标签:分析 tail perm inter graph disabled 思路 很多 资源
一.信息安全模型
1.信息安全模型,具体特点:
1)是精确的,无歧义的
2)简单的,抽象的,易于理解的
3)涉及安全性质,不过分限制系统的功能与实现
2.访问控制模型分类
1)自主访问控制模型(DAC)
linux下对于文件、文件夹的rwx权限控制,windows下的文件、文件夹的权限控制均属于自主访问控制。
特点是权限是由主体来控制。
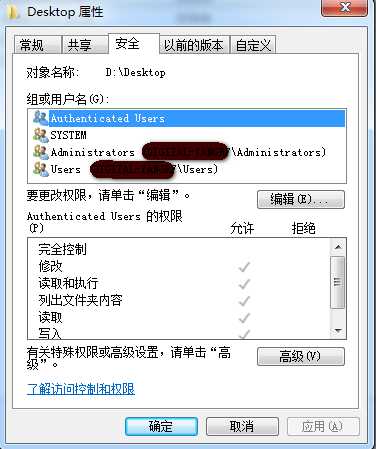
(1)在windows的权限控制
右击文件、文件夹选择[属性]功能,进入[属性]界面选择[安全]功能
(2)linux 的权限
在bash下执行 ls -l查看文件的所属者、所属组、其他组的权限
-rw-rw-rw- 1 root root 0 Sep 22 13:14 access
2)强制访问控制模型(MAC)
主体、客体都会个标签,根据标签的关系确定访问控制,一般由客体控制。
BLP和Biba模型都属于强制访问控制(MAC)模型。其中,BLP用于保护数据机密性,而Biba则针对完整性。
随之而后的是Clark-Wilson模型。
3)基于角色的访问控制模型(RBAC)
4)基于属性的访问控制模型(ABAC )
ABAC通常使用配置文件(XML 、YAML)或DSL配合规则解析来使用。其中XACML(eXtensilde Access contorl markup Language)是其中的一种实现方式。
ABAC 有时候也被成为PBAC(Policy-Based Access Control)或CBAC(Claims-Based Access Control)
关于访问控制类型具体要素在此不过多阐述,下一篇文章会对这些访问控制模型进行详细介绍。
3.状态机模型的概念
状态机模型(State Machine Model):安全的状态机模型是其他安全模型的基础,描述了一种无论处于何种状态都是安全的系统。
状态(State)是处于特定时刻系统的一个快照,如果该状态所有方面都满足安全策略的要求,就称之为安全的。
状态机可归纳为4个要素:现态、条件、动作、次态
这样的归纳,主要是出于对状态机的内在因果关系的考虑
“现态”和“条件”是因
"动作"和"次态"是果
状态转换/迁移:许多活动可能会改变系统状态,状态迁移总是导致新的状态的出现
如果所有的行为都在系统中允许并且不危及系统使之处于不安全状态,则系统执行一个安全状态机模型:secure state model
一个安全的状态机模型系统,总是从一个安全状态启动,并且在所有迁移当中保持安全状态,只允许主体以和安全策略相一致的安全方式来访问资源。
基于状态(主体、客体)进行控制,始终监控访问状态
4.关于访问控制模型的胡言乱语
将访问控制模型和信息安全模型放在一起有些蒙,甚至有的时候会将访问控制模型和信息安全模型会进行混淆。笔者的理解是访问控制是具体抽象类别,而信息安全模型是具体满足某一方向要求(机密性、完整性)的具体实现理论方法。
在此提一下最具比较火的概念:零信任。实际上将零信任归类为一种新型的信息安全模型有些不太合适,其更多是一种方法的集合,是一种新的解决方案思路。
零信任最大的核心是以身份为中心,所有过程均加密,应用系统互相认证等等,充分利用了RBAC+ABAC,通过多方因素、多个角度判断主体、客体的合法性。符合信息安全领域的发展趋势,在安全领域当你判断的因素越多,误判的可能性就越低,发现违规/威胁行为就会越早,安全系数也就越高。具体关于零信任网络体系在国内已经有一些案例落地,以奇安信、腾讯等厂商为主要力量在推动零信任生态的发展。国外最早的要属Google BenyondCory.
