="r",326 lw=2,327 label="拟合曲线") 328 #展示图像 329 plt.xlabel("购买折扣") 330 plt.ylabel("购买价格") 331 plt.title("购买折扣和购买价格的回归散点图") 332 plt.legend() 333 plt.show() 334 335 336 #相关性计算 337 Corre=data.corr() 338 print("相关性:",Corre) 339 340 341 342 343 #主程序 344 def main(): 345 #爬取的目的网站 346 url="http://bang.dangdang.com/books/newhotsales/01.00.00.00.00.00-recent7-0-0-1-1" 347 348 #获取网站 349 html=requests.get(url) 350 351 #读取网站文本信息 352 r=html.text 353 354 #把网站编程HTMLL结构 355 soup=BeautifulSoup(r,"lxml") 356 357 #查看网页结构 358 constitute(soup=soup) 359 360 #建立空列表,保存信息 361 bookname=[] 362 recommendindex=[] 363 price=[] 364 discount=[] 365 366 #采集数据 367 data_collcation(soup,bookname,recommendindex,price,discount) 368 369 #设置标题 370 index=["书名","推荐指数","购买价格","购买折扣"] 371 372 #整合数据 373 data=[bookname,recommendindex,price,discount] 374 375 #把数据变成一个二维列表 376 v=pd.DataFrame(data,index) 377 print(v.T) 378 379 #把采集的数据写入csv文件中 380 csv_fi(v) 381 382 #清洗数据并保存到一个新的csv文件 383 dataclear() 384 385 #把书名写入文档 386 txt_new(bookname) 387 388 #生成词云 389 cloud() 390 391 #设置matplotilb参数 392 plt.rcParams[‘axes.unicode_minus‘]=False 393 plt.rcParams[‘font.sans-serif‘]=[‘Microsoft YaHei‘] 394 mpl.rcParams["font.sans-serif"]=["SimHei"] 395 mpl.rcParams["axes.unicode_minus"]=False 396 397 #数据可视化 398 drawing() 399 400 #回归分析 401 Regressionanalysis() 402 403 404 405 406 #启动主程序 407 main()
四、结论
1.经过对主题数据的分析与可视化,可以得到哪些结论?
Python数据处理功能强大,掌握数据处理方法是很重要的。
2.对本次程序设计任务完成的情况做一个简单的小结。
此次程序有些不足,还需多加练习。
标签:draw comm 根据 child format array 列表 转变 特殊
原文地址:https://www.cnblogs.com/liutingfeng/p/12763214.html