标签:相关性 targe nta 可见 影响 sha tor 构造 embed
AutoInt 核心网络结构如下图所示,注意可以在旁边加个Deep部分来组合,这里先省略。
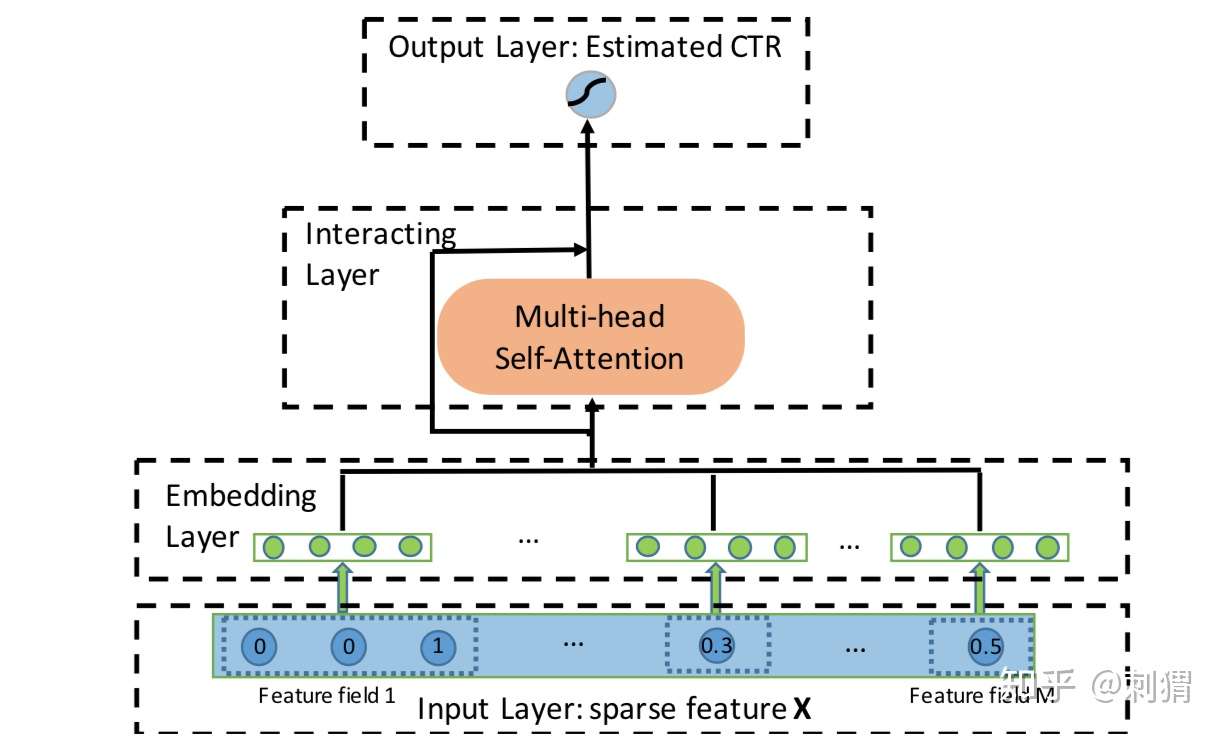 图1. AutoInt 核心网络结构
图1. AutoInt 核心网络结构
可以看到,一开始还是标准的嵌入层,不同点在于,对dense特征也进行embedding:每个dense Field 对应一个嵌入向量,乘以具体的dense特征值 作为其最终的emeddding。
Interacting层是AutoInt的核心,它使用经典的 Multi-head Self-Attention 来构造组合特征,即 key-value attention 的实现方式,具体结构如图2所示。
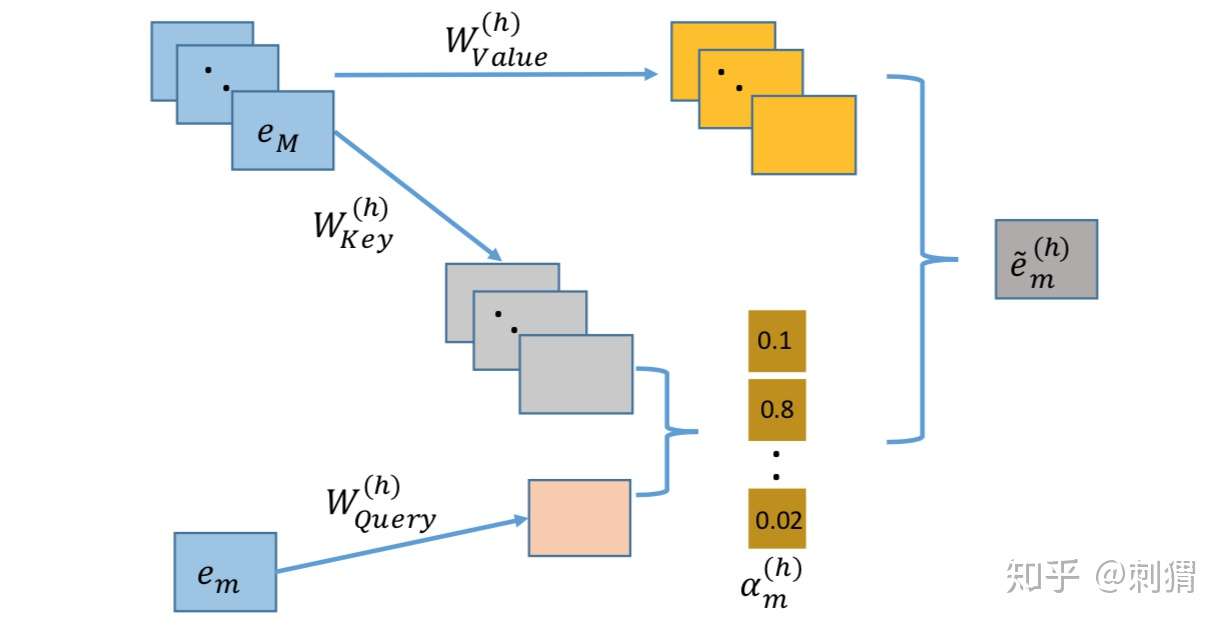 图2. key-value attention