5.关于selinux
为什么要单独提下selinux呢。因为大家常碰到,而不常用,但又和前文提到MAC、状态机最直观的表现。
相信在各种关于linux环境下的各种配置手册、教程等等均会提到selinux,无一例外的都是提怎么关闭。为什么呢,因为不关闭好多配置执行就会有问题,那为什么没有一个说怎么配置呢?因为其足够的复杂。
以下简单对selinux进行介绍,使读者有个初步的概念,后续在根据自我学习的情况再分享给大家心得(第一次认真的搜索了下selinux的配置,而不是如何关闭,真的足够的的强大,也足够的复杂。同时笔者思考,在当前网络安全的态势下,采用selinux+iptables可能是未来加强linux操作自身不错的一个选择。)
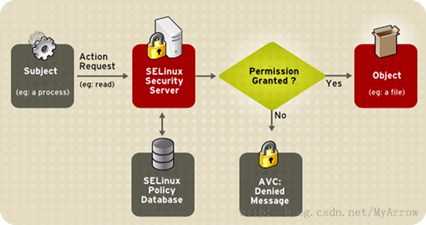
selinux就是linux的一种MAC类型的访问控制,目前已经集成到内核中,会被默认按照和启用。其对进程、用户、文件进行联合访问控制操作,是状态机模型。
selinux决策过程如下图所示:
SELinux 提供 3 种不同的策略可供选择,分别是 Targeted、MLS(Multi-Level Security) 以及 MiNimum。每个策略分别实现了可满足不同需求的访问控制。
1)Target策略:主要对系统中的服务进程进访问控制,同时,它还可以限制其他进程和用户。服务进程都被放入沙盒,在此环境中,服务进程会被严格限制,以便使通过此类进程所引发的恶意攻击不会影响到其他服务或 Linux 系统。
2)MLS 策略 :是 Multi-Level Security 的缩写,该策略会对系统中的所有进程进行控制。启用 MLS 之后,用户即便执行最简单的指令(如 ls),都会报错。
3)Minimum:策略 Minimum 策略的意思是“最小限制”,该策略最初是针对低内存计算机或者设备(比如智能手机)而创建的。
从本质上来说,Minimun 和 Target 类似,不同之处在于,它仅使用基本的策略规则包。对于低内存设备来说,Minumun 策略允许 SELinux 在不消耗过多资源的情况下运行。
selinux的配置文件为/etc/selinux/config
# This file controls the state of SELinux on the system.
# SELINUX= can take one of these three values: 配置selinux的模式
#enforcing - SELinux security policy is enforced.
#permissive - SELinux prints warnings instead of enforcing.
#disabled - No SELinux policy is loaded.
SELINUX=disabled
# SELINUXTYPE= can take one of three values: 配置selinux的类型
#targeted - Targeted processes are protected,
# minimum - Modification of targeted policy. Only selected processes are protected.
#mls - Multi Level Security protection.
SELINUXTYPE=targeted
二.常见信息安全模型
1.Bell-lapadula 贝尔拉普杜拉模型
Bell-lapadula模型(简称BLP)是20世纪70年代,美国军方提出的用于解决分时系统的信息安全和保密问题,该模型主要用于防止保密信息被未授权的主体访问。即机密性问题。
1.1.BLP模型特点
BLP属于强制访问控制模型,用于在政府和军事应用中实施访问控制。BLP当初设计出来用于规范美国国防部的多级安全 (MLS) 策略。
BLP是对安全策略形式化的第一个数学模型(相当严谨的、无歧义的),是一个状态机模型,用状态变量表示系统的安全状态,用状态转换规则来描述系统的变化过程。
Bell-lapadula模型的系统会对系统的用户(主体)和数据(客体)做相应的安全标记,因此这种系统又被称为多级安全系统,级别和模型用于限制主体对客体的访问操作,该模型用于加强访问控制的信息保密性。
Bell-lapadula使用主体,客体,访问操作(读,写,读/写)以及安全级别这些概念,当主体和客体位于不同的安全级别时,主体对客体就存在一定的访问限制。实现该模型后,它能保证信息不被不安全的主体所访问。
BLP: Bell-La Padula Model,即“no read up, no write down”,如下图所示:
以下仅摘抄部分模型的定义:
1)模型的基本元素
模型定义了如下的集合:
S={s1,s2,…,sn} 主体的集合,主体:用户或代表用户的进程,能使信息流动的实体。
O={o1,o2,…,om} 客体的集合,客体:文件、程序、存贮器段等。(主体也看作客体S O)
C={c1,c2,…,cq} 主体或客体的密级(元素之间呈全序关系),c1≤c2≤…≤cq.
