标签:format size import a* timeout fill 输出 mamicode com
一.主题式网络主题式网络爬虫设计方案
1.爬虫名称:爬取中国大学排名分析
2.爬虫爬取的内容:爬取最好大学网的排名表
3.网络爬虫设计方案概述:主题式网络爬虫设计方案概述:实现思路:选定想要爬取的网页,查看网页源码,找出标签,提取数据,并将数据存入Excel文件中;读取文件数据,对数据进行清洗和处理,进行数据分析与可视化,最后根据数据之间的关系,分析两个变量之间的相关系数,画出散点图及折线图和柱状图,建立回归方程。难点在于如何进行建立数据的回归方程。
二、主题页面的结构特征分析
1.主题页面的结构与特征分析:
三、网络爬虫程序设计
1.数据爬取与采集
1 import requests 2 from bs4 import BeautifulSoup 3 import bs4 4 5 def getHTMLText(url): #输入需要获取的url,输出url内容 6 try: 7 r = requests.get(url,timeout = 30) #获取url,信息延时30s 8 r.raise_for_status() #产生异常信息 9 r.encoding = r.apparent_encoding #修改编码 10 return r.text #将网页信息部分返回 11 except: #出现错误返回错误 12 return "错误" 13 14 def fillUnivList(ulist, html): #将页面内容放到一个列表中 15 soup = BeautifulSoup(html,"html.parser") #采用html解析器 16 for tr in soup.find(‘tbody‘).children: #使用遍历方法查找所需信息 17 if isinstance(tr,bs4.element.Tag): #过滤掉非标签类型 18 tds = tr(‘td‘) #将信息封装在tds列表中 19 ulist.append([tds[0].string,tds[1].string,tds[3].string]) 20 21 def printUnivList(ulist,num): #将列表中元素打印出来 22 tplt = "{0:^10}\t{1:{3}^10}\t{2:^10}" 23 print(tplt.format("排名","学校","总分",chr(12288))) 24 for i in range(num): 25 u = ulist[i] #打印表头 26 print(tplt.format(u[0],u[1],u[2],chr(12288))) 27 28 #整理数据 29 def zhenglilist(uinfo,leng,school,summ): 30 for i in uinfo: 31 leng.append(i[0]) 32 school.append(i[1]) 33 summ.append(i[2]) 34 35 def main(): 36 uinfo = [] 37 url = "http://www.zuihaodaxue.cn/zuihaodaxuepaiming2019.html" 38 html = getHTMLText(url) 39 fillUnivList(uinfo, html) 40 #print(uinfo) 41 printUnivList(uinfo,20) # 20 学校 42 43 #整理数据 44 leng=[] 45 school=[] 46 summ=[] 47 zhenglilist(uinfo,leng,school,summ) 48 49 file=pd.DataFrame({‘排名‘:leng,‘学校‘:school,‘总分‘:summ}) 50 file.to_excel(‘中国最好大学排名.xlsx‘) 51 52 main()
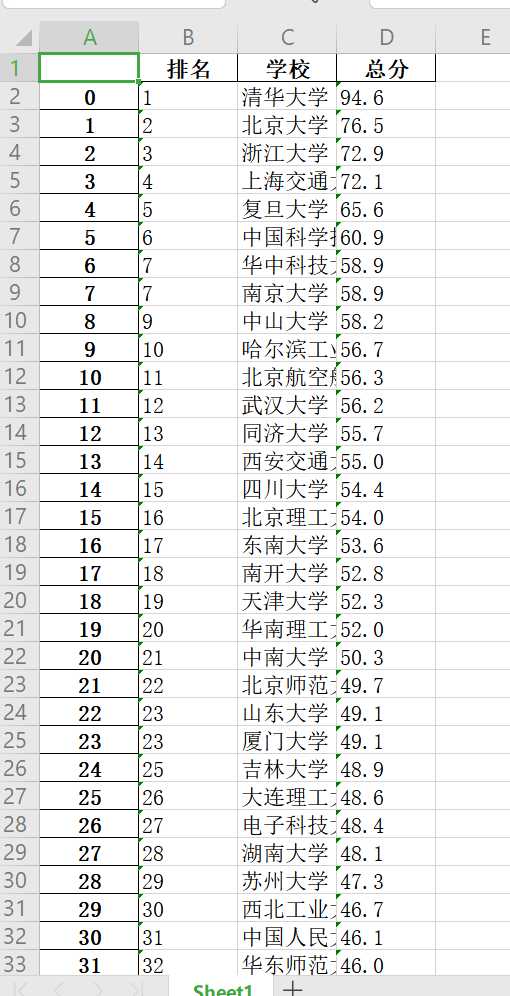
文件保存成功
2.对数据的处理
#数据可视化
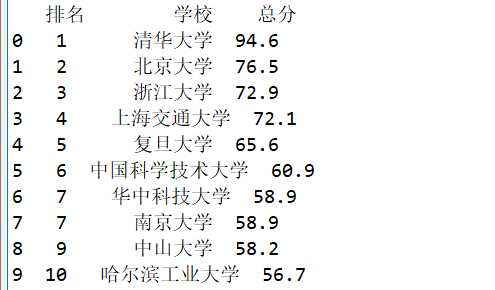
import pandas as pd df = pd.DataFrame(pd.read_excel(‘中国最好大学排名.xlsx‘)) print(df.head(10))
