标签:png keep 开源 代码 出现 zha add 客户 分布
Solr 是Apache下的一个顶级开源项目,采用Java开发,它是基于Lucene的全文搜索服务器。
Solr提供了比Lucene更为丰富的查询语言,同时实现了可配置、可扩展,并对索引、搜索性能进行了优化。
Solr可以独立运行,运行在Jetty、Tomcat等这些Servlet容器中,Solr 索引的实现方法很简单,用 POST 方法向 Solr 服务器发送一个描述 Field 及其内容的 XML 文档,
Solr根据xml文档添加、删除、更新索引 。Solr 搜索只需要发送 HTTP GET 请求,然后对 Solr 返回Xml、json等格式的查询结果进行解析,组织页面布局。
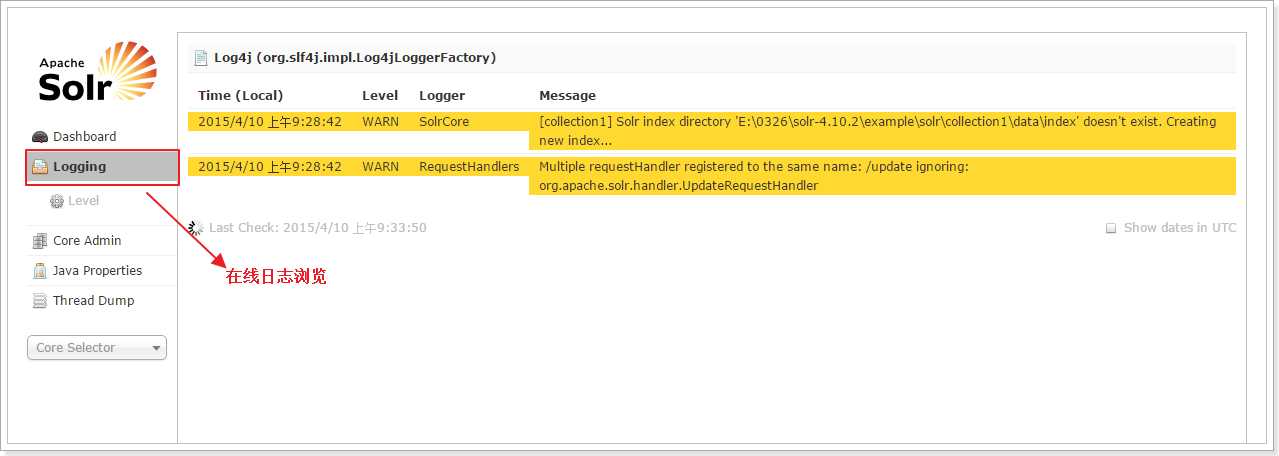
Solr不提供构建UI的功能,Solr提供了一个管理界面,通过管理界面可以查询Solr的配置和运行情况。
从Solr官方网站(http://lucene.apache.org/solr/ )下载Solr4.10.3,根据Solr的运行环境,
Linux下需要下载lucene-4.10.3.tgz,windows下需要下载lucene-4.10.3.zip。
Solr使用指南可参考:https://wiki.apache.org/solr/FrontPage。
下载lucene-4.10.3.zip并解压:
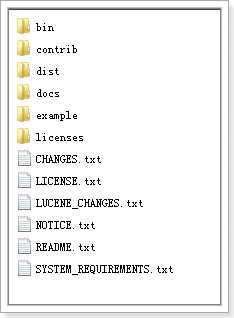
bin:solr的运行脚本 contrib:solr的一些贡献软件/插件,用于增强solr的功能。 dist:该目录包含build过程中产生的war和jar文件,以及相关的依赖文件。 docs:solr的API文档 example:solr工程的例子目录: l example/solr: 该目录是一个包含了默认配置信息的Solr的Core目录。 l example/multicore: 该目录包含了在Solr的multicore中设置的多个Core目录。 l example/webapps: 该目录中包括一个solr.war,该war可作为solr的运行实例工程。 licenses:solr相关的一些许可信息
solr 需要运行在一个Servlet容器中,Solr4.10.3要求jdk使用1.7以上,Solr默认提供Jetty(java写的Servlet容器),本教程使用Tocmat作为Servlet容器,环境如下:
Solr:Solr4.10.3
Jdk:jdk1.7.0_72
Tomcat:apache-tomcat-7.0.53
1.将dist\solr-4.10.3.war拷贝到Tomcat的webapp目录下改名为solr.war
2.启动tomcat后,solr.war自动解压,将原来的solr.war删除。
