标签:结构 编码 不能 详细分析 超时 double 任务 数据结构 image
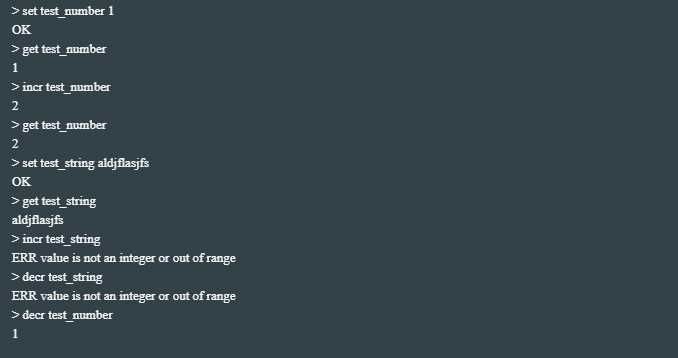
Set KEY VALUE //设置给定key的值,如果key不存在则添加,如果存在则更新值
SETEX key Seconds VALUE //为指定的 key 设置值及其过期时间。如果 key 已经存在, SETEX命令将会替换旧的值。
Get KEY //获取指定 key 的值
GETRANGE KEY start end //获取存储在指定 key 中字符串的子字符串。字符串的截取范围由 start 和 end 两个偏移量决定(包括 start 和 end 在内)。
GETSET KEY VALUE //设置给定key的值,并返回旧值
SETNX KEY VALUE //给定key不存在时,为key设定值
MSET key1 value1 key2 value2 .. keyN valueN //同时设定多个值
INCR KEY //给定key的值+1 key对应的值不是整型会报错,value is not an integer or out of range
DECR KEY //给定key的值-1 key对应的值不是整型会报错,value is not an integer or out of range
Redis hash 是一个 string 类型的 field 和 value 的映射表,hash 特别适合用于存储对象。通过命名很清楚的之后Hash这种数据类型时使用了哈希表作为底层实现,关于什么是哈希,什么是哈希表可以自行百度,后续有时间可以单独开一篇来详细分析Redis hash的实现。
Hset key field value //设置给定key 的field的value
Hmset Key field1 value1 field2 value 2 //同时设置多个 field value
Hget key field //获取key中指定feild的value值
Hmget key feild1 feild2 //获取多个feild的值

在前面说明string类型的时候有说到可以用string类型来操作序列化的对象,但是我们在对于对象的任何修改的时候都需要把字符串取出来然后反序列化,再进行修改,再序列化,最后存入到redis中,这样的消耗太大了,而利用hash这种数据结构就很方便的实现对象的部分字段修改。
Redis List是简单的字符串列表,数据结构是双向链表,按照插入顺序排序。你可以添加一个元素到列表的头部(左边)或者尾部(右边),也就是兼有栈和队列的特性。因为是链表,所以查找的复杂度就是O(n)了,但是考虑到常用的指令都是在列头和列尾操作,所以这种数据结构才是最适合的。
Lpush key value1 value2 //将一个或多个值插入List的头部
Rpush key value1 value2 //将一个或多个值插入List的尾部
Lpop key //移除列表头的元素
Rpop key //移除列表尾元素
BLpop key timeut//移除列表头的元素,如果没有元素会阻塞直到发现可弹出元素或者超时
LREM key count value //根据参数 COUNT 的值,移除列表中与参数 VALUE 相等的元素。 count> 0 从列表头向尾检索移除count个与value相等的元素并移除;count < 0 从尾向头检索移除count个与value相等的元素并移除;count = 0,移除所有与value相等的元素
各种列表的存储