#查看相关的系数
df = pd.DataFrame(pd.read_excel(‘中国最好大学排名.xlsx‘)) print(df.corr())
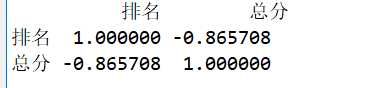
#异常值观察
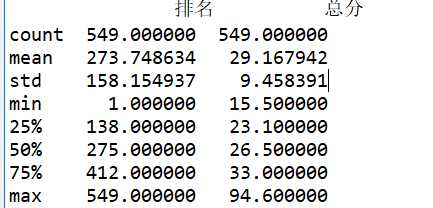
3.数据分析
#导入各库
import pandas as pd from matplotlib import pyplot as plt import seaborn as sns import numpy as np from scipy.optimize import leastsq
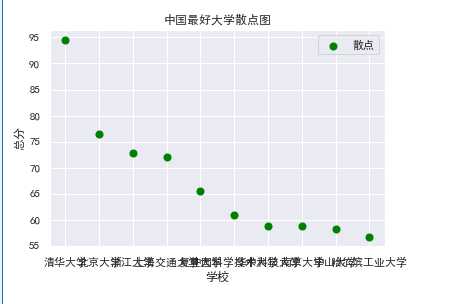
#散点图
def Sspot(): df = pd.DataFrame(pd.read_excel(‘中国最好大学排名.xlsx‘)) #赋予x,y所对应的值 x = df.学校[:10] y = df.总分[:10] plt.xlabel("学校") plt.ylabel("总分") plt.scatter(x,y,color="green",label="散点",s=50) plt.title("中国最好大学散点图") plt.legend() plt.show() Sspot()
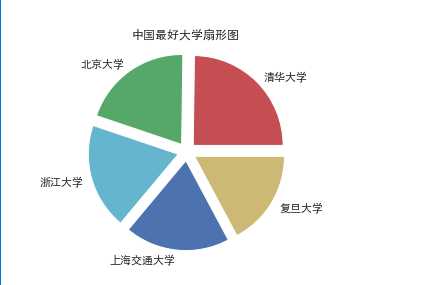
#扇形图
def Pspot(): df = pd.DataFrame(pd.read_excel(‘中国最好大学排名.xlsx‘)) x = df.学校 y = df.总分 #前五名的电影标题 name = [x[0],x[1],x[2],x[3],x[4]] math = [y[0],y[1],y[2],y[3],y[4]] explode=[0.1,0.1,0.1,0.1,0.1] plt.pie(math,labels=name,colors=["r","g","c","b","y"],explode=explode) plt.axis("equal") plt.title("中国最好大学扇形图") plt.show() Pspot()
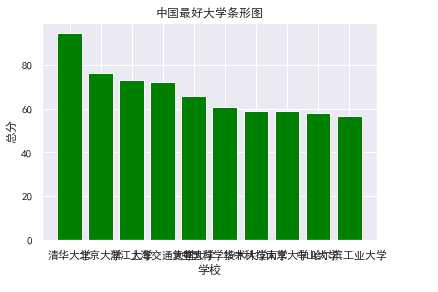
#条形图
def Tspot(): df = pd.DataFrame(pd.read_excel(‘中国最好大学排名.xlsx‘)) x = df.学校[:10] y = df.总分[:10] plt.xlabel("学校") plt.ylabel("总分") plt.bar(x,y,color="green") plt.title("中国最好大学条形图") plt.show() Tspot()
#折线图
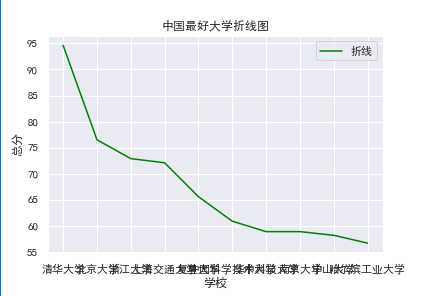
def Zspot(): df = pd.DataFrame(pd.read_excel(‘中国最好大学排名.xlsx‘)) x = df.学校[:10] y = df.总分[:10] plt.xlabel("学校") plt.ylabel("总分") plt.plot(x,y,color="green",label="折线") plt.title("中国最好大学折线图") plt.legend() plt.show() Zspot()
#回归图
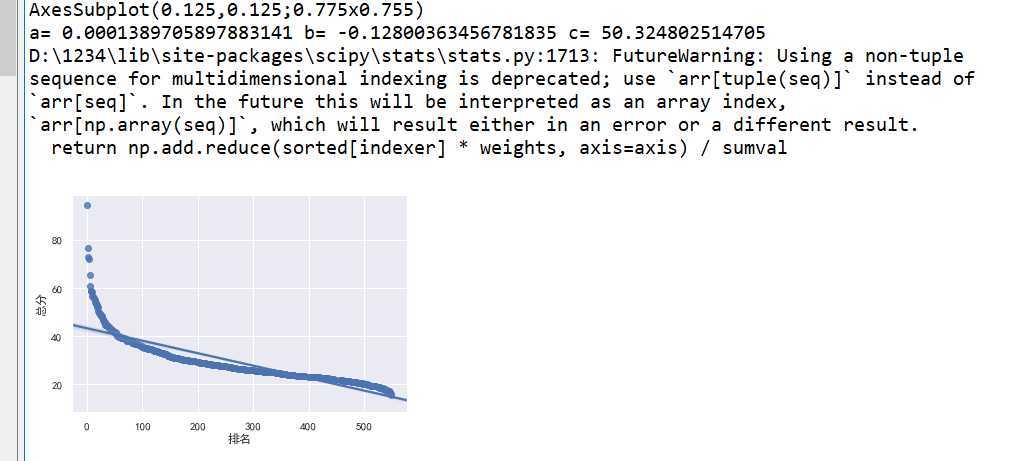
c=sns.regplot(x=‘排名‘,y=‘总分‘,data=df) print(c)
#回归方程
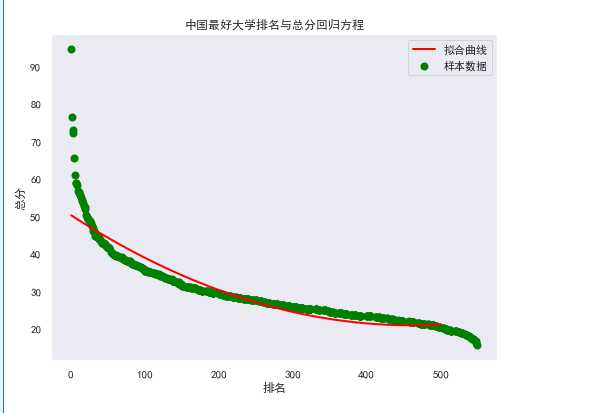