3.拷贝example\lib\ext 目录下所有jar包到Tomcat的webapp\solr\WEB-INF\lib目录下
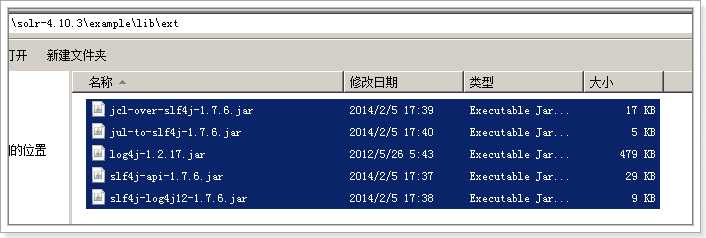
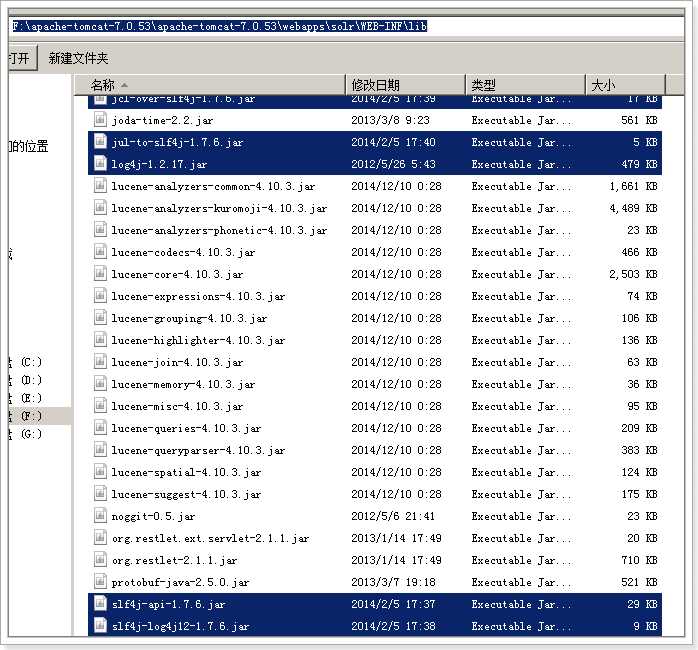
4.拷贝log4j.properties文件
在 Tomcat下webapps\solr\WEB-INF目录中创建文件 classes文件夹,
复制Solr目录下example\resources\log4j.properties至Tomcat下webapps\solr\WEB-INF\classes目录
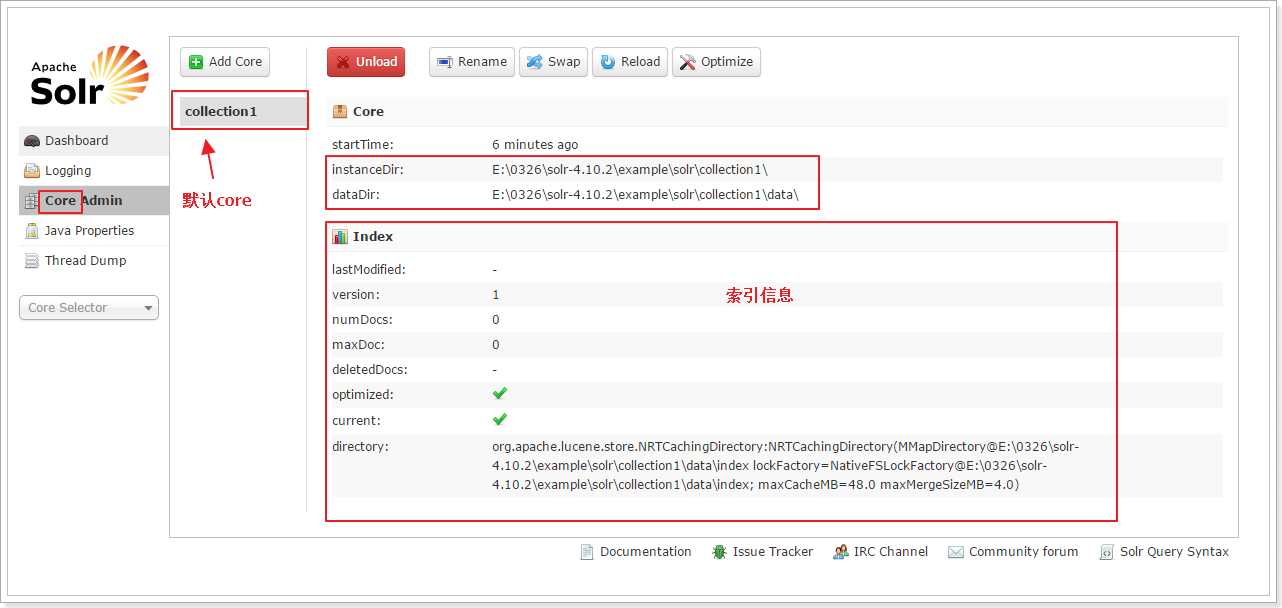
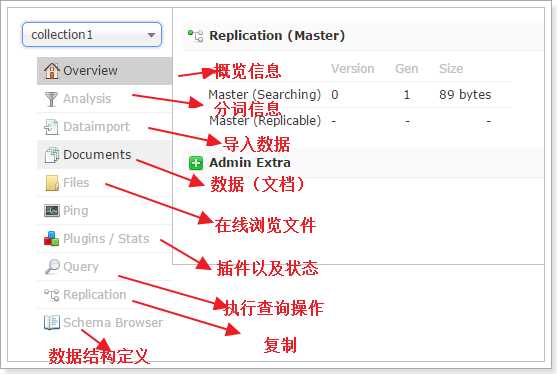
5.创建solrhome及配置solrcore的solrconfig.xml文件
6.修改Tomcat目录 下webapp\solr\WEB-INF\web.xml文件,如下所示:
设置Solr home
<!--配置jndi告诉solr工程我们的solrhome的位置-->
<env-entry>
<env-entry-name>solr/home</env-entry-name>
<env-entry-value>D:/temp/solr/solrhome</env-entry-value>
<env-entry-type>java.lang.String</env-entry-type>
</env-entry>
拷贝IKAnalyzer的文件到Tomcat下Solr目录中;
将IKAnalyzer2012FF_u1.jar拷贝到 Tomcat的webapps/solr/WEB-INF/lib 下。
在Tomcat的webapps/solr/WEB-INF/下创建classes目录
将IKAnalyzer.cfg.xml、ext_stopword.dic mydict.dic copy到 Tomcat的
webapps/solr/WEB-INF/classes
注意:ext_stopword.dic 和mydict.dic必须保存成无BOM的utf-8类型。
修改schema.xml文件
修改Solr的schema.xml文件,添加FieldType:
<fieldType name="text_ik" class="solr.TextField"> <analyzer class="org.wltea.analyzer.lucene.IKAnalyzer"/> </fieldType>
设置业务系统Field