K={k1,k2,…,kr} 部门或类别的集合
A={r,w,e,a,c} 访问属性集,其中,r:只读;w:读写;e:执行;a:添加(只写);c:控制。
RA={g,r,c,d} 请求元素集
g:get(得到),give(赋予)
r:release(释放),rescind(撤销)
c:change(改变客体的安全级),create(创建客体)
d:delete(删除客体)
D={yes,no,error,?} 判断集(结果集),其中
yes:请求被执行;
no: 请求被拒绝;
error:系统出错,有多个规则适合于这一请求;
?: 请求出错,规则不适用于这一请求。
μ={M1,M2,…,Mp} 访问矩阵集,其中元素Mk是一n×m的矩阵,Mk的元素Mij A。
F=CS×CO×(PK)S×(PK)O,其中,
CS={f1|f1:S→C} f1给出每一主体的密级;
CO={f2|f2:O→C} f2给出每一客体的密级;
(PK)S={f3|f3:S→PK} f3给出每一主体的部门集;
(PK)O={f4|f4:O→PK} f4给出每一客体的部门集。
其中,PK表示K的幂集(PK=2K)。
F的元素记作f=(f1,f2,f3,f4),给出在某状态下每一主体的密级和部门集,每一客体的密级和部门集,即主体的许可证级(f1,f3),客体的安全级(f2,f4)。
2)系统状态
V=P(S×O×A)×μ×F是状态的集合,状态v=(b,M,f)用有序三元组表示,其中
b S×O×A,是当前访问集。
M是访问矩阵,它的第i行,第j列的元素Mij A表示在当前状态下,主体Si对客体Oj所拥有的访问权限。
f=(f1,f2,f3,f4),其中,f1(s)和f3(s)分别表示主体s的密级和部门集,f2(s)和f4(s)分别表示客体O的密级和部门集。
3)安全特性
(1)自主安全性
状态v=(b,M,f)满足自主安全性,当且仅当对所有的(si,oj,x)∈b,有x∈Mij。
(2)简单安全性
状态v=(b,M,f)满足简单安全性,当且仅当对所有的(s,o,x)∈b,有
(i)x=e或x=a或x=c
或(ii) (x=r或x=w)且(f1(s)≥f2(o),f3(s) f4(o))。
1.2BLP模型的三项规则
Bell-lapadula有三条强制的访问规则:
- 简单安全规则(simple security rule):表示低安全级别的主体不能从高安全级别客体读取数据。
- 星属性安全规则(star property):表示高安全级别的主体不能对低安全级别的客体写数据。
- 强星属性安全规则(strong star property):表示一个主体可以对相同安全级别的客体进行读和写操作。
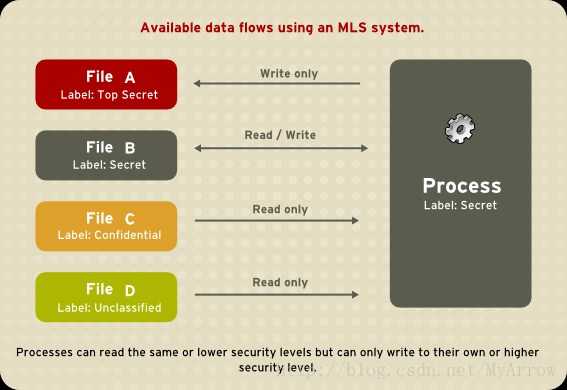
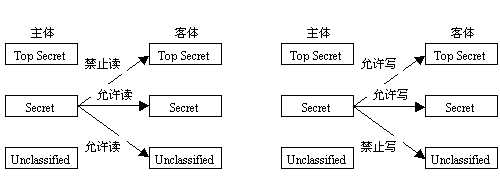
所有的MAC系统都是基于Bell-lapadula模型,因为它允许在代码里面整合多级安全规则,主体和客体会被设置安全级别,当主体试图访问一个客体,系统比较主体和客体的安全级别,然后在模型里检查操作是否合法和安全。下图是对bell-lapadula模型的简要描述:
1)当安全级别为Secret的主体访问安全级别为Top Secret的客体时,简单安全规则(simple security rule)生效,此时主体对客体可写不可读(no read up);
对上能提供数据,但不能对上获取数据。(保证高密级的机密性)
2) 当安全级别为Secret的主体访问安全级别为Secret的客体时,强星属性安全规则(strong star property)生效,此时主体对客体可写可读;
