标签:val 关闭 directory 选择 兴趣 end 使用 取数 mic
Apache的Hadoop是一个开源的、可靠的、可扩展的系统架构,可利用分布式架构来存储海量数据,以及实现分布式的计算。
Hadoop许使用简单的编程模型在计算机集群中对大型数据集进行分布式处理。可以从单个服务器扩展到数千台机器,
每个机器都提供本地计算和存储,而不是依靠硬件来提供高可用性。
此外,Hadoop集群的高可用性也非常良好,因为框架内的机制是可以够自动检测和处理故障。
hadoop名字的来源:这个名字不是一个缩写,它是一个虚构的名字。该项目的创建者,Doug Cutting如此解释
Hadoop的得名:"这个名字是我孩子给一头吃饱了的棕黄色大象命名的。我的命名标准就是简短,容易发音和拼写,
没有太多的意义,并且不会被用于别处。小孩子是这方面的高手。
第一种方式:官网下载 http://hadoop.apache.org/releases.html
第二种方式:百度网盘2.7.1版本 链接: https://pan.baidu.com/s/1Nkp4hQEMWblKqdBvj-lUZA 密码: yy18
单机模式:不能使用HDFS,只能使用MapReduce,所以单机模式最主要的目的是在本机调试mapreduce代码
伪分布式模式:用多个线程模拟多台真实机器,即模拟真实的分布式环境。(本次用这个)
完全分布式模式:用多台机器(或启动多个虚拟机)来完成部署集群。
1关闭防火墙.
执行:service iptables stop 临时关闭防火墙,重启失效
chkconfig iptables off 永久关闭防火墙,打完上面的命令再打一次这个,两个配合永久关闭.
2.配置主机名称
有些主机名称名字又长,有不好记,就需要改一下主机名称,配置Hadoop的时候会方便一些
当然也可以不改,不影响的
执行: vim /etc/sysconfig/network 找到HOSTNAME改等号后面就可以改你想改的主机名称了
我这里是BigData02我就不改了,你们随意。
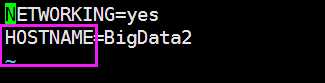
注意:主机名里不能有下滑线,或者特殊字符 #$,不然会找不到主机导致无法启动
这种方式更改主机名需要重启才能永久生效,因为主机名属于内核参数
如果不想重启,可以执行:host name BigData2(这里写你改的)。
但是这种更改是临时的,重启后会恢复原主机名。
所以可以结合使用。先修改配置文件,然后执行:hostname BigData02 。
可以达到不重启或重启都是主机名都是同一个的目的
3.配置hosts文件
执行 vim /etc/hosts
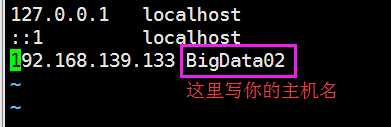
4.配置自己节点免秘钥登录
如果是单机的伪分布式环境,节点需要登录自己节点,即BigData02要登录BigData02
但是此时是需要输入密码的,所以要在BigData02节点上配置免密匙登录.
执行:ssh-keygen
然后一直回车
生成节点的公钥和私钥,生成的文件会自动放在/root/.ssh目录下(了解)
启动hadoop的时候会自己调用自己,还有重复输入用户名和密码太麻烦了。所以就
这样Hadoop重启的时候就可以不用重复输入账号密码了
比如:ssh 你的主机ip 我刚才改hosts文件了,把我的ip映射成BigData02也可以用
ssh BigData02 登录,记住登录了别忘了exit退出来。
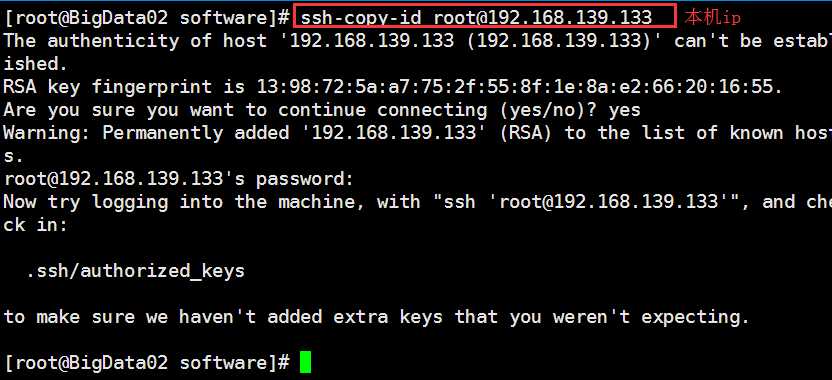
如果A主机想免密登录到B主机就可以在A主机执行
ssh-copy-id root@B主机的ip地址
这样A主机就可以免密登录到B主机
5.安装前的环境.
需要jdk环境 装环境不太熟悉的可以参考一下https://www.cnblogs.com/bybdz/p/9525540.html
使用Xshell连接Linux云主机或者虚拟机我这里用虚拟机,我使用Xshell连接Linux虚拟机
对Xshell感兴趣的可以看一下 https://www.cnblogs.com/bybdz/p/9311354.html
6.如何上传到Linux.
rz -e 把下载下来的Hadoop包传到Linux系统下(Xshell连接了Linux,别的我没试过,效果不保证)
如果输入rz -e 提示command not found,用 yum install lrzsz 安装 然后rz -e选择上传
或者直接拖拽上传
7.配置 hadoop-env.sh
先把上传过来的hadoop解压一下
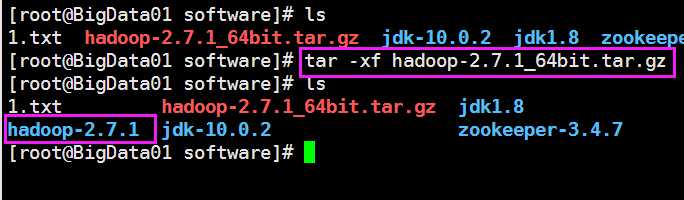
计入hadoop目录的ect目录下的hadoop目录下注意是hadoop目录下的ect/hadoop目录

