标签:数据持久化 encoding 源代码 使用 tar ica port 持久 stat
一、主题式网络爬虫设计方案
1、主题式网络爬虫名称:爬取知乎热度数据并数据分析及可视化
2、爬取的内容:知乎热搜的标题、排行、热度
数据特征:随机、以文字和数字为主
3、实现思路:首先查看所要爬取页面的源代码,找到所需要爬取的数据在源代码中的位置,接下来进行数据爬取,并将爬取的数据持久化,保存在excel表格中用于使用,接下来对数据进行清洗处理,并进行数据分析额可视化
技术难点:正则表达式、回归方程
二、主题页面的结构特征分析
1、主题页面的结构和特征分析:所要爬取的热度数据在标签‘td’里面,标题在标签‘<a href> .... <a>’里面
2、页面解析:


三、
1、数据爬取与采集
import requests import re import pandas as pd import openpyxl import matplotlib import matplotlib.pyplot as plt import numpy as np import seaborn as sns from sklearn.linear_model import LinearRegression url = ‘https://tophub.today/n/mproPpoq6O‘ header = {‘user-agent‘:‘Mozilla/5.0‘} r = requests.get(url, headers=header) r.raise_for_status() r.encoding = r.apparent_encoding r.text html = r.text title = re.findall(‘<a href=.*? target="_blank" .*?>(.*?)</a>‘,html)[3:20] redu = re.findall(‘<td>(.*?)</td>‘,html)[0:17] print(title) print(redu) print(‘{:^55}‘.format(‘知乎热度榜单‘)) print(‘{:^5}\t{:^40}\t{:^10}‘.format(‘排名‘,‘标题‘,‘热度(单位:万)‘)) num = 8 lst = [] for i in range(num): print(‘{:^5}\t{:^40}\t{:^10}‘.format(i+1, title[i], redu[i][:-3])) lst.append([i+1, title[i], redu[i][:-3]]) df = pd.DataFrame(lst, columns=[‘排名‘,‘标题‘,‘热度(单位:万)‘]) df.to_excel(‘知乎热度榜.xlsx‘)
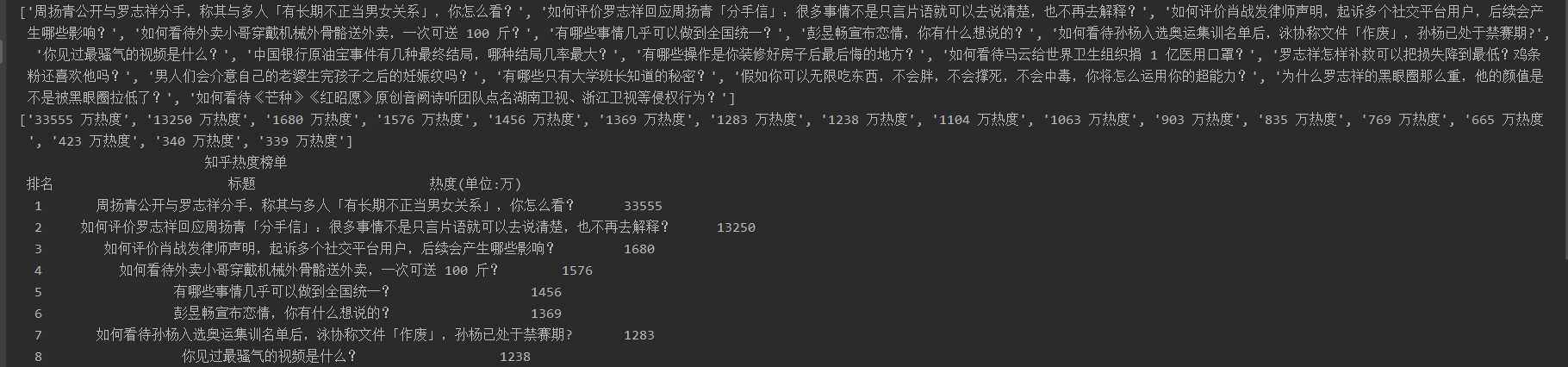
2、对数据进行清洗和处理
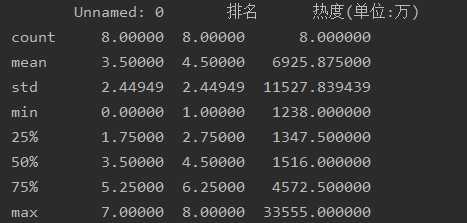
