标签:guid methods int mfc 压缩 war 通过 ima 工作
出处 :2019 ResearchGate
作者 : Francesco Marra, Diego Gragnaniello, Luisa Verdoliva and Giovanni Poggi
摘要 : 目前深度学习模型只能输入很小的图像,叫做resizing。在图像篡改中,这可能会破坏高频细节。也可以在放弃对整幅图分析的情况下,做patch-wise处理。
本文提出基于CNN的篡改检测网络(拼接复制粘贴修复)
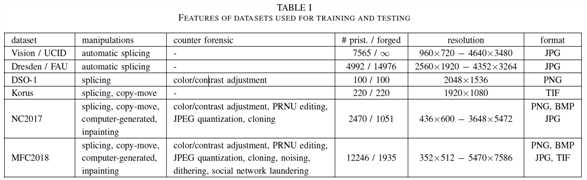
数据集 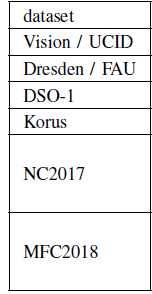
实验环境 Training took about three days with an Nvidia Tesla P100 GPU. With the same hardware, testing takes about half a second for a 3072×4096-pixel image
metrics the detection AUC、ROC
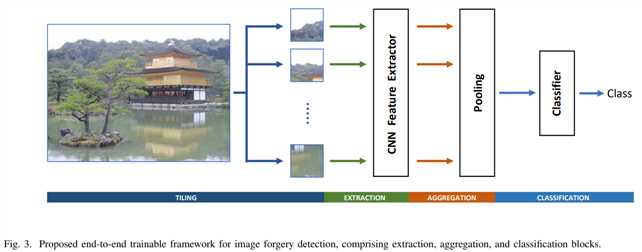
包含三部分:
图3是网络结构
池化公式如下
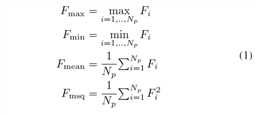
\(F_i\)是第i个patch的c维特征向量,\(N_p\)是patches的数量
池化类型会影响反向传播更新参数。\(F_{agg}\)是聚合后的特征,L是损失函数,\(\theta\)是cnn的参数,梯度公式是
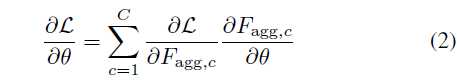
对应不同的池化

\(\delta_{i,j}=1\)当i=j时,否则=0。\(i_{max}(c)\)指最大特征向量。当同时使用多种形式的池化时,梯度作为单个项的加权和
本文的结构是端到端可训练的。
同一图象里的patch的标签相同,训练时不需要逐像素的ground truth,可以使用任意大小的图像。
在每个 training batch of images
图4是传统的cnn传播过程。
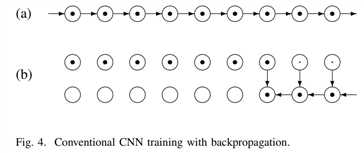
每个圆表示一个层,黑点表示存储激活函数。a)前向传播,每一层的激活函数都存储。b)从最后一层传播梯度,使用之后就擦除(小黑点)。但是深度网络包括数百层,每层有几个特征图,其大小通常与输入成比例,当一次处理一个大的输入图像时,需要存储大量的变量
使用 the gradient check pointing strategy[32] 梯度检查点策略
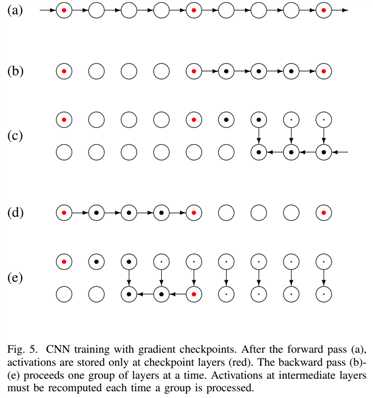
a.前向传播,使用后就删除所有激活函数,除了红点表示的“检查点层”。反向传播b-e,一次处理一组层,在处理时重新计算激活函数。b.允许反向传播梯度,直到检查点层本身。c.检查点之外的层上的所有变量都被删除,该过程将继续进行,并生成一组新的层d-e
通过明智地选择检查点的数量,可以显著地减少内存占用。虽然每个激活都要计算两次,但是计算开销是有限的,因为前向传递比反向传递参数少
生成一个合成数据集Vision / UCID
如表1
vision dataset:包含由35个不同设备使用自然高质量JPEG压缩获得的7565张图像
UCID:为了生成经过处理的图像,将从UCID数据集[34]的未压缩图像中手工裁剪的81个对象中提取的对象拼接到这些对象上。再做压缩旋转翻转操作。图6是例子

