标签:数据 hup 笔记 安装方法 实体 降级 LTP pre 失败
pyltp 是哈工大自然语言工作组推出的一款基于Python 封装的自然语言处理工具(轮子),提供了分词,词性标注,命名实体识别,依存句法分析,语义角色标注的功能。
安装方法一:使用pip命令安装
pip install pyltp
注:此种方法大概率会失败,会出现较多问题,如VC++编译环境缺少。
安装方法二:使用whl轮子安装
轮子下载地址:
链接:https://pan.baidu.com/s/1Jbw6IjVbb-URZCHvh3FNDQ
提取码:i3le
pyltp-0.2.1-cp35-cp35m-win_amd64.whl(python3.5,64位)
pyltp-0.2.1-cp36-cp36m-win_amd64.whl(python3.6,64位)(根据我的编译环境,下载这个)
下载好后,在安装包目录下,打开系统命令框,输入:
pip install pyltp-0.2.1-cp36-cp36m-win_amd64.whl
即可安装成功。
pyltp要能实现分词、词性标注、命名实体识别,还需要安装数据包以及模型。请确保下载的模型版本与当前版本的 pyltp 对应,否则会导致程序无法正确加载模型。
模型下载地址:https://pan.baidu.com/share/link?shareid=1988562907&uk=2738088569#list/path=%2F,
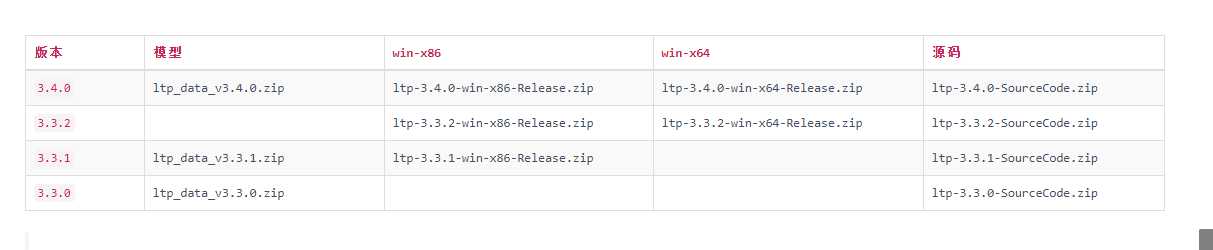
根据需要,我们下载3.4版本的模型数据。

下载后,可以解压到任意位置,C盘,D盘、E盘都行,为了方便查找数据,我将模型文件解压到我的pyltp库文件中。如下图:
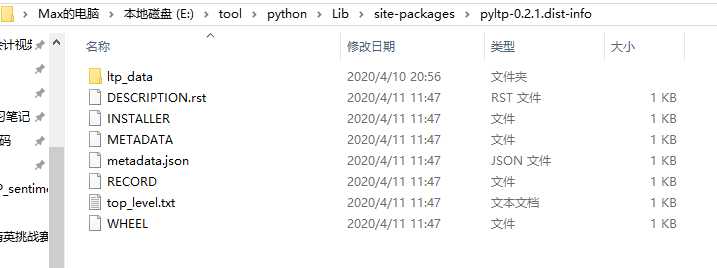
1. 官方的下载模型文件,ltp_data并解压到任意位置(注意点:模型的路径最好不要有中文,不然模型加载不出), 2. 解压后得到一个大于1G的文件夹,确保此文件夹名称为ltp_data,位置任意,但在Python程序中一定要指明这个路径。 3. LTP提供的模型包括:(在ltp_data文件夹里面) cws.model 分句模型,单文件 pos.model 词性标注模型,单文件 ner.model 命名实体识别模型,单文件 parser.model 依存句法分析模型,单文件 srl_data/ 语义角色标注模型,多文件(文件夹srl)(注意:按照官网提示注:3.4.0 版本 SRL模型 pisrl.model 如在windows系统下不可用,可以到官网“此链接” 下载支持windows的语义角色标注模型。) 2017/06/15 16:42 182,672,934 cws.model 2017/07/07 15:47 260 md5.txt 2017/06/15 15:19 22,091,814 ner.model 2017/06/15 16:26 367,819,616 parser.model 2017/06/15 16:00 196,372,381 pisrl.model 2017/06/15 16:43 433,443,857 pos.model 2017/07/07 15:47 6 version 7 个文件 1,202,400,868 字节 2 个目录 108,015,374,336 可用字节 参考:https://blog.csdn.net/shuihupo/article/details/81545335
参考资料:
官方使用文档:https://github.com/HIT-SCIR/ltp
Python文档说明地址:https://github.com/HIT-SCIR/pyltp
pyltp安装过程中问题汇总:
问题一:python版本不是3.6,为3.7或者更高的版本,安装轮子失败
原因:目前pyltp库最高支持python3.6版本,更高版本的python安装会出错。
解决方法:1、将你的python版本降级,降到3.6版本,降级方法,百度。
2、更改轮子名称,如pyltp-0.2.1-cp36-cp36m-win_amd64.whl(python3.6,64位),更改为pyltp-0.2.1-cp37-cp37m-win_amd64.whl(python3.7),亲测有效。
问题二:使用方法一安装出现VC++错误,
原因:你的电脑确实VC++编译环境,需要安装特定的VC++支持数据包。
解决方法:安装支持环境,下载下面的exe文件,安装VC++编译环境。
链接:https://pan.baidu.com/s/1za9j5p4YxxFle6-MT3NKMQ
提取码:y70v
# -*- coding: utf-8 -*- import os LTP_DATA_DIR = r‘E:\tool\python\Lib\site-packages\pyltp-0.2.1.dist-info\ltp_data‘ # ltp模型目录的路径 cws_model_path = os.path.join(LTP_DATA_DIR, ‘cws.model‘) # 分词模型路径,模型名称为`cws.model` from pyltp import Segmentor segmentor = Segmentor() # 初始化实例 segmentor.load(cws_model_path) # 加载模型 words = segmentor.segment(‘大明王很喜欢一个人‘) # 分词 print (‘\t‘.join(words)) segmentor.release() # 释放模型
E:\tool\python\python.exe "E:/学习笔记/NLP学习/NLP code/情感分析2/test1.py" 大明王 很 喜欢 一个 人 Process finished with exit code 0
专注、认真
标签:数据 hup 笔记 安装方法 实体 降级 LTP pre 失败
原文地址:https://www.cnblogs.com/maxxu11/p/12785830.html