然后: vim hadoop-env.sh 这个文件也是在hadoop目录下的ect/hadoop目录
修改 java_home路径和 hadoop_conf_dir 路径

自己的hadoop目录,后面的etc/hadoop别忘了写

然后执行:source hadoop-env.sh 让配置立即生效
8.修改 core-site.xml
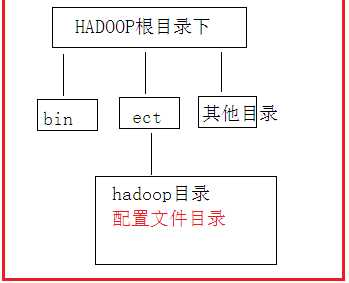
在 hadoop目录下 ,进入 etc/hadoop目录
以下的配置如果没有做说明,全都在Hadoop根目录下的etc目录下的hadoop目录下操作
现在我在我们本身就在这个目录下如下图:
执行: vim core-site.xml
最下面本来是这样的
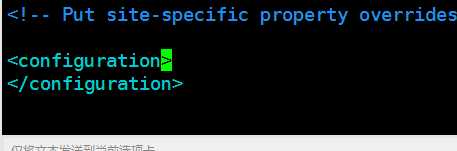
添加2个property节点,没有做说明的可以照着写,有说明的根据自己情况写
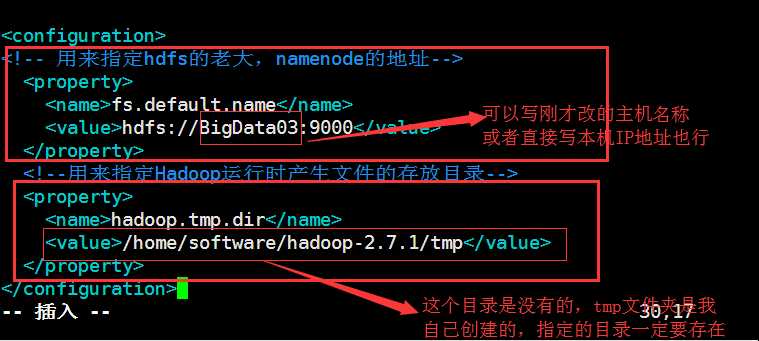
这个这顶的目录如果不存在的话一定要自己创建!!!
9.修改 hdfs-site.xml
配置如下:照着抄
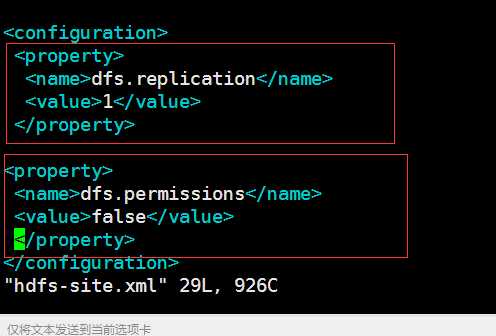
<!--如果是伪分布模式,此值是1-->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<!--设置hdfs的操作权限,false表示任何用户都可以在hdfs上操作文件-->
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
10.修改mapred-site.xml
这个文件初始时是没有的,有一个模板文件,mapred-site.xml.template
所以需要拷贝一份,并重命名为mapred-site.xml
执行:cp mapred-site.xml.template mapred-site.xml