通过消融实验确定网络的具体实施,
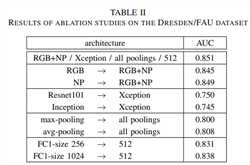
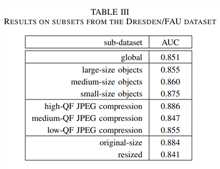
然后生成THE DRESDEN/FAU DATASET,做鲁棒性测试 ,如表3
对比方法
image-level:
the SPAM+SVM method [8]
the CNN+SVM method of [16]
LSTM-EnDec [25]
patch-level:借用[29]的结果
CFA [2]
DCT [3]
NOI [1]
EXIF-SC [31]
Noiseprint [29]
数据集
DSO-1[40]:只包含拼接,很少或没有后期处理,只包含大尺寸的高质量图像
korus[41]:同时存在拼接和复制,只包含大尺寸的高质量图像,没有压缩
NC2017
MFC2018
MFC2019[42]
NIST
表4是 the detection AUC 结果
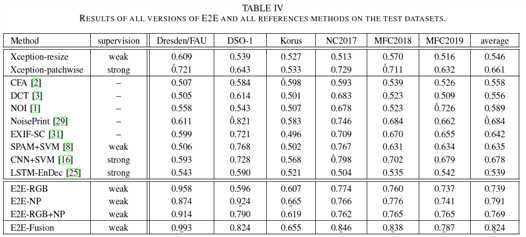
strong (pixel-wise ground truth),weak (only image label), (none) for blind methods
图8是ROC曲线
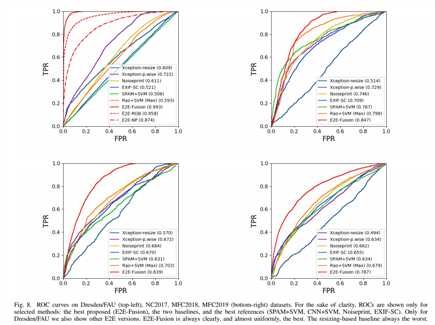
表5 6
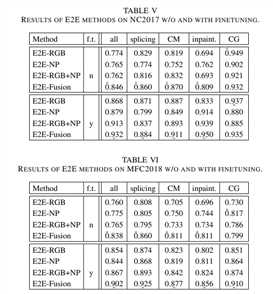
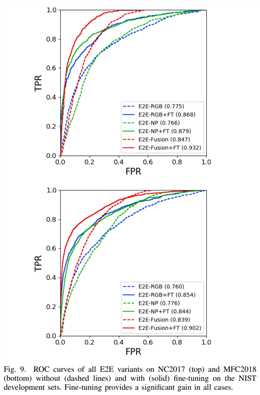
图9是相应的ROC曲线
得到the Grad-CAM(guided gradient weighted class activation map)[43],图10是Dresden/FAU dataset的activation map

可以对用户选择的ROI区域进行分析,如图11

未来工作方向
应考虑采用更好的池化形式,以便在聚合阶段保存大范围空间关系。
此外,还应考虑图像和对象语义,以补充当前框架分析的底层信息。
A Full-Image Full-Resolution End-to-End-Trainable CNN Framework for Image Forgery Detection
标签:guid methods int mfc 压缩 war 通过 ima 工作
原文地址:https://www.cnblogs.com/qina/p/12784388.html