标签:str inpu throw rri 数据分析 compare ESS 执行 mapper
//使用MapReduce框架完成二次排序
// 主要原理使用组比较器完成排序再规约
// 环境 由于IDEA不会本地提交MR任务转到eclipse
//代码如下
package com.swust.mapreduce;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
/**
*
* @author 雪瞳
* @Slogan 时钟尚且前行,人怎能再此止步!
* @Function 利用 MapReduce完成二次排序
*
*/
public class SecondarySort {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//配置基础属性
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(SecondarySort.class);
job.setJobName("sort");
conf.set("mapreduce.app-submission.cross-platform", "true");
conf.set("mapreduce.framework.name", "local");
//配置输入输出路径
FileSystem fs = FileSystem.get(conf);
String inPath = "/user/data";
String outPath = "/user/result";
Path inputPath = new Path(inPath);
Path outputPath = new Path(outPath);
if(fs.exists(outputPath)){
//递归删除
fs.delete(outputPath, true);
}
FileInputFormat.addInputPath(job,inputPath);
FileOutputFormat.setOutputPath(job, outputPath);
//执行逻辑主体
job.setMapperClass(SecondarySortMapper.class);
job.setOutputKeyClass(DataInfo.class);
job.setOutputValueClass(Text.class);
job.setSortComparatorClass(SortComparator.class);
job.setReducerClass(SecondarySortReducer.class);
boolean flag = job.waitForCompletion(true);
if (flag == true){
System.err.println("success!");
}
}
}
package com.swust.mapreduce;
import org.apache.hadoop.io.WritableComparable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class DataInfo implements WritableComparable<DataInfo>{
private String name;
private int time;
private int value;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getTime() {
return time;
}
public void setTime(int time) {
this.time = time;
}
public int getValue() {
return value;
}
public void setValue(int value) {
this.value = value;
}
@Override
public int compareTo(DataInfo info) {
int r1 = this.name.compareTo(info.getName());
if (r1 == 0){
int r2 = Integer.compare(this.time,info.time);
if (r2 == 0){
int r3 = Integer.compare(this.value,info.value);
return r3;
}
return r2;
}
return r1;
}
@Override
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeUTF(this.name);
dataOutput.writeInt(this.time);
dataOutput.writeInt(this.value);
}
@Override
public void readFields(DataInput dataInput) throws IOException {
this.setName(dataInput.readUTF());
this.setTime(dataInput.readInt());
this.setValue(dataInput.readInt());
}
}
package com.swust.mapreduce;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
*
* @author 雪瞳
* @Slogan 时钟尚且前行,人怎能再此止步!
* @Function 实现数据的K-V映射关系
*
*/
public class SecondarySortMapper extends Mapper<LongWritable,Text,DataInfo,Text> {
//x 2 9
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] words = value.toString().split(" ");
DataInfo info = new DataInfo();
info.setName(words[0]);
info.setTime(Integer.parseInt(words[1]));
info.setValue(Integer.parseInt(words[2]));
Text val = new Text(words[2]);
context.write(info,val);
}
}
package com.swust.mapreduce;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class SecondarySortReducer extends Reducer<DataInfo,Text,Text,Text> {
@Override
protected void reduce(DataInfo key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
// while (values.iterator().hasNext()){
// Text value = values.iterator().next();
// String tkey = key.getName() + "--" + key.getTime();
// context.write(new Text(tkey), value);
// }
for (Text val : values){
String tkey = key.getName() + "--" + key.getTime();
context.write(new Text(tkey), val);
}
}
}
package com.swust.mapreduce;
/**
*
* @author 雪瞳
* @Slogan 时钟尚且前行,人怎能再此止步!
* @Function 自定义组比较器
*
*/
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
public class SortComparator extends WritableComparator{
private DataInfo d1;
private DataInfo d2;
@Override
public int compare(WritableComparable a, WritableComparable b) {
d1 = (DataInfo) a;
d2 = (DataInfo) b;
int c1 = d1.getName().compareTo(d2.getName());
if (c1 == 0){
int c2 = Integer.compare(d1.getTime(),d2.getTime());
return c2;
}
return c1;
}
public SortComparator(){
super(DataInfo.class,true);
}
}
//运行结果
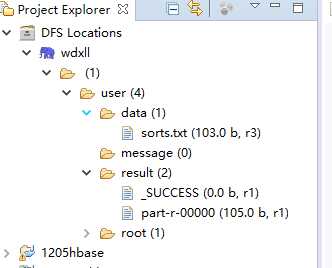

标签:str inpu throw rri 数据分析 compare ESS 执行 mapper
原文地址:https://www.cnblogs.com/walxt/p/12788775.html