<field name="item_title" type="text_ik" indexed="true" stored="true"/> <field name="item_sell_point" type="text_ik" indexed="true" stored="true"/> <field name="item_price" type="long" indexed="true" stored="true"/> <field name="item_image" type="string" indexed="false" stored="true" /> <field name="item_category_name" type="string" indexed="true" stored="true" /> <field name="item_desc" type="text_ik" indexed="true" stored="false" /> <field name="item_keywords" type="text_ik" indexed="true" stored="false" multiValued="true"/> <copyField source="item_title" dest="item_keywords"/> <copyField source="item_sell_point" dest="item_keywords"/> <copyField source="item_category_name" dest="item_keywords"/> <copyField source="item_desc" dest="item_keywords"/>
顾名思义zookeeper就是动物园管理员,他是用来管hadoop(大象)、Hive(蜜蜂)、pig(小猪)的管理员, Apache Hbase和 Apache Solr 的分布式集群都用到了zookeeper;
Zookeeper:是一个分布式的、开源的程序协调服务,是hadoop项目下的一个子项目。
(1)配置管理
在我们的应用中除了代码外,还有一些就是各种配置。比如数据库连接等。一般我们都是使用配置文件的方式,在代码中引入这些配置文件。
但是当我们只有一种配置,只有一台服务器,并且不经常修改的时候,使用配置文件是一个很好的做法,但是如果我们配置非常多,有很多服务器都需要这个配置,
而且还可能是动态的话使用配置文件就不是个好主意了。这个时候往往需要寻找一种集中管理配置的方法,我们在这个集中的地方修改了配置,所有对这个配置感兴趣的都可以获得变更。
比如我们可以把配置放在数据库里,然后所有需要配置的服务都去这个数据库读取配置。但是,因为很多服务的正常运行都非常依赖这个配置,
所以需要这个集中提供配置服务的服务具备很高的可靠性。一般我们可以用一个集群来提供这个配置服务,但是用集群提升可靠性,那如何保证配置在集群中的一致性呢?