图2. key-value attention
对 Self-Attention 比较熟悉的读者,从上图基本可以 get 到 AutoInt 到底是怎么干的了。每个Attention head 都对应着三个转换矩阵: 对于第 h 个 Attention head,当第 m 个嵌入向量
作为query时,其对应输出
为:
上式中, 是可选的相似度计算函数,文中简单地选择向量内积。注意,在每个Attention head中,每个嵌入向量
都有一次作为query的机会,从而学习到在这个head下的新表达
。
如果对 Attention 比较陌生,可以从一种比较直白的方式,联系一下搜索场景:一个 query 过来,先根据该 query 和一系列候选物的key 计算相似度,然后根据相似度返回候选物的具体value。现在回过去看上面的计算公式,是不是挺make sense了。
对第m个嵌入 ,作者简单拼接它在
个Attention head的输出,然后引入标准的残差连接作为其最终输出
:
最终的预测输出为:
其中
,
表示sigmoid函数。
文中采用logloss作为损失函数。另外,虽然这里只展示了单层 Interacting Layer,AutoInt 可以叠加多个这样的层,构造更高阶的组合特征。当然,也可以在旁边搭个Deep层一起合作。
单层 Interacting 的AutoInt的时间复杂度为 ,对比单层 MLP,假设神经元个数为N,时间复杂度为
。通常
的值比较小,因此时间效率不会太差。
数据集 文中使用四个公开的数据集,其中Criteo、Avazu是标准的CTR数据集;KDD12用于预估点击数量,这里将非零点击样本作为正例;MovieLens-1M是rate=1-5的打分数据集,令rate>3为正例,rate<3为负例,并且删除rate=3的样本避免干扰。
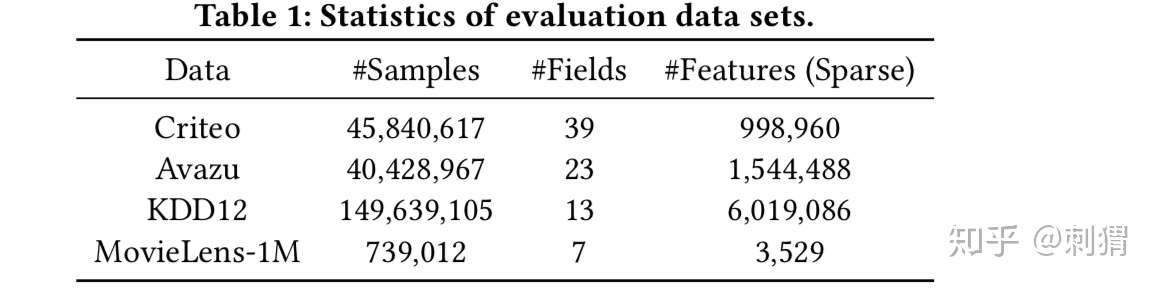
实验设置
实验结果
