标签:home follow 下载地址 数据集 网络 png 密钥 版本 官网
写在前面如果你想通过这篇博客在本地成功搭建 Hadoop 集群的话,你需要先跟着视频课程 三天入门大数据实操课程 在本地搭建集群环境,在这个视频课程中你需要学习的章节是:
请在看本篇博客之前务必学习完上面视频课程中章节,如果你能学习完 三天入门大数据实操课程 所有的章节的话就更好,因为你学完这个课程可以有以下三大收获:
Zookeeper 的官网:https://zookeeper.apache.org/
Zookeeper 所有版本的安装包下载地址:https://archive.apache.org/dist/zookeeper
这篇文章是基于 3.4.10 版本的 zookeeper 来安装的。
在 master 上执行的下面的命令来下载 zookeeper 的安装包:
cd ~/bigdata
wget https://archive.apache.org/dist/zookeeper/zookeeper-3.4.10/zookeeper-3.4.10.tar.gz然后执行下面的命令解压:
tar xf zookeeper-3.4.10.tar.gz然后在当前目录下有一个名为 zookeeper-3.4.10 的文件目录,这个就是 zookeeper 的安装目录。
进入 zookeeper 的安装目录:
cd ~/bigdata/zookeeper-3.4.10创建两个文件目录:
// 创建用于存储临时数据的目录
mkdir data
## 创建用于存储日志数据的目录
mkdir log执行命令,创建 zoo.cfg 文件
cd ~/bigdata/zookeeper-3.4.10/conf?
cp zoo_sample.cfg zoo.cfg修改 zoo.cfg 文件:
vi zoo.cfg修改如下配置:
dataDir=/root/bigdata/zookeeper-3.4.10/data
dataLogDir=/root/bigdata/zookeeper-3.4.10/log
server.0=master:8880:7770
server.1=slave1:8881:7771