同级可读可写(同级认为是被信任)
3) 当安全级别为Secret的主体访问安全级别为unclassfied的客体时,星属性安全规则( star property)生效,此时主体对客体可读不可写(no write down);
对下获取下级的数据,不能为下级提供数据(避免数据非法泄露)
在BLP模型中,用户只能在其自己的安全级别或更高的安全级别上创建内容(如,秘密研究人员可以创建秘密或绝密文件,但不能创建公共文件;不能下写)。相反,用户只能查看在其自己的安全级别或更低的安全级别的内容(如,秘密研究人员可以查看公共或秘密文件,但不能查看绝密文件;不能上读)。
该安全模型针对访问控制,并被描述为:“下读,上写”。 信息自下而上流入。
1.3BLP模型的优缺点
BLP模型是最早的一种安全模型,也是最有名的多级安全策略模型。它给出了军事安全策略的一种数学描述,用计算机可实现的方式定义。
它已为许多操作系统所使用。
实现了允许低密高流入,禁止高密向低密流出。
优点:
①是一个最早地对多级安全策略进行描述的模型;
②是一个严格形式化的模型,并给出了形式化的证明;
③是一个很安全的模型,既有自主访问控制,又有强制访问控制。
④控制信息只能由低向高流动,能满足军事部门等一类对数据保密性要求特别高的机构的需求。
总的来说,BLP模型“过于安全”。
①上级对下级发文受到限制;
②部门之间信息的横向流动被禁止;
③缺乏灵活、安全的授权机制。
不安全的地方:
①低安全级的信息向高安全级流动,可能破坏高安全客体中数据完整性,被病毒和黑客利用。
②只要信息由低向高流动即合法(高读低),不管工作是否有需求,这不符合最小特权原则。
③高级别的信息大多是由低级别的信息通过组装而成的,要解决推理控制的问题。
2.Biba
Biba模型是在bell-lapadula模型之后开发的,它跟bell-lapadula模型很相似,被用于解决应用程序数据的完整性问题。Bell-lapadula使用安全级别(top secret,secret,sensitive,等),这些安全级别用于保证敏感信息只被授权的个体所访问。Biba模型不关心信息保密性的安全级别,因此它的访问控制不是建立在安全级别上,而是建立在完整性级别上。
Biba模型能够防止数据从低完整性级别流向高完整性级别,跟Bell-lapadula一样,Biba模型也有三条规则提供这种保护:
- 星完整性规则(*-integrity axiom):表示完整性级别低的主体不能对完整性级别高的客体写数据
- 简单完整性规则(simple integrity axiom):表示完整性级别高的主体不能从完整性级别低的客体读取数据
- 恳求属性规则(invocation property):表示一个完整性级别低的主体不能从级别高的客体调用程序或服务。
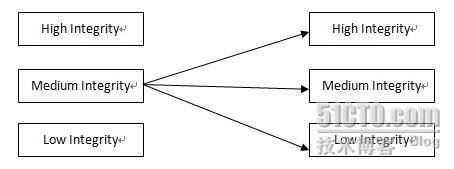
下图是对Biba模型的简要描述:
Subject(主体) Object(客体)
1) 当完整性级别为Medium Integrity的主体访问完整性级别为High Integrity的客体时,星完整性规则(*-integrity axiom)和恳求完整性规则(invocation property)生效,此时主体对客体可读不可写(no write up),也不能调用主体的任何程序和服务;
对上获取数据,但不能对上提供数据(低完整性不影响高完整性)
2)当完整性级别为Medium Integrity的主体访问完整性级别为Medium Integrity的客体时,此时主体对客体可写可读;
同级可读可写。