X=df.loc[:,‘排名‘] Y=df.loc[:,‘总分‘] def func(params,x): a,b,c=params return a*x*x+b*x+c def error_func(params,x,y): return func(params,x)-y P0=[1,94.6] def main(): plt.figure(figsize=(8,6)) P0=[1,94.6,1] Para=leastsq(error_func,P0,args=(X,Y)) a,b,c=Para[0] print("a=",a, "b=",b, "c=",c) plt.scatter(X,Y,color="green",label="样本数据",linewidth=2) x=np.linspace(1,500,40) y=a*x*x+b*x+c plt.plot(x,y,color="red",label="拟合曲线",linewidth=2) plt.xlabel(‘排名‘) plt.ylabel(‘总分‘) plt.title("中国最好大学排名与总分回归方程") plt.grid() plt.legend() plt.show() main()
4.代码汇总
import requests from bs4 import BeautifulSoup import bs4 import pandas as pd from matplotlib import pyplot as plt import seaborn as sns import numpy as np from scipy.optimize import leastsq def getHTMLText(url): #输入需要获取的url,输出url内容 try: r = requests.get(url,timeout = 30) #获取url,信息延时30s r.raise_for_status() #产生异常信息 r.encoding = r.apparent_encoding #修改编码 return r.text #将网页信息部分返回 except: #出现错误返回错误 return "错误" def fillUnivList(ulist, html): #将页面内容放到一个列表中 soup = BeautifulSoup(html,"html.parser") #采用html解析器 for tr in soup.find(‘tbody‘).children: #使用遍历方法查找所需信息 if isinstance(tr,bs4.element.Tag): #过滤掉非标签类型 tds = tr(‘td‘) #将信息封装在tds列表中 ulist.append([tds[0].string,tds[1].string,tds[3].string]) def printUnivList(ulist,num): #将列表中元素打印出来 tplt = "{0:^10}\t{1:{3}^10}\t{2:^10}" print(tplt.format("排名","学校","总分",chr(12288))) for i in range(num): u = ulist[i] #打印表头 print(tplt.format(u[0],u[1],u[2],chr(12288))) #整理数据 def zhenglilist(uinfo,leng,school,summ): for i in uinfo: leng.append(i[0]) school.append(i[1]) summ.append(i[2]) def main(): uinfo = [] url = "http://www.zuihaodaxue.cn/zuihaodaxuepaiming2019.html" html = getHTMLText(url) fillUnivList(uinfo, html) #print(uinfo) printUnivList(uinfo,20) # 20 学校 #整理数据 leng=[] school=[] summ=[] zhenglilist(uinfo,leng,school,summ) file=pd.DataFrame({‘排名‘:leng,‘学校‘:school,‘总分‘:summ}) file.to_excel(‘中国最好大学排名.xlsx‘) main() #数据可视化 df = pd.DataFrame(pd.read_excel(‘中国最好大学排名.xlsx‘)) print(df.head(10)) #异常值的观察 df = pd.DataFrame(pd.read_excel(‘中国最好大学排名.xlsx‘)) print(df.describe()) #查看相关系数 df = pd.DataFrame(pd.read_excel(‘中国最好大学排名.xlsx‘)) print(df.corr()) #散点图 def Sspot(): df = pd.DataFrame(pd.read_excel(‘中国最好大学排名.xlsx‘)) #赋予x,y所对应的值 x = df.