标签:实例化 int 自己的 class rand logistic array 矩阵 mes
1.逻辑回归是怎么防止过拟合的?为什么正则化可以防止过拟合?(大家用自己的话介绍下)
①逻辑回归是利用正则化来防止过拟合的;
②因为正则化参数设置得足够大,权重矩阵被设置为接近于0的值,那么一些影响不大的因素就可以降低到0,则忽略不计,因此就可以让模型复杂度降低,从而防止过拟合。
2.用logiftic回归来进行实践操作,数据不限。
代码:
import pandas as pd import numpy as np from sklearn.linear_model import LogisticRegression from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler from sklearn.metrics import classification_report def logistic(): #读取数据 data = pd.read_csv(‘venv/data/201706120039邱杰(处理好).csv‘) # 将列‘电梯情况‘进行条件的判断,替换为0、1 data.loc[data[‘电梯情况‘] == ‘ 有‘, ‘电梯情况‘] = 1 # int 类型 data.loc[data[‘电梯情况‘] == ‘暂无‘, ‘电梯情况‘] = 0 # 提取列为‘面积‘、‘总价‘、‘室‘、‘厅‘为x data_x = data.iloc[:, [2, 3, 4, 5]] # 提取到面积、总价、室、厅 # 将x改为二维数组形式 data_x = np.array(data_x) # 将列为‘电梯情况‘为y data_y = data.iloc[:, 10] # 将y改为一维数据形式 data_y = np.array(data_y) #训练集分割 x_train, x_text, y_train, y_text = train_test_split(data_x, data_y, test_size=0.2, random_state=10) # 3 进行标准化处置 # 特征值和目标是是都必须进行标准化处理的(需要分别处理),实例化一个标注话API(X) std = StandardScaler() x_train = std.fit_transform(x_train) x_text = std.transform(x_text) #逻辑回归预测 lg = LogisticRegression() lg.fit(x_train, y_train) print(lg.coef_) lg_predeit = lg.predict(x_text) print(‘准确率:‘,lg.score(x_text, y_text)) print(‘召回率:‘,classification_report(y_text, lg_predeit,labels=[0,1], target_names=[‘无电梯‘,‘有电梯‘])) if __name__ == ‘__main__‘: logistic()
截图:
csv的截图:
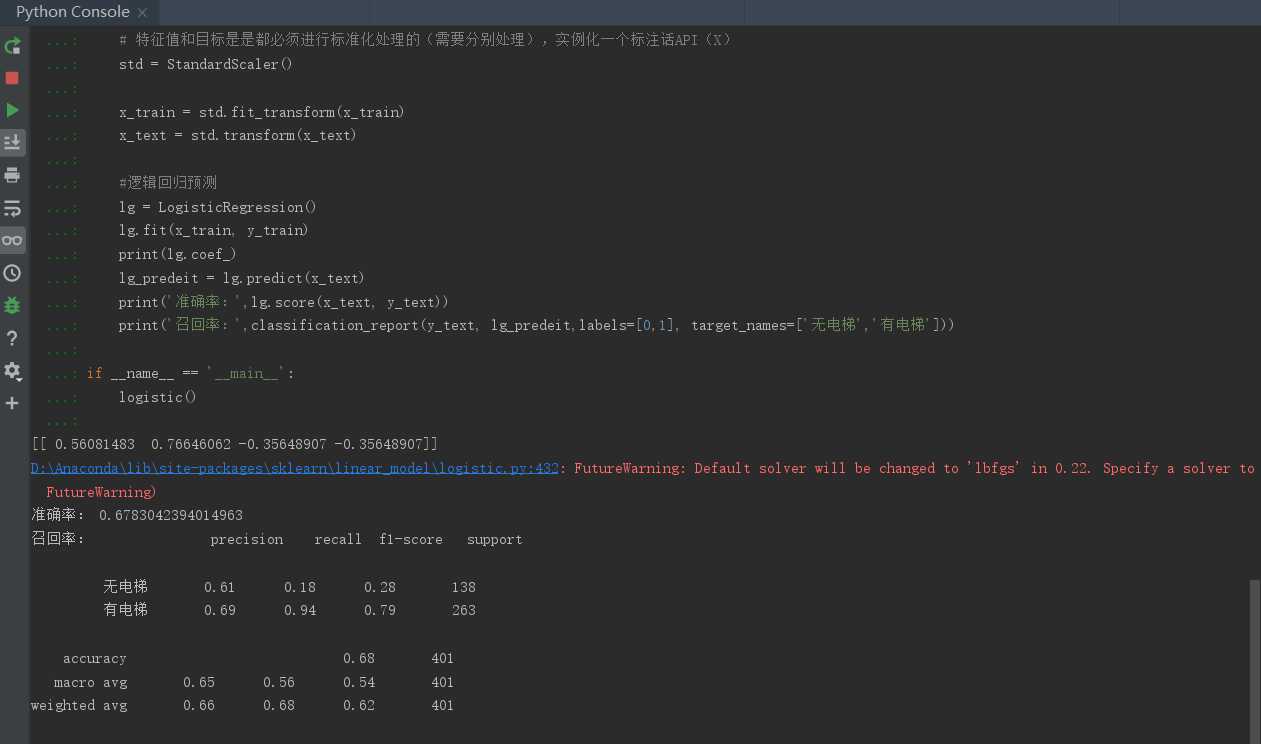
结果截图:
标签:实例化 int 自己的 class rand logistic array 矩阵 mes
原文地址:https://www.cnblogs.com/q1uj1e/p/12781416.html