server.2=slave2:8882:7772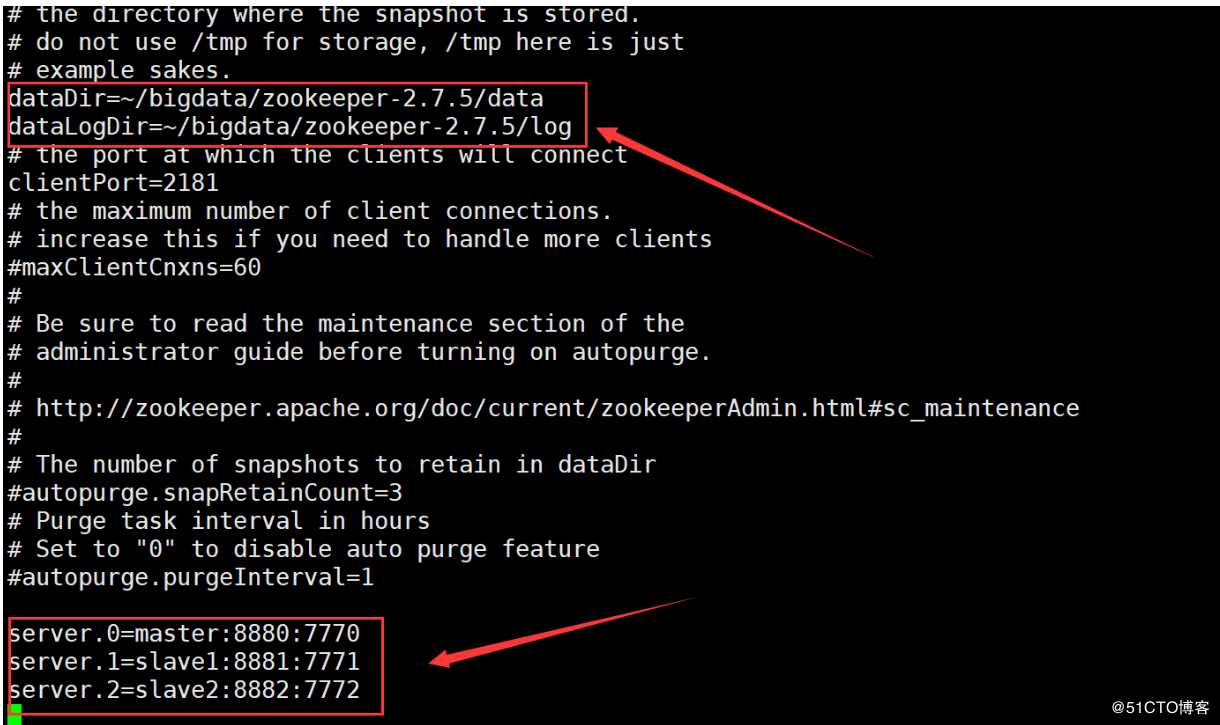
修改完后,保存退出。
在 master 上执行:
scp -r ~/bigdata/zookeeper-3.4.10/ root@slave1:~/bigdata/
scp -r ~/bigdata/zookeeper-3.4.10/ root@slave2:~/bigdata/
分别在 master、slave1、slave2 机器上的文件目录 ~/bigdata/zookeeper-3.4.10/data 下新增 myid 文件
touch ~/bigdata/zookeeper-3.4.10/data/myid然后分别在 3 台机器上修改 myid 文件:
vi ~/bigdata/zookeeper-3.4.10/data/myid在 master 机器上的内容为:0
在 slave1 机器上的内容为:1
在 slave2 机器上的内容为:2
分别在 master、slave1、slave2 机器上配置环境变量:
vi ~/.bash_profile增加如下内容:
export ZK_HOME=~/bigdata/zookeeper-3.4.10
PATH=$PATH:$HOME/bin:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$ZK_HOME/bin然后执行下面的命令使得配置生效:
source ~/.bash_profile分别在 master、slave1、slave2 机器上执行下面的命令:
zkServer.sh start然后我们分别在 3 台机器上执行下面的命令来验证 zookeeper 集群是否成功启动:
zkServer.sh status如果出现下面的界面说明安装成功:
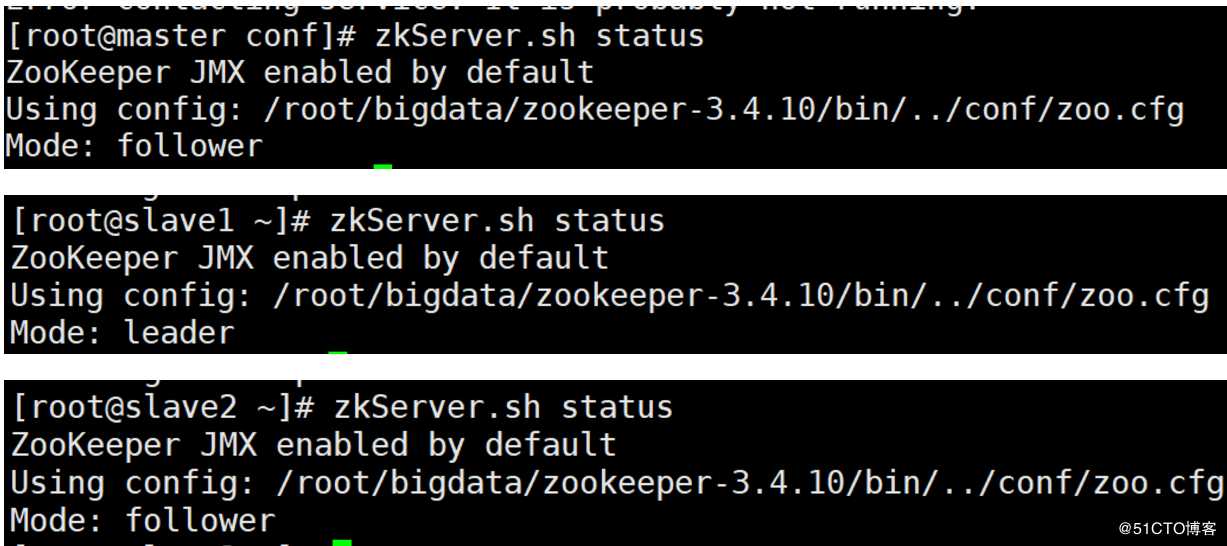
我们分别在 master、slave1、slave2 机器上执行下面的命令来关闭所有的 zookeeper 节点:
zkServer.sh stop标签:home follow 下载地址 数据集 网络 png 密钥 版本 官网
原文地址:https://blog.51cto.com/7639240/2491367