标签:postgres tab base cut 主机 丢失 clust post attach
接上回,备机在检测到主机挂掉后,备机通过standby promote成功升级为主机继续提供服务
此时集群状态如下:

接下来需要恢复原主机为备机加入集群继续提供服务
1、主机执行node rejoin,将节点重新加入集群:
./repmgr node rejoin -h192.168.101.7 -Upostgres -dpostgres
[postgres@localhost bin]$ ./repmgr node rejoin -h192.168.101.7 -Upostgres -dpostgres ERROR: this node cannot attach to rejoin target node 2 DETAIL: rejoin target server‘s timeline 2 forked off current database system timeline 1 before current recovery point 0/8000028 HINT: use --force-rewind to execute pg_rewind
报错日志可以看出,此时的节点和现在的主节点日志发生了分歧,需要调用--force-rewind重做备机,执行如下命令即可
./repmgr node rejoin -h192.168.101.7 -Upostgres -dpostgres --force-rewind
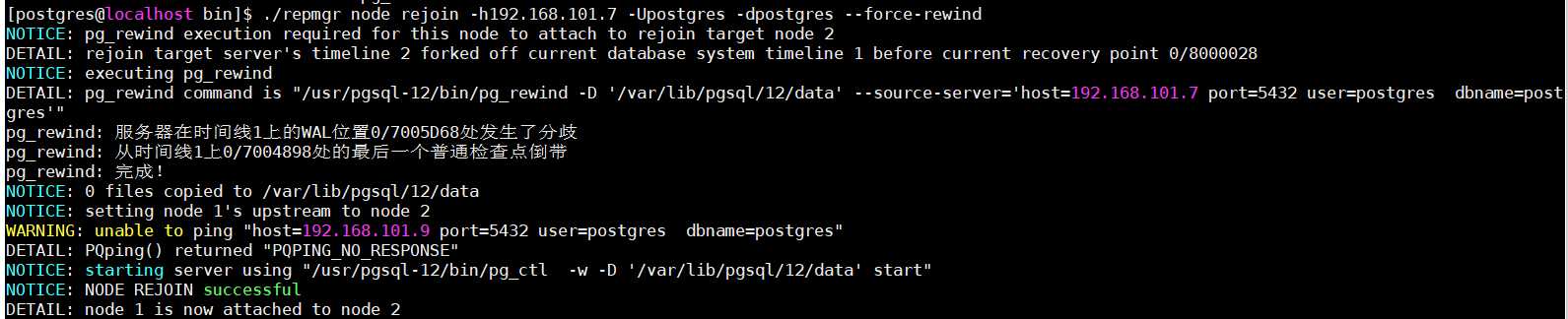
检查节点状态,可知原主机成功作为备机加入集群提供服务
./repmgr cluster show

ps:调用pg_rewind重做备机有丢失原主机数据风险,需要注意。
标签:postgres tab base cut 主机 丢失 clust post attach
原文地址:https://www.cnblogs.com/mingfan/p/12773509.html