df = pd.DataFrame(pd.read_excel(‘知乎热度榜.xlsx‘)) print(df.head()) print(df.duplicated()) print(df[‘标题‘].isnull().value_counts()) print(df[‘热度(单位:万)‘].isnull().value_counts()) print(df.describe())


3、数据分析与可视化
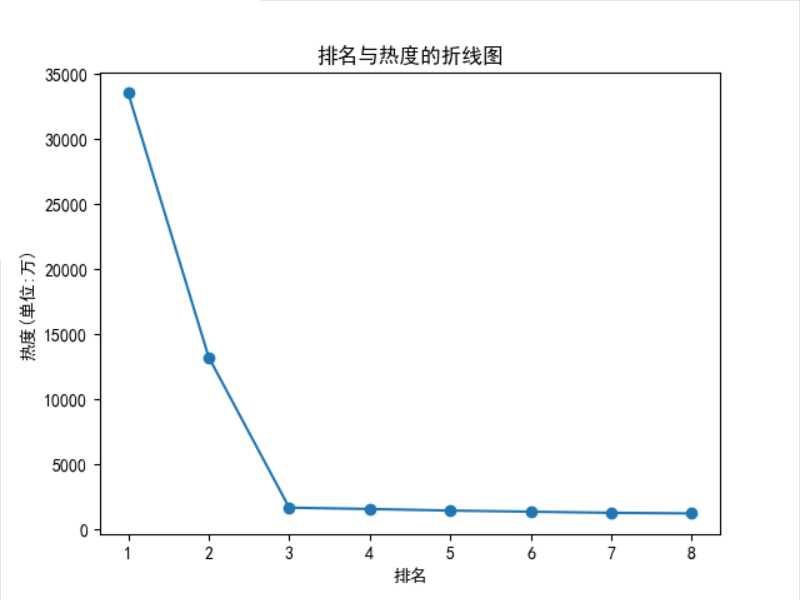
def zhexian(): plt.rcParams[‘font.sans-serif‘] = [‘SimHei‘] x = df[‘排名‘] y = df[‘热度(单位:万)‘] plt.xlabel(‘排名‘) plt.ylabel(‘热度(单位:万)‘) plt.plot(x,y) plt.scatter(x,y) plt.title(‘排名与热度的折线图‘) plt.show() zhexian() plt.rcParams[‘font.sans-serif‘] = [‘SimHei‘] plt.bar(range(1,9),redu[:8]) plt.xlabel(‘排名‘) plt.ylabel(‘热度(单位:万)‘) plt.title(‘排名与热度的柱状图‘) plt.show()
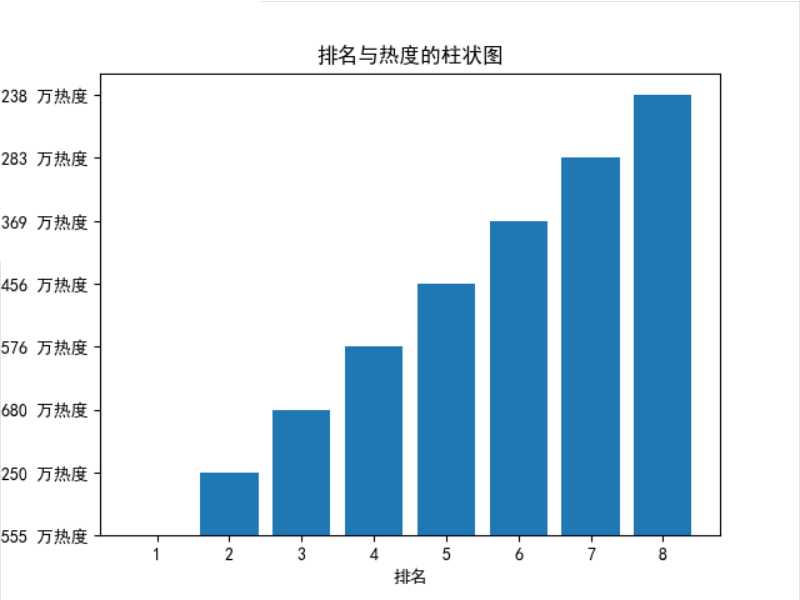
4、回归方程
df = pd.read_excel(‘知乎热度榜.xlsx‘) df.head(8) X = df.drop(‘标题‘,axis=1) predict_model = LinearRegression() predict_model.fit(X, df[‘热度(单位:万)‘]) print(‘回归系数:‘,predict_model.coef_)

5、数据持久化
df = pd.DataFrame(lst, columns=[‘排名‘,‘标题‘,‘热度(单位:万)‘]) df.to_excel(‘知乎热度榜.xlsx‘)
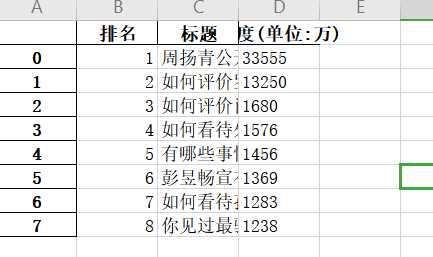
6、代码汇总
import requests import re import pandas as pd import openpyxl import matplotlib import matplotlib.pyplot as plt import numpy as np import seaborn as sns from sklearn.linear_model import LinearRegression url = ‘https://tophub.today/n/mproPpoq6O‘ header = {‘user-agent‘:‘Mozilla/5.0‘} r = requests.get(url, headers=header) r.raise_for_status() r.encoding = r.apparent_encoding r.text html = r.text title = re.findall(‘<a href=.*? target="_blank" .*?>(.*?)</a>‘,html)[3:20] redu = re.findall(‘<td>(.