标签:复杂 寄存器 文章 读写 调整 https 频繁 hardware 多次
引言:前面我们从底往上介绍了磁盘到文件系统再到虚拟内存,而我们经常听到“高速缓存”是个啥玩意?首先我们扩展下该知识点。而本文主要是站在计算机体系的角度上和站在应用程序如数据库的角度上对存储和存储分层做最后的总结。
首先我们站在计算机体系结构的角度看存储分层,如下图:
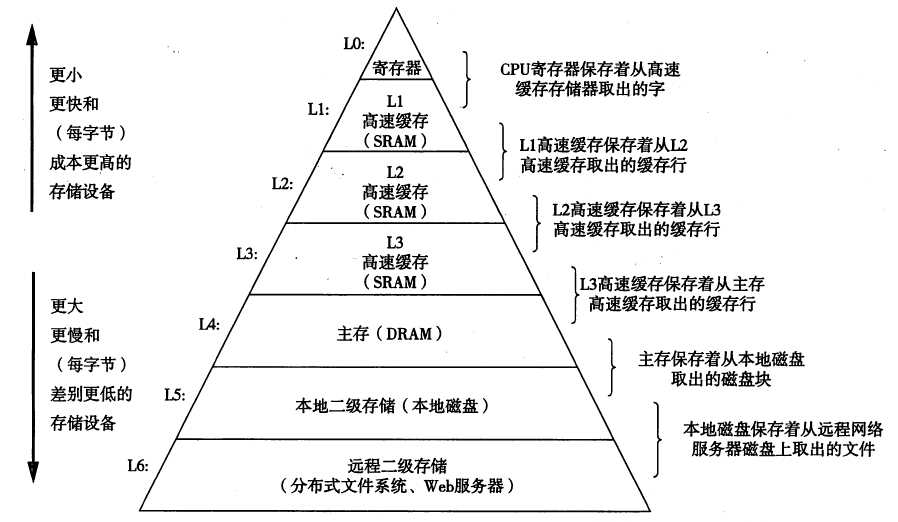
仔细看看此图,特别是两边的注释,存储的结构就一目了然。而很多的资料上介绍的是存储经典的三层金字塔:L0(或L2)、L4和L5。而这个图是见过最详细的了,非常好!
上一篇虚拟内存属于图中的L4,而我们有一系列的文章大多在讲述L5,NAS可以属于L6,同时希望有一天来讲述真正的分布式文件系统。今天我们主要介绍L0-L3。
在这个层次结构的最顶层,是CPU内部的一些寄存器,它们的访问速度是非常快的,当今的CPU主频都是GHZ级别的,而对于内存DDR(L4)来说,每次存取操作都会耗用很多的时钟周期,这意味着,CPU需要等待很长时间来完成一次读或者写操作。
为了缩小CPU和RAM之间的速度不匹配,引入了硬件高速缓存内存(hardware cache memory)。硬件高速缓存基于著名的局部性原理(locality priciple),该原理既适用于程序结构也适用于数据结构。
80x86体系结构引入了一个叫行(line)的新单位。行由十几个连续的字节组成,它们以脉冲突发模式(burst mode)在慢速DRAM和快速的用来实现高速缓存的片上静态RAM(SRAM)之间传送,用来实现高速缓存。
高速缓存再被细分为行的子集。在一种极端的情况下,高速缓存可以是直接映射的(direct mapped),这是主存个中的一个行总是存放在高速缓存中完全相同的位置。在另一种极端情况下,高速缓存是充分关联的(fully associative),这意味着主存中的任意一个行可以存放在高速缓存中的任意位置。但是大多数高速缓存在某种程度上是N-路组关联的(N-way set associative),意味着主存中的任意一个行可以存放在高速缓存N行中的任意一行中。
高速缓存单元插在分页单元和主内存之间。它包含一个硬件高速缓存内存(hardware cache memory)和一个高速缓存控制器(cache controller)。高速缓存内存存放内存中真正的行。高速缓存控制器存放一个表项数组,每个表项对应高速缓存内存中的一个行。每个表项有一个标签(tag)和表示高速缓存行状态的几个表示(flag)。这个标签由一些位组成,这些位让高速缓存控制器能够辨别由这个行当前所映射的内存单元。这种内存物理地址通常分为3组:最高几位对应标签,中间几位对应高速缓存控制器的子集索引,最低几位对应行内的偏移量。
当访问一个RAM存储单元是,CPU从物理地址中提取出子集的索引号并把子集中所有行的标签与物理地址的高几位相比较。如果发现某一个行的标签与这个物理地址的高位相同,则称CPU(的高速)缓存命中(cache hit);否则,(高速)缓存不命中(cache miss)。缓存不命中一般需要进行置换和调整工作集或者访问内存,太频繁说明程序的局部性较差。
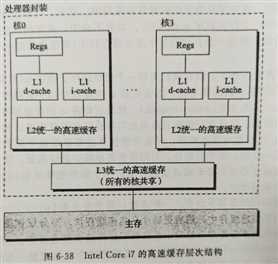
如上图为多处理器系统缓存结构。在L1中分数据cache(d-cache)和指令cache(i-cache),它们分别用来存放数据和执行这些数据的指令。L2 cache只存储数据,因此不分数据cache和指令cache。L3 cache为多核共享。
多处理器系统的每一个处理器都有一个单独的硬件高速缓存,因此它们需要额外的硬件电路用于保持高速缓存内容的同步。更新变得更耗时:自己一个CPU修改了它的硬件高速缓存,就必须检查其他CPU中是否有同样的数据;如果是,那么它必须通知其他CPU用适当的值更新数据。这种活动叫做高速缓存侦听(cache snooping)。这些都在硬件级处理,内核无需关心。
多级缓存的一致性是由硬件实现的,Linux忽略这些硬件细节并假定只有一个单独的高速缓存。