配置如下
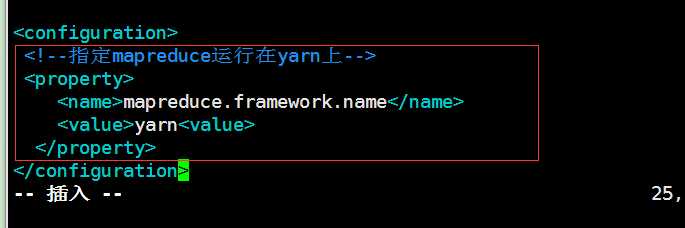
<property>
<!--指定mapreduce运行在yarn上-->
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
11.修改 yarn-site.xml
配置如下图
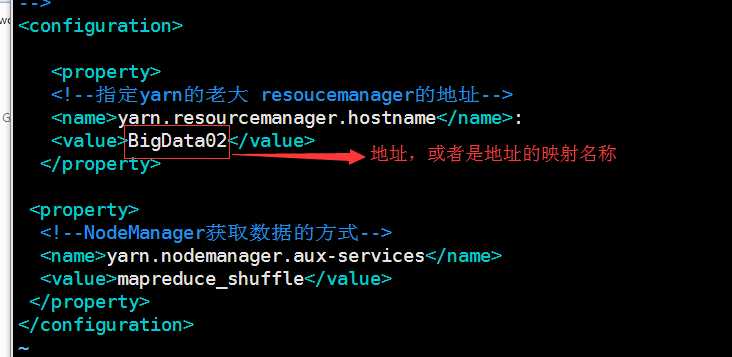
<configuration>
<property>
<!--指定yarn的老大 resoucemanager的地址-->
<name>yarn.resourcemanager.hostname</name>:
<value>hadoop01</value>
</property>
<property>
<!--NodeManager获取数据的方式-->
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<configuration>
12.配置slaves文件

13.配置hadoop的环境变量,JDK目录和HADOOP目录写自己的
vim /etc/profile 在最后添加
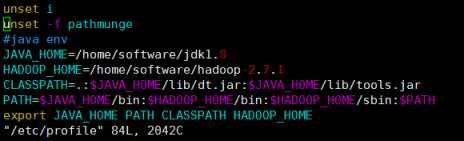
JDK目录,和HADOOP目录写自己的,CLASSPATH和PATH和export可以照着抄
JAVA_HOME=/home/software/jdk1.8
HADOOP_HOME=/home/software/hadoop-2.7.1
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
export JAVA_HOME PATH CLASSPATH HADOOP_HOME
source /etc/profile 使环境变量生效
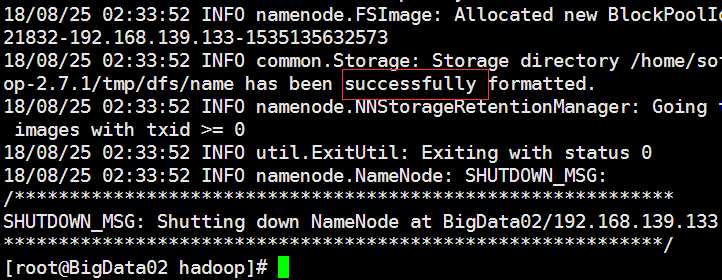
14.格式化namenode
执行:hadoop namenode -format
如果不好使,可以重启linux
当出现:successfully,证明格式化成功
15.启动Hadoop
因为配置了Hadoop环境变量,不需要到sbin目录下启动
直接执行:start-dfs.sh 启动hadoop相关的服务
出现如下图就成功了,如果少的化,可能是配置文件写错了,检查配置文件

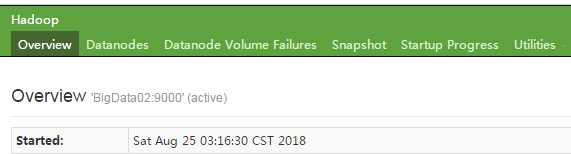
打开浏览器http://你的ip地址:50070/ 比如:http://192.168.139.133:50070/
会出现如下图,说明启动成功了
注:如果在启动时,报错:Cannot find configuration directory: /etc/hadoop
解决办法:编辑 etc/hadoop下的 hadoop-env.sh 文件,添加如下配置信息:
export HADOOP_CONF_DIR=/home/software/hadoop-2.7.1/etc/hadoop

然后执行 source hadoop-env.sh 使配置立即生效(在配置文件目录下)
执行:start-yarn.sh 启动yarn相关的服务
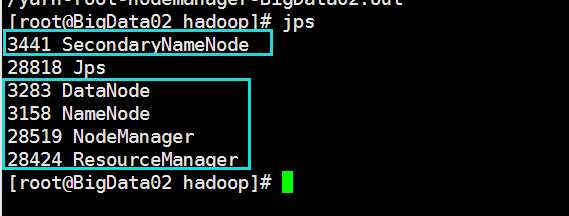
end 2018年8月25日
标签:val 关闭 directory 选择 兴趣 end 使用 取数 mic
原文地址:https://www.cnblogs.com/purple5252/p/12799351.html