标签:匹配 大会 hash tps https 基础 场景 http 针对
Redis在应用中的存在一般是以缓存的形式,但是在某些应用场景也可能会涉及到需要拿出大量keys的情况,一般全盘扫描只需要使用keys *就可以拿出所有的key,但是keys指令有很明显的缺陷。
1.没有sql中类似offset等指令,无法分批
2.keys是直接遍历,复杂度O(n),全表数量大会造成整个Redis的卡顿
在Redis中,能够实现以上要求的则是scan,scan和keys最大区别就在于,scan可以分批取数据,类似sql中的分页,总结来说scan有以下几个特点:
1.复杂度是O(n),但是scan通过游标分步进行,不会卡线程
2.提供limit参数,可控制每次返回的条数,但是并不保证一定会返回对应条数,或多或少,这个和redis存储的hashmap结构有关
3.和keys一样,提供了匹配选项
4.通过游标保存状态
5.返回结果在某些条件下会有重复,这个主要是存在于扩容迁移的时候
6.在游标继续向下遍历的途中,加入有修改或者新增的数据,并不保证一定能遍历到
7.遍历结束的依据和返回的数据数量无关,只和游标有关,游标为0时表示结束
scan的基本语法是SCAN cursor [MATCH pattern] [COUNT count],下面通过这个指令来尝试遍历一下一个拥有1000个key的Redis:
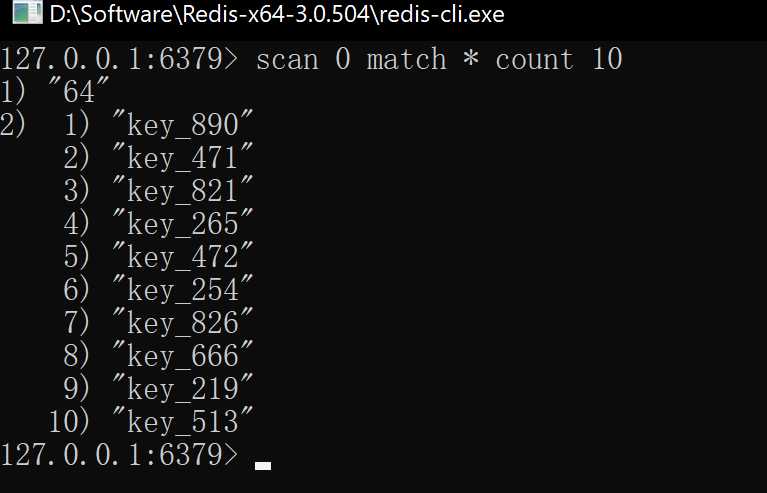
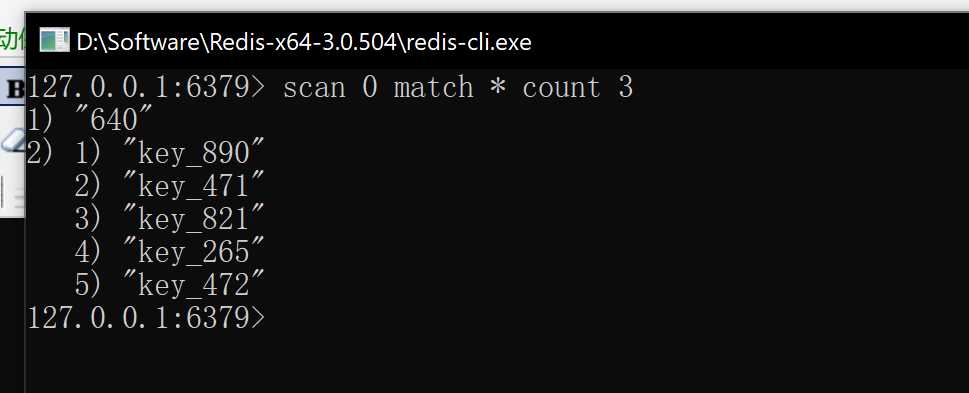
可以看到通过传入count参数可以将返回的数据控制,但是返回的数据个数并不一定是传入count,对于redis来说,传入的count只是一个提示,告知redis扫描的个数(这个在文章尾部有介绍)。
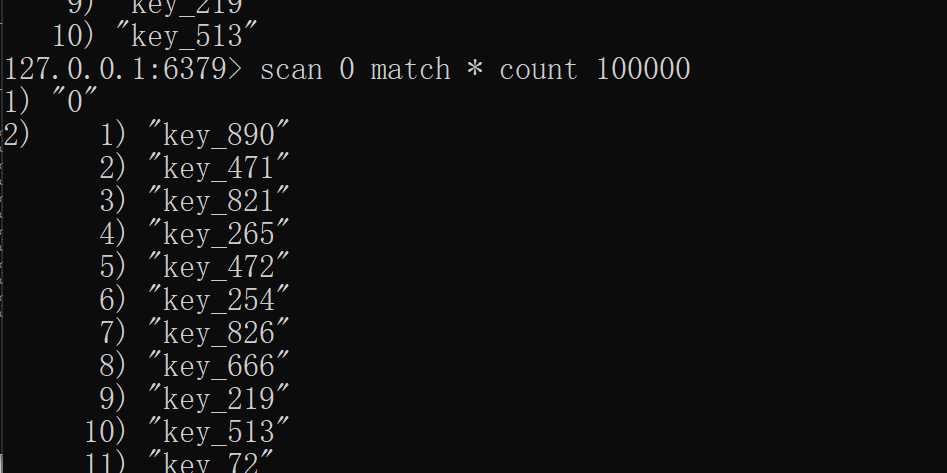
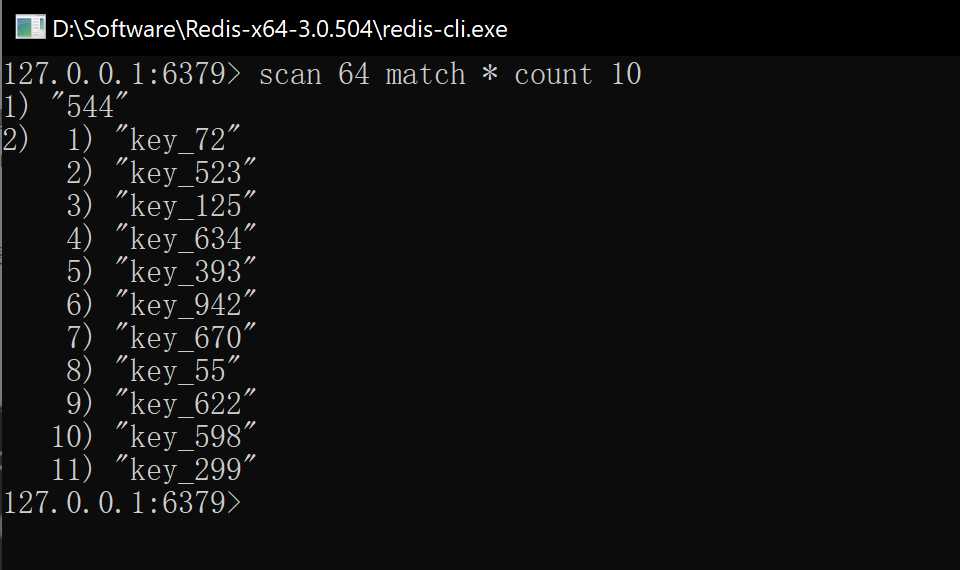
同时在上图中,我们的redis一共有1000个key,在第三张图中可以看到,但我们的count>key个数的时候,返回的第一个结果的值是“0”,而0也代表着本次扫描已经将redis符合条件的key全部扫描完成,而不为0则表示还有剩余的数据可以继续扫描,如下图所示,带入第一张图中的“64”:
首先我们明确,在redis中,数据是以hashmap的形式存在,如下图所示:
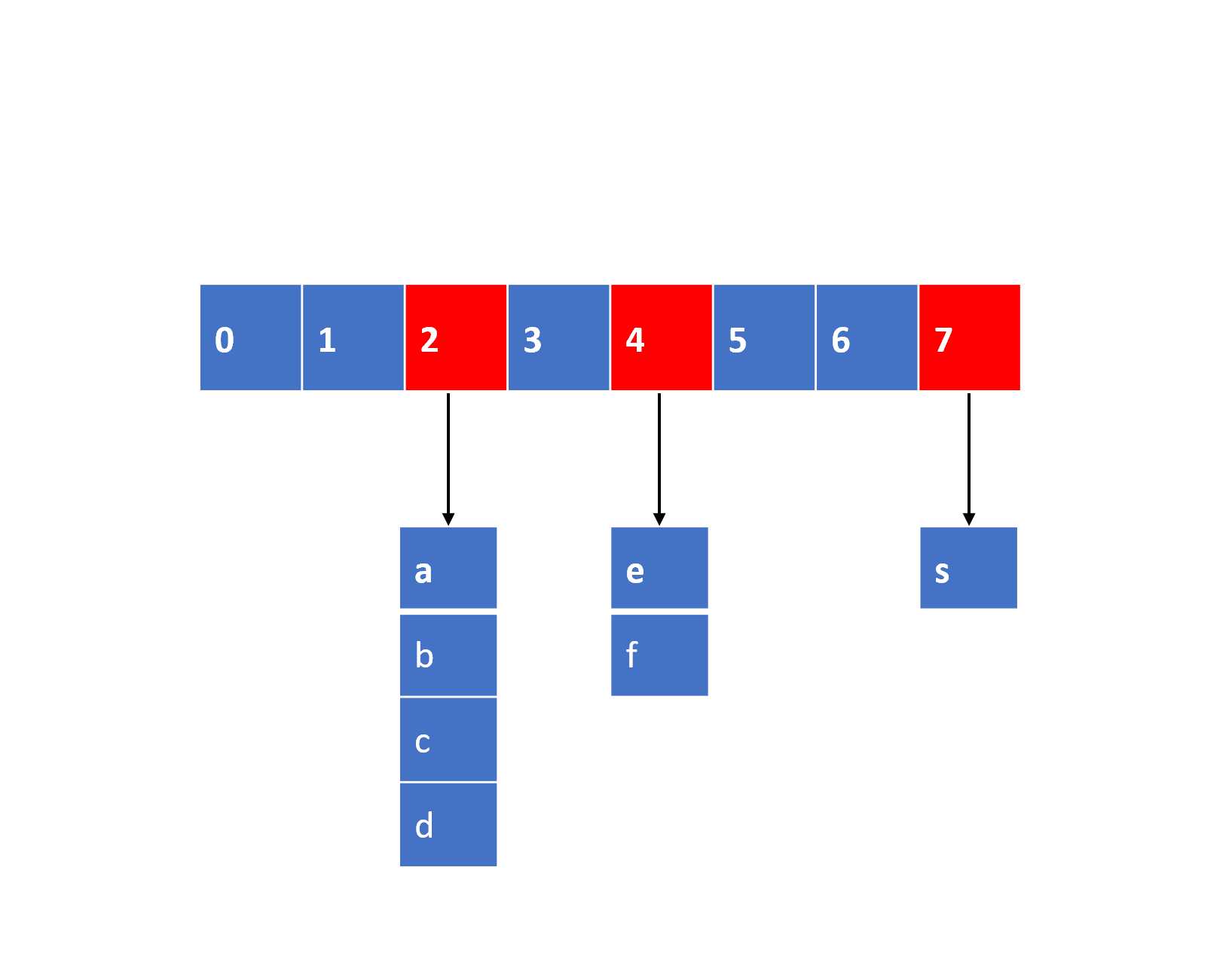
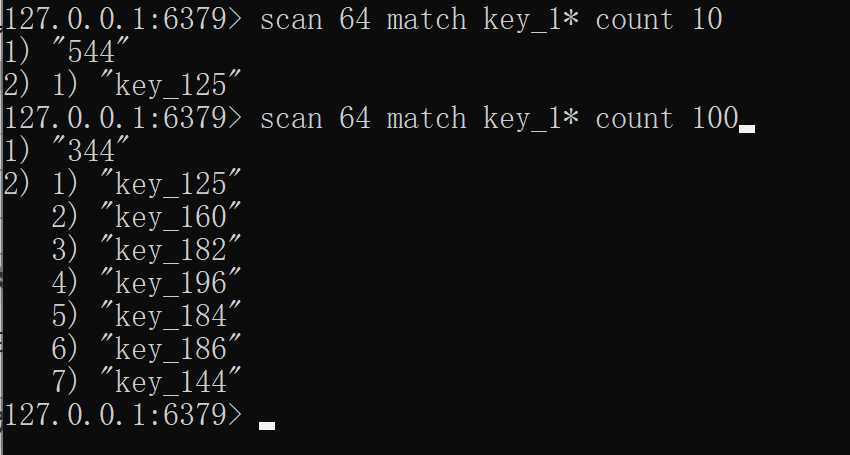
而scan指令返回的游标就是其中一维数组的位置的索引,详细参考Redis底层原理-Key存储结构中所作的介绍,在正常的逻辑(redis不存在扩容缩容等等)情况下,scan直接按照数组的下标进行遍历,limit则是需要扫描的数组的下标个数,返回的数量则是由数组每个下标对应的链表中能够匹配到多少数据为准,下面两个图在我们传入match参数时候显得更加明显:
在Redis中,scan除了遍历普通的key以外,还可以针对性的对其他基础数据结构进行遍历,比如zscan对应zset集合元素,hscan对应hash的元素,sscan对应set集元素,他们的原理和scan相同,例如hash底层使用了字典的数据结构,zset则是一个value指向同一个元素的特殊hash,zset也使用字典结构来存储所有的元素内容。
标签:匹配 大会 hash tps https 基础 场景 http 针对
原文地址:https://www.cnblogs.com/TuringLi/p/12805638.html