这个时候就需要使用一种实现了一致性协议的服务了。Zookeeper就是这种服务,它使用Zab这种一致性协议来提供一致性。
现在有很多开源项目使用Zookeeper来维护配置,比如在HBase中,客户端就是连接一个Zookeeper,获得必要的HBase集群的配置信息,然后才可以进一步操作。
还有在开源的消息队列Kafka中,也使用Zookeeper来维护broker的信息。在Alibaba开源的SOA框架Dubbo中也广泛的使用Zookeeper管理一些配置来实现服务治理。
(2)名字服务
名字服务这个就很好理解了。比如为了通过网络访问一个系统,我们得知道对方的IP地址,但是IP地址对人非常不友好,这个时候我们就需要使用域名来访问。
但是计算机是不能是别域名的。怎么办呢?如果我们每台机器里都备有一份域名到IP地址的映射,这个倒是能解决一部分问题,但是如果域名对应的IP发生变化了又该怎么办呢?
于是我们有了DNS这个东西。我们只需要访问一个大家熟知的(known)的点,它就会告诉你这个域名对应的IP是什么。在我们的应用中也会存在很多这类问题,
特别是在我们的服务特别多的时候,如果我们在本地保存服务的地址的时候将非常不方便,但是如果我们只需要访问一个大家都熟知的访问点,
这里提供统一的入口,那么维护起来将方便得多了。
(3)分布式锁
其实在第一篇文章中已经介绍了Zookeeper是一个分布式协调服务。这样我们就可以利用Zookeeper来协调多个分布式进程之间的活动。
比如在一个分布式环境中,为了提高可靠性,我们的集群的每台服务器上都部署着同样的服务。但是,一件事情如果集群中的每个服务器都进行的话,那相互之间就要协调,编程起来将非常复杂。
而如果我们只让一个服务进行操作,那又存在单点。通常还有一种做法就是使用分布式锁,在某个时刻只让一个服务去干活,当这台服务出问题的时候锁释放,立即fail over到另外的服务。
这在很多分布式系统中都是这么做,这种设计有一个更好听的名字叫Leader Election(leader选举)。比如HBase的Master就是采用这种机制。
但要注意的是分布式锁跟同一个进程的锁还是有区别的,所以使用的时候要比同一个进程里的锁更谨慎的使用。
(4)集群管理
在分布式的集群中,经常会由于各种原因,比如硬件故障,软件故障,网络问题,有些节点会进进出出。有新的节点加入进来,也有老的节点退出集群。
这个时候,集群中其他机器需要感知到这种变化,然后根据这种变化做出对应的决策。比如我们是一个分布式存储系统,有一个中央控制节点负责存储的分配,当
有新的存储进来的时候我们要根据现在集群目前的状态来分配存储节点。这个时候我们就需要动态感知到集群目前的状态。还有,比如一个分布式的SOA架构中,服务是一个集群提供的,
当消费者访问某个服务时,就需要采用某种机制发现现在有哪些节点可以提供该服务(这也称之为服务发现,
比如Alibaba开源的SOA框架Dubbo就采用了Zookeeper作为服务发现的底层机制)。还有开源的Kafka队列就采用了Zookeeper作为Cosnumer的上下线管理。
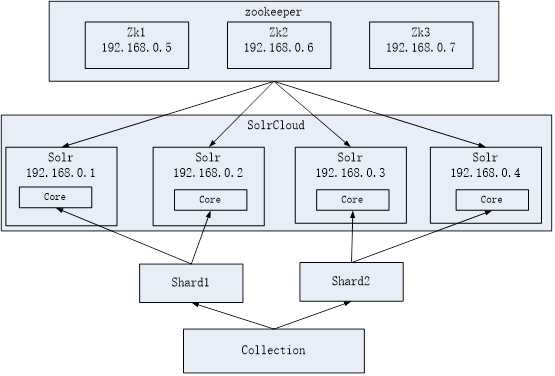
SolrCloud为了降低单机的处理压力,需要由多台服务器共同来完成索引和搜索任务。实现的思路是将索引数据进行Shard(分片)拆分,每个分片由多台的服务器共同完成,当一个索引或搜索请求过来时会分别从不同的Shard的服务器中操作索引。
SolrCloud需要Solr基于Zookeeper部署,Zookeeper是一个集群管理软件,由于SolrCloud需要由多台服务器组成,由zookeeper来进行协调管理。
下图是一个SolrCloud应用的例子:
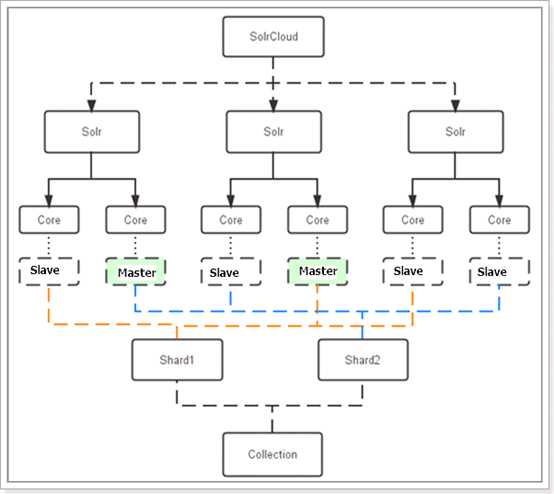
对上图进行图解,如下:
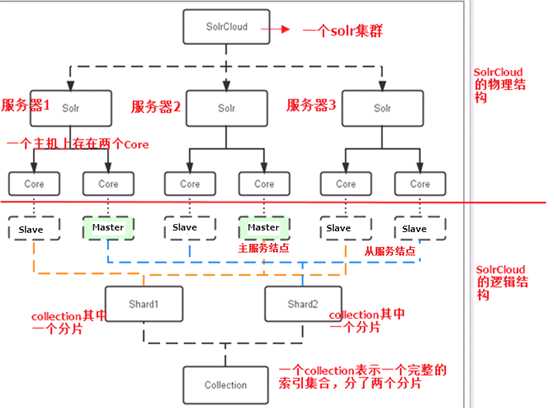
三个Solr实例( 每个实例包括两个Core),组成一个SolrCloud。
索引集合包括两个Shard(shard1和shard2),shard1和shard2分别由三个Core组成,其中一个Leader两个Replication,