实验1 ——单独模块的实验结果 CrossNet、CIN分别为Deep&Cross、xDeepFM的单独模块,另外,AutoInt与DeepCrossing都使用了残差设计,区别在于DeepCrossing使用普通的MLP,相比之下可见Interacting Layer的优势。
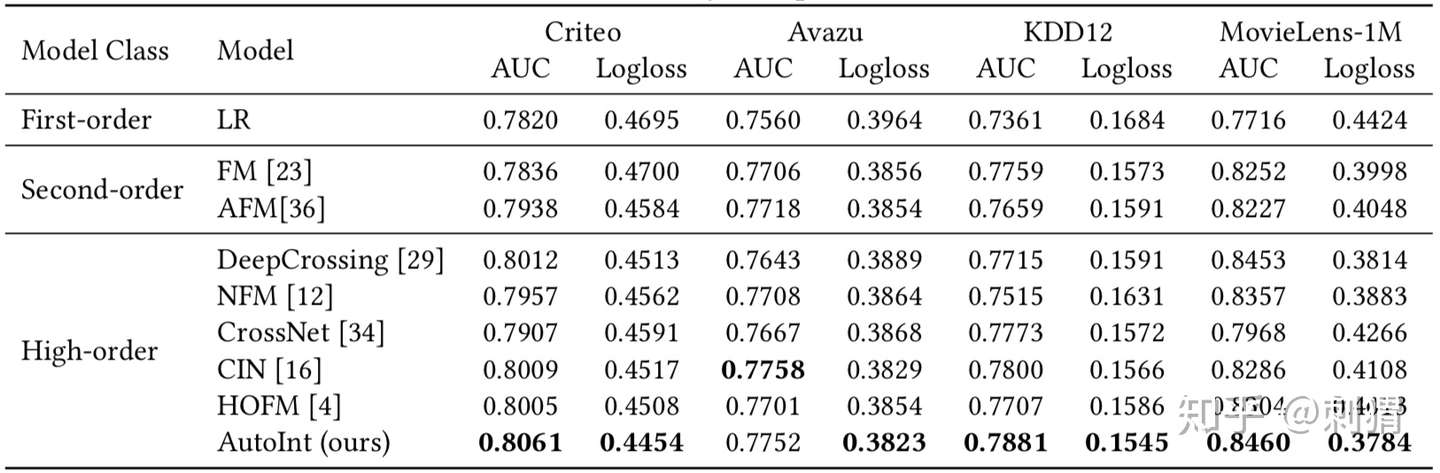 表1
表1
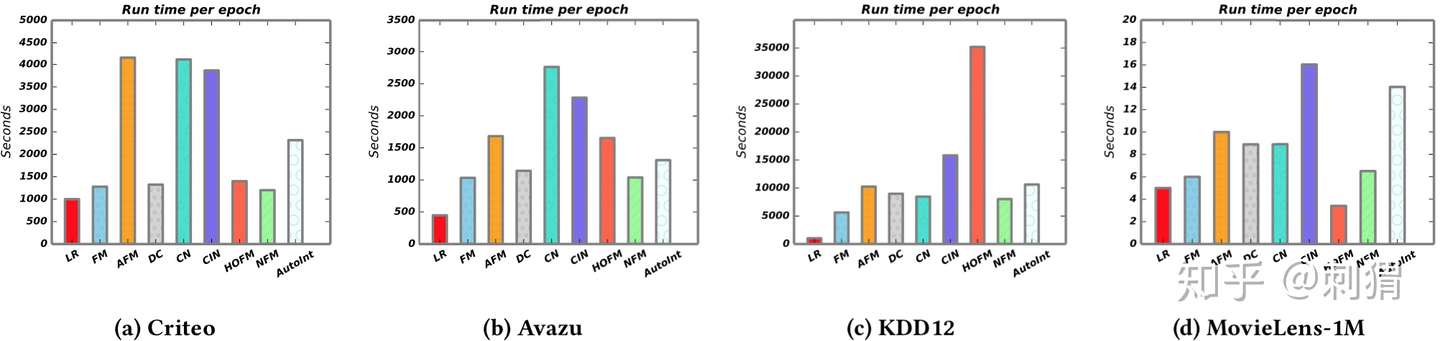
实验2——性能对比

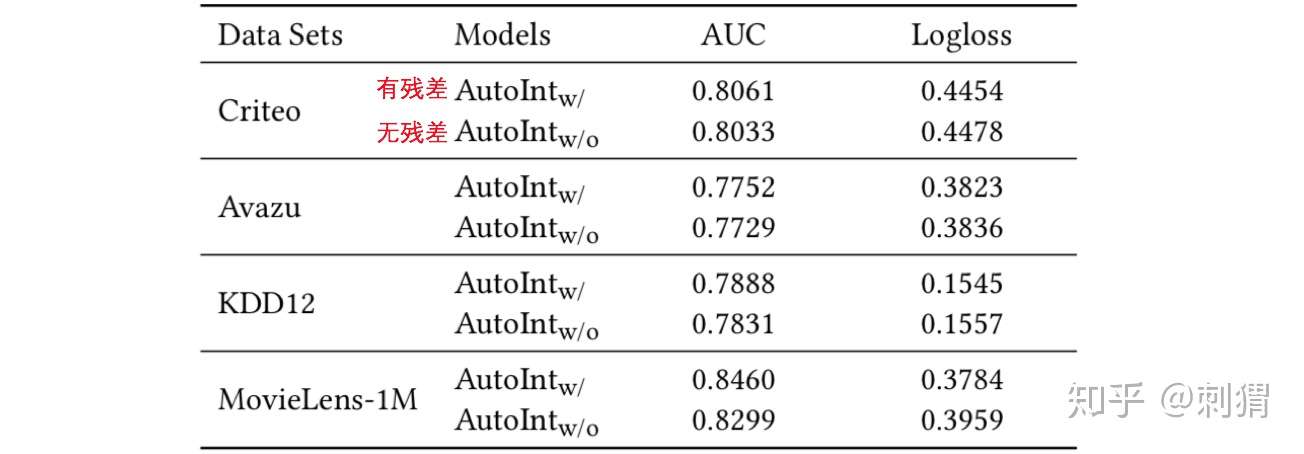
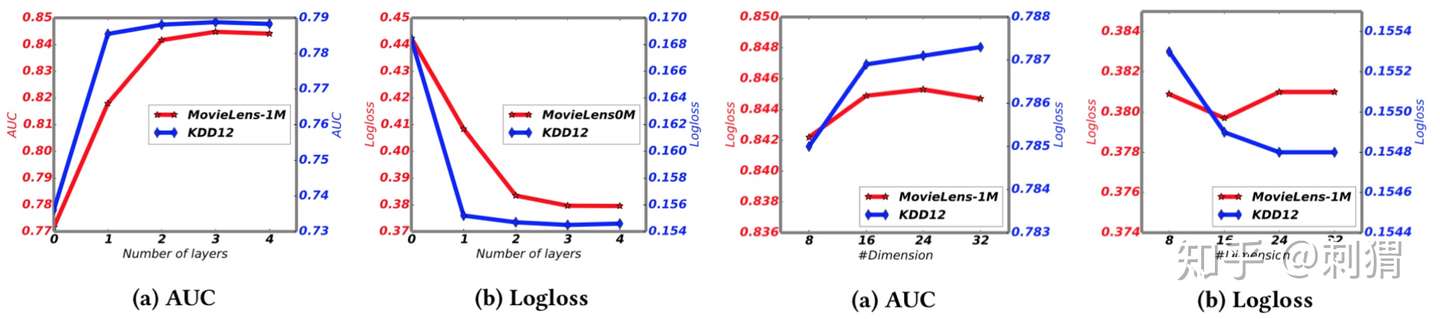
实验3 ——残差设计、Interacting层数、嵌入维度d 对 AutoInt影响 从实验结果可见,残差提升很明显,Interacting层数不用太多,可在2-4之间。
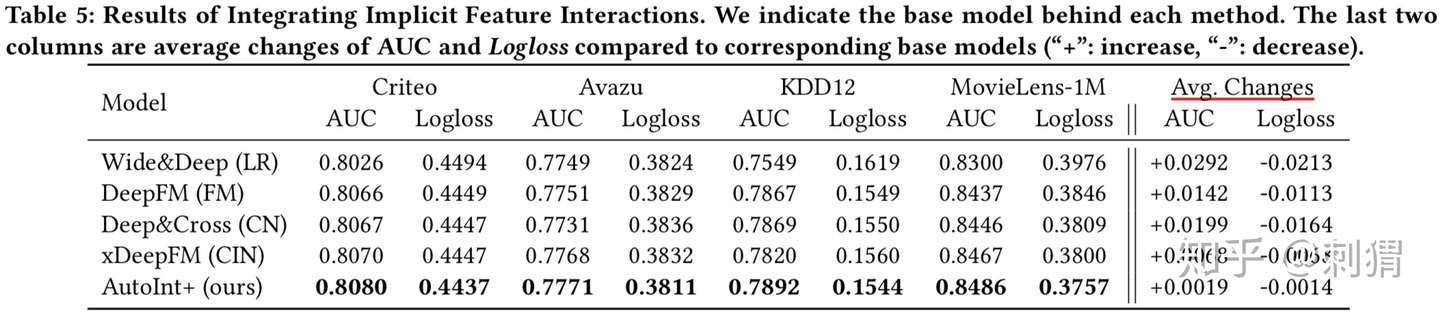