3)当完整性级别为Medium Integrity的主体访问完整性级别为Low Integrity的客体时,简单完整性规则(simple integrity axiom)生效,此时主体对客体可写不可读(no read down);
对下能提供数据,但不能读取数据(通过读低完整性级别的数据会影响高完整性级别的数据)
模型特点总结:解决完整性问题。能上读,不能上写(低完整性的数据会破坏高完整性的数据,可以看高完整性的数据),能下写,不能下读(避免读取了低完整性数据,而破坏高完整性的数据)
3.Clark-wilson模型
Clark-Wilson模型简称CWM,是Biba模型之后开发的,专为商用设计,保护信息的完整性,其核心目的是为了防止合法用户做非法操作。
完整性的目标是防止未授权的用户进行修改,防止授权用户进行不正确的修改,维护内部和外部的一致性。数据的完整性是指,如果数据满足给定的条件,则称数据处于一个一致性状态,在每次操作前和操作后,数据都必须满足这个一致性条件。系统的一个事务处理就是一系列操作,使系统从一个一致性状态转移到另一个一致性状态。数据操作的完整性是指,需要有人检查和验证事务处理是否被正确执行,一个事务需要两个或两个以上的不同的人来执行,如果要使用一个事务处理来破坏数据,必须有两个不同的人员犯错,或者他们合谋担保该事务处理已被正确实现。(职责分离)
Clark-Wilson模型将数据划分为两类:限制数据项(Cons
trained Data Items,CDI)和非限制数据项( Unconstrainecl Data
Items,UDI),CDI是需要进行完整性控制的客体,而UDI 则不需要进行完整性控制。
Clark-Wilson模型定义了两种过程,一个是完整性验证过程(Integrity Verification Procedure,IVP),确认限制数据项处于一种有效状态,如果IVP检验CDI符合完整性约束,则称系统处于一个有效状态;另一个是转换过程( Transformation Procedure,TP),将数据项从一种有效状态改变至另一种有效状态。
为了达到并保持完整性,Clark-Wilson模型提出了证明规则和实施规则,证明规则由管理员来执行,实施规则是由系统执行。
过程:
1)对CDI进行操作的过程称之为变换过程TP(Transformation Procedures)
2)为了确保对CDI的TP是有效的,则需要授权User做TP的认证
3)为了防止合法用户对CDI做非法或错误操作,将TP过程分为多个子过程,将每个子过程授权给不同的User
4)但是如果TP的每个子过程被授权的User之间存在某种利益同盟,则可能存在欺骗,从而使得CDI的完整性得不到保护
模型特点总结:对于网络上阐述CW模型的具体内容不多,至少笔者目前没有找到,由于英文水平有限,也没有去查看英文材料。通过对于网络上的材料总结,笔者认为:CW模型设计的初衷是为了实现防止非授权访问设置了CDI和UDI,为了避免出现授权用户的非法访问设置了TP(职责分离)。当用户需要访问受保护的数据项(CDI)时,不是直接访问,需要使用TP代理来访问(保护数据后端),通过职责分离(事务处理、检查和验证分别由不同的人完成)提高由于授权用户对非授权内容操作的可能性。
4.Chinese-Wall 模型
Chinese Wall模型由Brewer和Nash提出,是一种同等考虑保密性和完整性的访问控制模型,主要用于解决商业应用中的利益冲突问题,它在商业领域的应用与BLP模型在军事领域的作用相当。