Leader是由zookeeper选举产生,zookeeper控制每个shard上三个Core的索引数据一致,解决高可用问题。
用户发起索引请求分别从shard1和shard2上获取,解决高并发问题。
Collection在SolrCloud集群中是一个逻辑意义上的完整的索引结构。它常常被划分为一个或多个Shard(分片),它们使用相同的配置信息。
比如:针对商品信息搜索可以创建一个collection。
collection=shard1+shard2+....+shardX
每个Core是Solr中一个独立运行单位,提供 索引和搜索服务。一个shard需要由一个Core或多个Core组成。
由于collection由多个shard组成所以collection一般由多个core组成。
Master是master-slave结构中的主结点(通常说主服务器),Slave是master-slave结构中的从结点(通常说从服务器或备服务器)。
同一个Shard下master和slave存储的数据是一致的,这是为了达到高可用目的。
Collection的逻辑分片。每个Shard被化成一个或者多个replication,通过选举确定哪个是Leader。
本教程的这套安装是单机版的安装,所以采用伪集群的方式进行安装,如果是真正的生产环境,将伪集群的ip改下就可以了,步骤是一样的。
SolrCloud结构图如下:
CentOS-6.4-i386-bin-DVD1.iso
jdk-7u72-linux-i586.tar.gz
apache-tomcat-7.0.47.tar.gz
zookeeper-3.4.6.tar.gz
solr-4.10.3.tgz
第一步:解压zookeeper,tar -zxvf zookeeper-3.4.6.tar.gz将zookeeper-3.4.6拷贝到/usr/local/solrcloud下,复制三份分别并将目录名改为zookeeper1、zookeeper2、zookeeper3
第二步:进入zookeeper1文件夹,创建data目录。并在data目录中创建一个myid文件内容为“1”(echo 1 >> data/myid)。
第三步:进入conf文件夹,把zoo_sample.cfg改名为zoo.cfg
第四步:修改zoo.cfg。
修改:
dataDir=/usr/local/solrcloud/zookeeper1/data
clientPort=2181(zookeeper2中为2182、zookeeper3中为2183)
添加:
server.1=192.168.25.154:2881:3881
server.2=192.168.25.154:2882:3882
server.3=192.168.25.154:2883:3883
# The number of milliseconds of each tick tickTime=2000 # The number of ticks that the initial # synchronization phase can take initLimit=10 # The number of ticks that can pass between # sending a request and getting an acknowledgement syncLimit=5 # the directory where the snapshot is stored. # do not use /tmp for storage, /tmp here is just # example sakes. dataDir=/usr/local/solrcloud/zookeeper1/data # the port at which the clients will connect clientPort=2181 # the maximum number of client connections. # increase this if you need to