实验4——相关模型都加入Deep部分 AutoInt依然最优。值得关注的一点是,相比其他模型,AutoInt 加入 Deep后 的性能提升幅度是最小的,可见AutoInt的power。
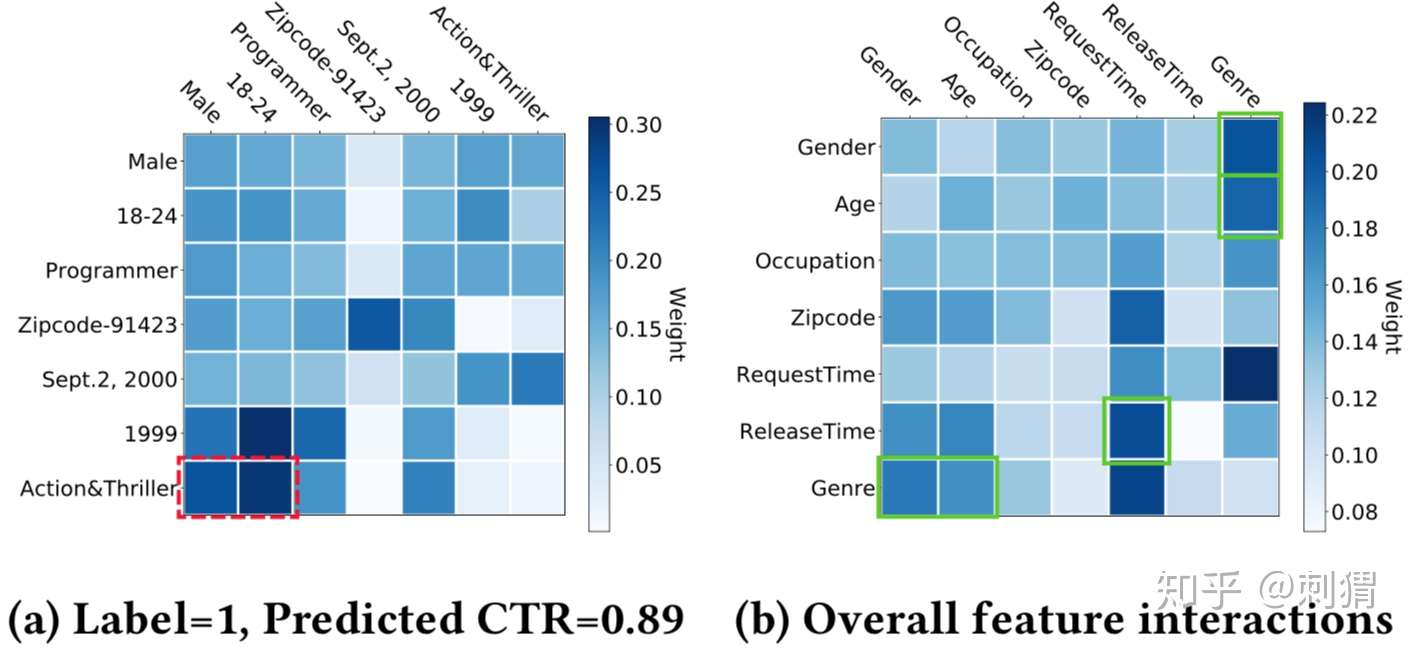
实验5——推荐结果的可解释性
文中将第一层的attention score看作两个field的相关性,在MovieLens中,取一个正样本,可视化结果如下图 a 所示,整个数据集的attention score平均结果如图 b 所示。作者框出了几个看起来很meaningful的高score组合,说明其良好的解释性。
《AutoInt:基于Multi-Head Self-Attention构造高阶特征》
标签:相关性 targe nta 可见 影响 sha tor 构造 embed
原文地址:https://www.cnblogs.com/cx2016/p/12800394.html