与BLP模型不同的是,访问数据不是受限于数据的属性(密级),而是受限于主体已经获得了对哪些数据的访问权限。Chinese Wall模型的主要设计思想是将一些有可能会产生访问冲突的数据分成不同的数据集,并强制所有主体最多只能访问一个数据集,而选择访问哪个数据集并未受强制规则的限制。
- 主体只有在不能读取位于不同数据集内的某个客体时才能写另一个客体
- 提供根据用户先前的活动而动态改变访问控制
- 防止用户访问被认为有利益冲突的数据
- 同一时间只能读取一个数据
在Chinese Wall模型中,客体分为无害客体和有害客体两种,其中,无害客体为可以公开的数据,有害客体为会产生利益冲突,需要限制的数据。
Chinese Wall模型有两种安全特性,分别是CW-简单安全特性和CW-*-特性。
CW-简单安全特性:S能读取O,当且仅当以下任一条件满足:
(1)存在一个0,它是S曾经访问过的客体,并且CD(O’)=CD(0);
(2)对于所有的客体0’,0’∈PR(S),则COI(0’)≠COI (O);
(3)0是无害客体。
假设系统中保存了银行-A、石油公司-A和石油公司-B的信息,一个新用户可以自由选择访问三个公司数据集之一。在计算机系统中,一个不拥有任何信息的新用户不会存在任何冲突。
假设这个新用户首先访问了石油公司-A的数据集,则该用户目前拥有了石油公司-A的信息。稍后,该用户请求访问银行-A的数据集,由于银行-A和石油公司-A分属于不同的利益冲突组,所以不会发生冲突,故被允许访问。但是,如果请求访问石油公司-B的数据集,
将会被拒绝,因为两个石油公司的数据集是冲突的。
注意,用户访问银行-A与访问石油公司-A数据集的顺序无关,而访问石油公司-A与石油公司-B数据集的顺序将会导致结果的不同。在该例中,当用户拥有“石油公司-B”,“银行-A”)时,则访问石油公司-A的请求将被拒绝,相反地,当用户拥有“石油公司-A”, “银行-A”l时,则访问石油公司-B的请求将被拒绝。
在第一次选择时,用户完成了对所喜爱的信息的自由访问。于是围绕着该用户所拥有信息的Chinese Wall已经建成,可以认为在墙外的任何数据集均与墙内的数据集同属于一个利益冲突组。这时,用户仍然可以自由访问那些与墙内信息分属于不同利益冲突组的信息,但是选择一旦做出,Chinese Wall会立即针对新的数据集修改形状。可以看出,Chinese Wall 的安全策略是一种自由选择与强制控制的绝妙组合。
综上所述,如果被访问的客体属于以下两种情况,访问将可以进行:与主体曾经访问过的信息属于同一个公司数据集,即在墙内的信息;属于一个完全不同的利益冲突组。
有时,在同一个利用冲突组中的公司数据集之间,会出现间接信息流。例如,有两个用户User-A和User-B,User-A访问了银行-A和石油公司-A的信息,而User-B访问了银行-A和石油公司-B的信息。如果User-A从石油公司-A中读取数据并写入银行-A中,则User-B便能够读取石油公司-A的数据。由于石油公司-A和石油公司-B同属于一个兴趣冲突组,所以,这种情况是不允许发生的。以上操作的结果已经间接破坏了Chinese Wall的安全策略。为了防止以上情况的出现,CW-*-特性对写访问作如下规定:
CW-*一特性:S能写0,当且仅当以下任两个条件同时满足:
(1) CW-简单安全特性允许S读O;
(2)对于所有有害客体O’,S能读取0’,则CD (O’ )=CD(0)。
Chinese Wall模型通常用于证券交易或者投资公司的经济活动等应中,其目的是为了防止利益冲突的发生,如,交易员代理两个客户投资,并且这两个客户的利益相互冲突,利用该模型的安全策略,可以防止交易员为了帮助其中一个客户盈利,而导致另一个客户损失。