handle more clients #maxClientCnxns=60 # # Be sure to read the maintenance section of the # administrator guide before turning on autopurge. # # http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance # # The number of snapshots to retain in dataDir #autopurge.snapRetainCount=3 # Purge task interval in hours # Set to "0" to disable auto purge feature #autopurge.purgeInterval=1 server.1=192.168.25.154:2881:3881 server.2=192.168.25.154:2882:3882 server.3=192.168.25.154:2883:3883
第五步:对zookeeper2、3中的设置做第二步至第四步修改。
zookeeper2:
myid内容为2
dataDir=/usr/local/solrcloud/zookeeper2/data
clientPort=2182
Zookeeper3:
的myid内容为3
dataDir=/usr/local/solrcloud/zookeeper3/data
clientPort=2183
第六步:启动三个zookeeper
/usr/local/solrcloud/zookeeper1/bin/zkServer.sh start
/usr/local/solrcloud/zookeeper2/bin/zkServer.sh start
/usr/local/solrcloud/zookeeper3/bin/zkServer.sh start
查看集群状态:
/usr/local/solrcloud/zookeeper1/bin/zkServer.sh status
/usr/local/solrcloud/zookeeper2/bin/zkServer.sh status
/usr/local/solrcloud/zookeeper3/bin/zkServer.sh status
第七步:开启zookeeper用到的端口,或者直接关闭防火墙。
service iptables stop
第一步:将apache-tomcat-7.0.47.tar.gz解压
tar -zxvf apache-tomcat-7.0.47.tar.gz
第二步:把解压后的tomcat复制到/usr/local/solrcloud/目录下复制四份。
/usr/local/solrcloud/tomcat1
/usr/local/solrcloud/tomcat2
/usr/local/solrcloud/tomcat3
/usr/local/solrcloud/tomcat4
第三步:修改tomcat的server.xml
vim tomcat2/conf/server.xml,把其中的端口后都加一。保证两个tomcat可以正常运行不发生端口冲突。
solrCloud部署依赖zookeeper,需要先启动每一台zookeeper服务器。
由于zookeeper统一管理solr的配置文件(主要是schema.xml、solrconfig.xml), solrCloud各各节点使用zookeeper管理的配置文件。
将上边部署的solr单机的conf拷贝到/home/solr下。
执行下边的命令将/home/solr/conf下的配置文件上传到zookeeper(此命令为单条命令,虽然很长o(╯□╰)o)。
此命令在solr-4.10.3/example/scripts/cloud-scripts/目录下:
