标签:腾讯 知识 capacity 技术 hash函数 img 整数 性能 src
简介HashMap是平常使用的非常多的,内部结构是 数组+链表/红黑树 构成,很多时候都是多种数据结构组合。
我们先看一下HashMap的基本操作: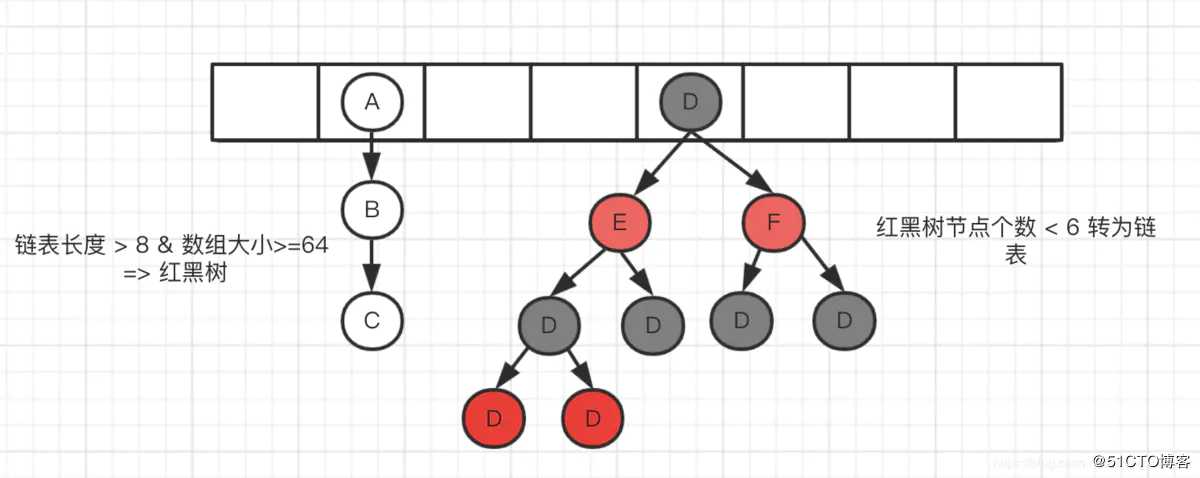
new HashMap(n);
第一个知识点,传入n,构造的HashMap容量就是n吗?
答案是:不一定。
public HashMap(int initialCapacity, float loadFactor) {
this.loadFactor = loadFactor; //负载因子 默认0.75
//设置容量
this.threshold = tableSizeFor(initialCapacity);
}
tableSizeFor 这段代码其实就做了一件事,例如,你初始化给了10,它会给你16,大于10的是2的k次幂。
以初始值50为例,讲一下实现原理:
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}算法就是让二进制不断右移,与自己异或,把第一位为1(最高位)后面全变为1,111111 + 1 = 1000000 = 26 2^62
6
(符合大于50并且是2的整数次幂 )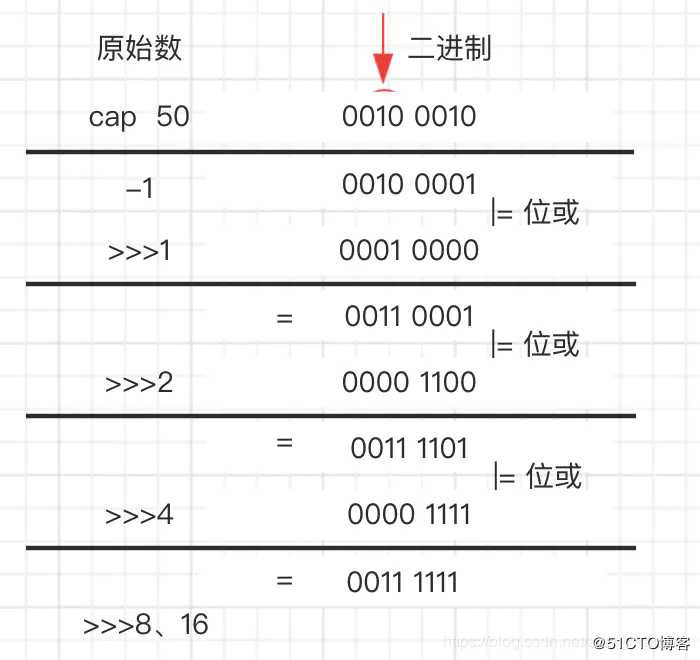
第二个知识点,回答开题的问题,为什么hash函数这么设计?
HashMap的hash函数是根据Key值计算的;
一定要尽可能降低hash碰撞,越分散越好;
算法一定要尽可能高效,因为这是高频操作;
再来看一下这段代码:
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}这段代码有个名字,叫扰动函数,大家想一下,如果hash函数直接使用key.hashCode()作为hash 值怎么样?
key.hashCode()获得的是key的hashcode(), 如果HashMap数组长度为16,求对象在数组存储位置 (n - 1) & hash 就相当于 0000 1111 & hash ,让 hash 高位全部置为0,只用到了 hash 的低位,因为只用了低位,碰撞的几率就会比较大。
聪明的算法设计者兼顾性能和降低碰撞,就考虑用高16位和低16位结合起来异或形成hash 值。如下图所示,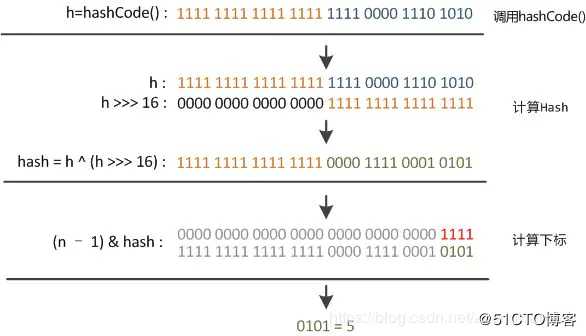
第三个知识点,相比1.7,JDK1.8做了哪些优化?
1.7 使用头插法,1.8使用尾插法;
1.7 hash函数使用4次位运算+5次异或,1.8使用1次位运算+1次异或;
1.7 使用数组+链表的结构,1.8 使用数组 + 链表 +红黑树;
1.7 扩容需要对原始元素重新hash & (len -1), 1.8 计算元素新位置 = 原始位置 / 原始位置 + 旧容量;
下面开始解释
面试腾讯,字节跳动,华为90%会被问到的HashMap!你会了吗?
标签:腾讯 知识 capacity 技术 hash函数 img 整数 性能 src
原文地址:https://blog.51cto.com/14801695/2490580