标签:利用 proc 字典 roc mamicode elements ping ppi sea
Google的论文,
Google已经有一些大数据系统,都是基于Full Scan
这里PowerDrill,核心利用了skipping技术,可以提升10到100倍的查询性能

这篇论文的题目让人有点摸不着头脑,这里给出了解释,

整体的思路,
就是先skip,然后再full scan

那么就是,他这里的skip技术,如何不同,
他设计了一种基于字典的索引结构,索引结构是基于每个column的
比如对于,search_string,有三个部分,
Global Dictionary,global-id和search string的对应关系;全局字典便于查找,真正的string只需要存一遍
Chunk Dictionary,global-id和chunk-id的对应关系;global-id可能会比较大,chunk-id局部比较小,和节省空间
Elements,每个element替换成对应的chunk-id
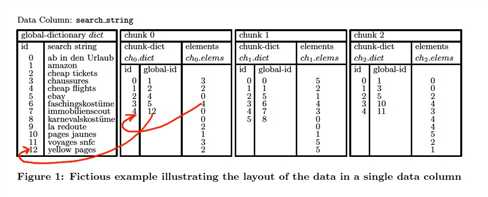
比如,对于下面的SQL,

我们发现,la redoute和voyages sncf对应的global id为,9,11
首先扫描所有的,chunk dictionary,发现9没有,11仅在chunk2中出现,
那么自然chunk 0,1就被skipping掉了
论文后续主要是实验和如何优化这个结构,有兴趣的看原文
Processing a Trillion Cells per Mouse Click
标签:利用 proc 字典 roc mamicode elements ping ppi sea
原文地址:https://www.cnblogs.com/fxjwind/p/12778688.html