学校[:10] y = df.总分[:10] plt.xlabel("学校") plt.ylabel("总分") plt.scatter(x,y,color="green",label="散点",s=50) plt.title("中国最好大学散点图") plt.legend() plt.show() Sspot() #绘制扇形图 def Pspot(): df = pd.DataFrame(pd.read_excel(‘中国最好大学排名.xlsx‘)) x = df.学校 y = df.总分 #前五名的电影标题 name = [x[0],x[1],x[2],x[3],x[4]] math = [y[0],y[1],y[2],y[3],y[4]] explode=[0.1,0.1,0.1,0.1,0.1] plt.pie(math,labels=name,colors=["r","g","c","b","y"],explode=explode) plt.axis("equal") plt.title("中国最好大学扇形图") plt.show() Pspot() #猫眼电影得分的条形图 def Tspot(): df = pd.DataFrame(pd.read_excel(‘中国最好大学排名.xlsx‘)) x = df.学校[:10] y = df.总分[:10] plt.xlabel("学校") plt.ylabel("总分") plt.bar(x,y,color="green") plt.title("中国最好大学条形图") plt.show() Tspot() #猫眼电影得分的折线图 def Zspot(): df = pd.DataFrame(pd.read_excel(‘中国最好大学排名.xlsx‘)) x = df.学校[:10] y = df.总分[:10] plt.xlabel("学校") plt.ylabel("总分") plt.plot(x,y,color="green",label="折线") plt.title("中国最好大学折线图") plt.legend() plt.show() Zspot() c=sns.regplot(x=‘排名‘,y=‘总分‘,data=df) print(c) X=df.loc[:,‘排名‘] Y=df.loc[:,‘总分‘] def func(params,x): a,b,c=params return a*x*x+b*x+c def error_func(params,x,y): return func(params,x)-y P0=[1,94.6] def main(): plt.figure(figsize=(8,6)) P0=[1,94.6,1] Para=leastsq(error_func,P0,args=(X,Y)) a,b,c=Para[0] print("a=",a, "b=",b, "c=",c) plt.scatter(X,Y,color="green",label="样本数据",linewidth=2) x=np.linspace(1,500,40) y=a*x*x+b*x+c plt.plot(x,y,color="red",label="拟合曲线",linewidth=2) plt.xlabel(‘排名‘) plt.ylabel(‘总分‘) plt.title("中国最好大学排名与总分回归方程") plt.grid() plt.legend() plt.show() main()
四、结论
1..经过对主题数据的分析与可视化,我们可以看出中国大学呈现两超多强的情况
2.小结:通过这次的程序设计任务,我深刻的认识到自己的不足,在过程中不断出错,通过不断回顾回看老师上课视频、百度搜索、看各类教学视频等方式不断解决了遇到的问题,也学会了很多东西,更提高了对python的兴趣。
标签:format size import a* timeout fill 输出 mamicode com
原文地址:https://www.cnblogs.com/mhcf/p/12763366.html