5.无干扰模型(noninterference)
干扰模型将系统的安全需求描述成一系列主体问操作互不影响的断言,要求在不同存储域中操作的主体能够防止由于违反系统的安全性质导致的相互间的影响,如要求高安全级的操作不干扰低安全级主体的活动。
目的是处理隐蔽通道,解决在同一环境下,资源共享带来产生隐蔽通道的问题。保护较高级别的隐私,上下互不干扰,也无法猜测
6.格子模型(lattice-based access control model )
晶格的访问控制,也是强制访问控制,具有最小上线和最大下线的机组元素的访问控制类型。
用格的结点表示与访问对象相关的访问权限,访问权限的变化映射在格上成为一个结点到另一个结点的变换,在模型中,实现了访问控制策略实时更新,加强了并发控制环境中系统的安全性,为保证访问控制策略更新的合法性,建立了访问权限与授权级别相结合的复合格,可按权限级别进行访问权限控制,在并发环境中,多个主体读写数据和修改访问控制策略并互相影响时,可直接应用该的模型与算法。
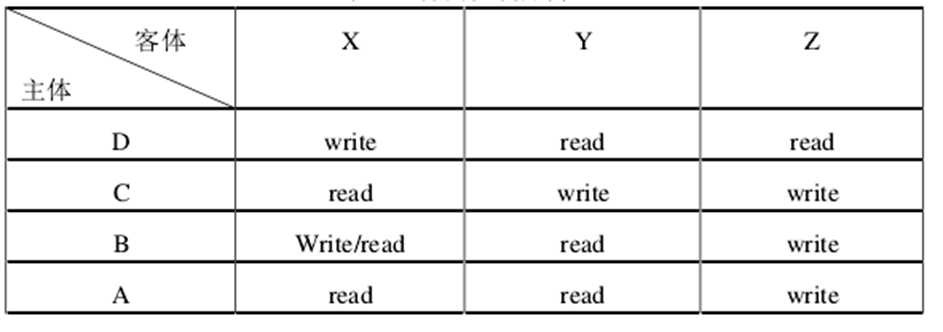
7.基于矩阵的模型(Acess Control Matrix)
使用矩阵的列和行来分别对应访问主体和访问客体,二者交叉位置的元素则代表着相应的主体对客体的操作规则,是一种自主访问控制模型。
8.Lipner模型
结合了Bell-LaPadula(机密性)模型和Biba模型(完整性)
把客体分成数据与程序,定义了5种安全类别
- 开发(D):正在开发、测试过程中的生产程序,但是还未在实际生产中使用。
- 生产代码(PC):生产进程和程序
- 生产数据(PD):涉及完整性策略的数据
- 系统开发(SD):正在开发过程中的系统程序,但是还未在实际生产汇总使用
- 软件工具(T):由生产系统提供的程序。但是与敏感性或受保护数据无关
定义了安全等级:
- 审计管理(AM):系统审计和管理功能所处的等级。
- 系统低层(SL):任意进程都可在这一等级上读取信息
9.Graham-Denning模型
提供一种能够委托或转移访问权限的方法,定义了一组基本权限,主体能够在客体上执行的一组命令
10.Harrison-Ruzzo-Ullman模型
涉及主体的访问权限以及这些权限的完整性,主体只能对客体执行一组有限的操作
11.Take-Grant 取予保护模型/票据授予模型
属于自主访问控制模型,访问控制矩阵模型中的一种,使用有向图的形式来表示系统。
使用有向图主体转移到客体,主体从其他主体获得的权限,通过图示/箭头表示。
12.Goguen-Meseguer模型
完整性模型、非干涉模型,基于主体可以访问的预设的域或客体列表。
13.Sutherland模型
完整性模型,基于定义一组系统状态以及初始状态和状态转换,通过预定的安全状态来保护完整性和阻止干扰。常被用来预防隐蔽通道。
特别声明:
1.以上所有描述内容部分参考链接/文献未逐一列出,若有侵权,请及时告知,有则改之无则加勉。
2.以上仅是学习过程的总结,相信有很多理解偏差的地方,特别希望指出,给予帮助,更新知识体系,共同进步。
3.以上内容大部分自己的理解,所以有些理解偏差,请批评指正!
参考材料:
<wiz_tmp_tag id="wiz-table-range-border" contenteditable="false" style="display: none;">
信息安全模型
标签:分析 tail perm inter graph disabled 思路 很多 资源
原文地址:https://www.cnblogs.com/worter991/p/12780535.html