*?)</td>‘,html)[0:17] print(title) print(redu) print(‘{:^55}‘.format(‘知乎热度榜单‘)) print(‘{:^5}\t{:^40}\t{:^10}‘.format(‘排名‘,‘标题‘,‘热度(单位:万)‘)) num = 8 lst = [] for i in range(num): print(‘{:^5}\t{:^40}\t{:^10}‘.format(i+1, title[i], redu[i][:-3])) lst.append([i+1, title[i], redu[i][:-3]]) df = pd.DataFrame(lst, columns=[‘排名‘,‘标题‘,‘热度(单位:万)‘]) df.to_excel(‘知乎热度榜.xlsx‘) df = pd.DataFrame(pd.read_excel(‘知乎热度榜.xlsx‘)) print(df.head()) print(df.duplicated()) print(df[‘标题‘].isnull().value_counts()) print(df[‘热度(单位:万)‘].isnull().value_counts()) print(df.describe()) def zhexian(): plt.rcParams[‘font.sans-serif‘] = [‘SimHei‘] x = df[‘排名‘] y = df[‘热度(单位:万)‘] plt.xlabel(‘排名‘) plt.ylabel(‘热度(单位:万)‘) plt.plot(x,y) plt.scatter(x,y) plt.title(‘排名与热度的折线图‘) plt.show() zhexian() plt.rcParams[‘font.sans-serif‘] = [‘SimHei‘] plt.bar(range(1,9),redu[:8]) plt.xlabel(‘排名‘) plt.ylabel(‘热度(单位:万)‘) plt.title(‘排名与热度的柱状图‘) plt.show() df = pd.read_excel(‘知乎热度榜.xlsx‘) df.head(8) X = df.drop(‘标题‘,axis=1) predict_model = LinearRegression() predict_model.fit(X, df[‘热度(单位:万)‘]) print(‘回归系数:‘,predict_model.coef_)
四、结论
1、经过对知乎今日的热度标题进行爬取,今日第一和第二名的标题较为受关注,后面的标题较为平稳,相差不大
2、本次的程序设计的任务我完成的时间花了较长,遇到了挺多问题,但是经过百度搜索等等,最后将问题一步步解决,使得我对python更加的感兴趣了,完成任务之后非常的有成就感,正则表达式还不是很会,回归方程也遇到了问题,接下来的学习里,我会更加努力学习计算机这门课程。
标签:数据持久化 encoding 源代码 使用 tar ica port 持久 stat
原文地址:https://www.cnblogs.com/ZWq20000904/p/12763201.html