标签:pre 主机 module hdp 存在 $path instance cpu核数 100g
cd /opt/sofaware/
wget https://downloads.lightbend.com/scala/2.11.7/scala-2.11.7.tgz
Tar -zxvf scala-2.11.7.tgz -C /opt/module
vi /etc/profile
在最后面添加
export SCALA_HOME=/opt/module/scala-2.11.7
export PATH=$PATH:$SCALA_HOME/bin
source /etc/profile

cd /opt/sofaware/
wget https://d3kbcqa49mib13.cloudfront.net/spark-2.2.0-bin-hadoop2.7.tgz
Tar -zxvf spark-2.2.0-bin-hadoop2.7.tgz -C /opt/module
cd /opt/module/
mv spark-2.2.0-bin-hadoop2.7 spark-2.2.0
vi /etc/profile
export SPARK_HOME=/opt/spark/spark-2.2.0
export PATH=$SPARK_HOME/bin:$PATH
需要修改的配置文件有两个
Spark-env.sh, spark-defaults.conf
cd /opt/module/spark-2.2.0/conf
cp spark-env.sh.template spark-env.sh # 复制并重命名
vim spark-env.sh
配置内容如下
# 配置JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_144
# 配置SCALA_HOME
export SCALA_HOME=/opt/module/scala-2.11.7
# 配置HADOOP
export HADOOP_HOME=/opt/module/hadoop-2.7.2/
export HADOOP_CONF_DIR=/opt/module/hadoop-2.7.2/etc/hadoop
#定义管理端口
export SPARK_MASTER_WEBUI_PORT=8888
#定义master域名和端口
export SPARK_MASTER_HOST=hdp-100
export SPARK_MASTER_PORT=7077 # 提交Application的端口
export SPARK_MASTER_IP=192.168.160.100
# 定义work节点的管理端口
export SPARK_WORKER_WEBUI_PORT=8888
# 每一个Worker最多可以使用的cpu core的个数,真实服务器如果有32个,可以设置为32个
export SPARK_WORKER_CORES=3
# 每一个Worker最多可以使用的内存,真实服务器如果有128G,你可以设置为100G
export SPARK_WORKER_MEMORY=2g
JAVA_HOME:Java安装目录
SCALA_HOME:Scala安装目录
HADOOP_HOME:hadoop安装目录
HADOOP_CONF_DIR:hadoop集群的配置文件的目录
SPARK_MASTER_IP:spark集群的Master节点的ip地址
SPARK_WORKER_MEMORY:每个worker节点能够最大分配给exectors的内存大小
SPARK_WORKER_CORES:每个worker节点所占有的CPU核数目
SPARK_WORKER_INSTANCES:每台机器上开启的worker节点的数目
cd /opt/module/spark-2.2.0/conf
cp spark-defaults.conf.template spark-defaults.conf # 复制并重命名
vim spark-defaults.conf
配置如下内容
spark.eventLog.enabled=true
spark.eventLog.compress=true
# 保存在本地
# spark.eventLog.dir=file://opt/moudle/hadoop-2.7.2/logs/userlogs
# spark.history.fs.logDirectory=file://opt/moudle/hadoop-2.7.2/logs/userlogs
# 保存在hdfs上
spark.eventLog.dir=hdfs://hdp-100:9000/tmp/logs/root/logs
spark.history.fs.logDirectory=hdfs://hdp-100:9000/tmp/logs/root/logs
spark.yarn.historyServer.address=hdp-100:19888
rsync -av /opt/module/spark-2.2.0/ hdp-101:/opt/module/spark-2.2.0/
rrsync -av /opt/module/spark-2.2.0/ hdp-102:/opt/module/spark-2.2.0/
Scala
rsync -av /opt/module/scala-2.11.7/ hdp-101:/opt/module/scala-2.11.7/
rsync -av /opt/module/scala-2.11.7/ hdp-102:/opt/module/scala-2.11.7/
复制配置文件
rsync -av /etc/profile hdp-101:/etc/profile
rsync -av /etc/profile hdp-102:/etc/profile
在相应的主机上使配置文件生效
source /etc/profile
cd /opt/module/spark-2.2.0/
sbin/start-all.sh
打开spark-shell
spark-shell
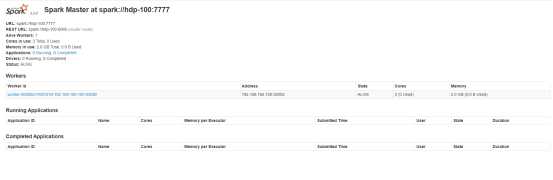
web端:http://hdp-100:8888/
标签:pre 主机 module hdp 存在 $path instance cpu核数 100g
原文地址:https://www.cnblogs.com/hziwei/p/12794092.html