消息队列,可以利用BLpop相关的指令来实现消息队列,但是没有ack机制,需要其他方式来弥补。可以使用sorted set 来存储执行的结果,当消费消息的时候,给sorted set 添加一条数据并用时间作为score,当任务完成从sorted set中移除,定时根据score检查超时任务并重新放入list中。另一种做法就是利用list中BRPpopLpush当弹出一个值的时候,将该值添加到另一个列表,完成时利用LREM命令消除掉,这种方式不太好的地方就是不太方便进行超时任务的处理。 但是,对于消息队列,我们已经有RabbitMQ,Kafka之类成熟且机制完善的消息队列了,建议使用的时候就不用考虑用Redis来做了。当然redis支持fabu/订阅的模式(后面会详细介绍),也是Redis能作为消息队列的原因。
利用LRange实现列表的分页,但是需要注意的是LRange需要的参数start 和end,是右闭合的,也就是包含end下标所代表的项
Redis 的 Set 是 String 类型的无序集合。集合成员是唯一的,这就意味着集合中不能出现重复的数据。
Redis 中集合是通过哈希表实现的,其实就是一个值为null的hashmap,所以添加,删除,查找的复杂度都是 O(1),也可以通过计算hash来排重和判断一个数据是否在集合中。
SADD KEY member1 member2 //向集合中添加一个或多个成员
SPOP KEY //移除并返回集合中的一个随机元素
SRem KEY member1 member2 //移除集合中一个或多个成员
SInter key1 key2 //返回给定集合的交集
SUnion key1 key2 //返回给定集合的并集
SDiff key1 key2 //返回给定集合的差集
Smembers Key //返回集合中所有member
Sismember Key member //判断member是否在集合中
Redis sorted set和Set一样也是string类型元素的集合,且不允许重复的成员。
不同的是每个元素都会关联一个double类型的分数。redis正是通过分数来为集合中的成员进行从小到大的排序。
有序集合的成员是唯一的,但分数(score)却可以重复。
Redis sorted set 内部使用了ziplist和SkipList两种实现,当同时满足元素数量小于128个和所有member的长度都小于64个字节的时候会采用ziplist,如果不满足则采用SkipList的编码方式。当然可以通过Redis配置zset-max-ziplist-entries 和 zset-max-ziplist-value来修改这两个条件。
 关于ziplist和skiplist的介绍太多了,感兴趣的可以自行百度一下。
关于ziplist和skiplist的介绍太多了,感兴趣的可以自行百度一下。
ZAdd Key score1 member1 score2 member2 //向一个集合添加成员,如果成员存在就更新分数
ZCount Key min max //获取指定分数区号的成员数量,包括min和max
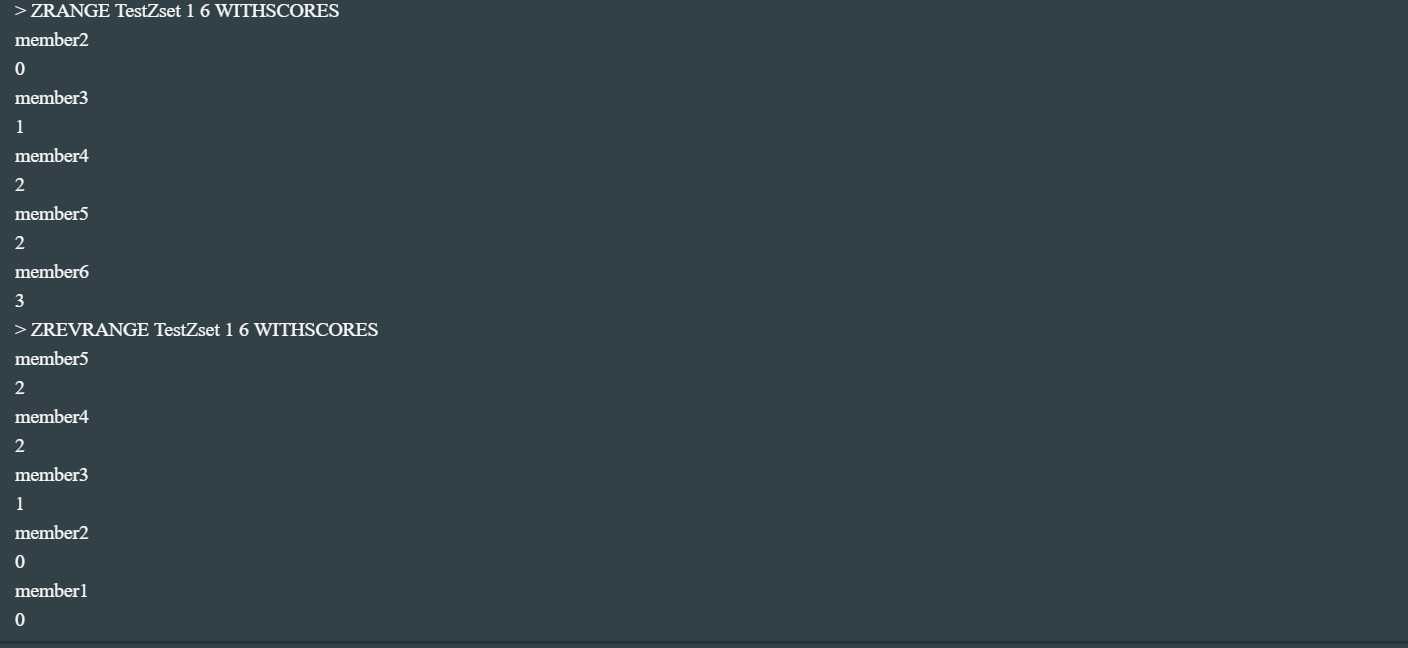
ZRANGE Key start stop [WITHSCORES]//获取指定下标范围的有序成员列表 按照分数排序
ZREVRANGE Key start stop [WITHSCORES]//获取指定下标范围的有序成员列表 按照分数倒序

标签:结构 编码 不能 详细分析 超时 double 任务 数据结构 image
原文地址:https://www.cnblogs.com/rstar/p/12786586.html