两种不同形式:时间局部性和空间局部性。
在一个具有良好时间局部性的程序中,被引用过一次的内存位置很可能在不远的将来在此多次引用;
在一个具有良好空间局部性的程序中,如果一个内存位置被引用了一次,那么程序在不远的将来引用附近的一个内存位置。
有良好局部性的程序比局部性差的程序运行的更快。因此当我们引入小而快的缓存来存放最近最常使用的代码和数据,将极大提高系统的运行效率。
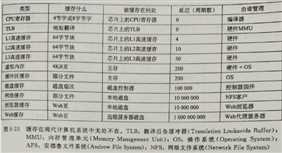
小结:现代系统中到处使用了缓存,如上图,CPU芯片、操作系统、文件系统、RAID阵列和万维网上都使用了缓存。各种各样硬件和软件的组合构成和管理着缓存。
这一节我们从应用程序的角度,看存储系统的分层:

我们知道,缓存无处不在。上面三层都有自己的缓存,一般都在主机内存,例如文件系统和应用程序数据库,都有自己的缓存。根据虚拟内存的定义,它们都是进程,都有自己的虚拟地址。
但是最底层的磁盘控制器或者RAID卡则有自己的硬件缓存,前面我们提到过,RAID卡自带CPU、ROM和RAM,所以它就是一个小型的计算机。如果有RAID卡的服务器就是计算机中嵌套小型计算机。RAID卡的缓存是RAM芯片,不是SRAM,但是也具备缓存的功能。
这些缓存原理是相似的,但同时也可能是矛盾的。
(1)WriteBack模式:回写模式。上层发送过来的数据,将其保存到缓存后,立即通知主机IO已经完成。从而主机可以不加等待地执行下一个IO,此时数据还在缓存中,并没有真正写入磁盘。所以这是有一定风险的,如果此时意外断电等异常,存在丢失数据的可能。
(2)WriteThrough模式:写透模式,直写模式。上层发送过来的数据,只有数据写入磁盘之后,才通知主机IO已经完成。这种保证了数据的完整性。但是虽然缓存还是有一定的缓冲作用,但是提速的作用就没有了。
除了写缓存外,读缓存也非常重要,缓存算法是门复杂的学问,有一套复杂的机制,这里介绍两种常见的模式。
(1)预取模式(PreFetch):对磁盘接下来“有可能”被主机访问到的数据,在主机还没有发出读IO请求的时候,就“擅自”先读入到缓存。这是RAID卡常见的模式。
(2)脏读模式(dirty):数据被修改后,继续保留在缓存中,认为下次很有可能被读取。我们前面提到虚拟内存页面置换非常经典的LRU算法就是这种方式。也大量应用在数据库中。其实这也是访问的局部性原理。
以上是大部分缓存包括cache、RAM和RAID卡常见的读写模式。
但是文件系统的IO定义上有所不同:主要有O_DIRECT和O_SYNC两个选项。
I/O缓冲的过程是这样的:用户数据 –> stdio缓冲区 –> 内核缓冲区高速缓存 –> 磁盘。
O_DIRECT:用于让IO从用户态直接跨过“stdio缓冲区的高速缓存”和“内核缓冲区的高速缓存”,直接写到存储上。
O_SYNC:用于控制“内核缓冲区的高速缓存”直接写到存储上,即强制刷新内核缓冲区到输出文件的存储。
文件系统最后写到磁盘,而磁盘可能再有缓存模式,这样整个IO流程将变得更加复杂。建议就是,回写模式或者O_SYNC方式只要有一处足矣;如果需要为了确保数据安全,那么则选择所有的缓存设置为WriteThrough或者O_DIRECT。
最后,数据库系统也是存储系统的一部分,也属于存储系统的范畴,它和文件系统在很多方面是类似的。例如MySQL有非常丰富的日志文件,其中重写日志和文件系统的日志类似都是为了保证数据的一致性;同时MySQL还有非常完善的缓存机制和检查机制check point。
数据库的主要作用是管理数据,(主要战场)不是在磁盘上就在内存中(如Redis)。而文件系统也是将数据最终写在磁盘上。它们的管理的数据形式不一样,对象不一样,所以机制会有不同。但是最终都是利用磁盘和内存作为缓存对数据进行管理。最终都利用了存储结构中上层对下层的缓存,充分利用局部性原理提高性能。
参考资料:
《深入理解计算机系统》第三版。
《大话存储II》。
标签:复杂 寄存器 文章 读写 调整 https 频繁 hardware 多次
原文地址:https://www.cnblogs.com/orange-CC/p/12689583.html