./zkcli.sh -zkhost 192.168.25.154:2181,192.168.25.154:2182,192.168.25.154:2183 -cmd upconfig -confdir /usr/local/solrcloud/solrhome1/collection1/conf -confname myconf
登陆zookeeper服务器查询配置文件:
cd /usr/local/zookeeper/bin/
./zkCli.sh

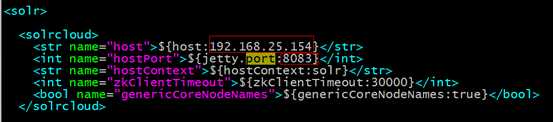
修改每个solrhome的solr.xml文件。将host改成虚拟机ip地址,port改成对应的tomcat的端口号。
修改每一台solr的tomcat 的 bin目录下catalina.sh文件中加入DzkHost指定zookeeper服务器地址:
JAVA_OPTS="-DzkHost=192.168.25.154:2181,192.168.25.154:2182,192.168.25.154:2183"
(可以使用vim的查找功能查找到JAVA_OPTS的定义的位置,然后添加)
启动每一台solr的tomcat服务。
访问任意一台solr,左侧菜单出现Cloud:
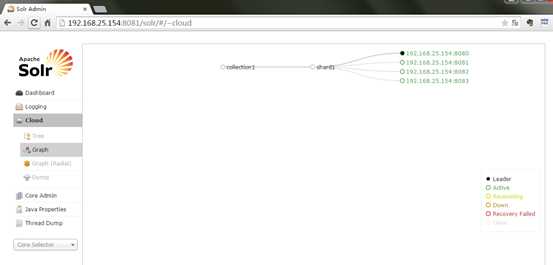
上图中的collection1集群只有一片,可以通过下边的方法配置新的集群。
如果集群中有四个solr节点创建新集群collection2,将集群分为两片,每片两个副本。
http://192.168.25.154:8080/solr/admin/collections?action=CREATE&name=collection2&numShards=2&replicationFactor=2
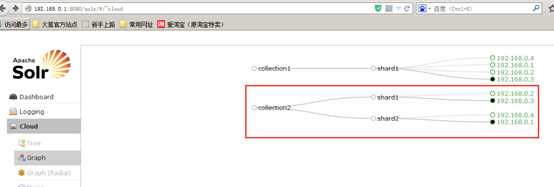
删除集群命令;
http://192.168.25.154:8080/solr/admin/collections?action=DELETE&name=collection1
执行后原来的collection1删除,如下:
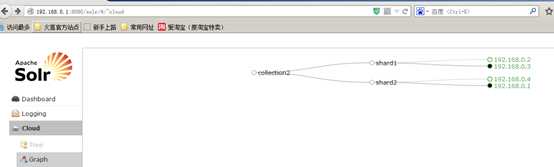
更多的命令请参数官方文档:apache-solr-ref-guide-4.10.pdf
启动solrCloud需要先启动solrCloud依赖的所有zookeeper服务器,再启动每台solr服务器。
public class SolrCloudTest { // zookeeper地址 private static String zkHostString = "192.168.25.154:2181,192.168.25.154:2182,192.168.25.154:2183";
// collection默认名称,比如我的solr服务器上的collection是collection2_shard1_replica1,就是去掉“_shard1_replica1”的名称 private static String defaultCollection = "collection1"; // cloudSolrServer实际 private CloudSolrServer cloudSolrServer; // 测试方法之前构造 CloudSolrServer @Before public void init() { cloudSolrServer = new CloudSolrServer(zkHostString); cloudSolrServer.setDefaultCollection(defaultCollection); cloudSolrServer.connect(); } // 向solrCloud上创建索引 @Test public void testCreateIndexToSolrCloud() throws SolrServerException, IOException { SolrInputDocument document = new SolrInputDocument(); document.addField("id", "100001"); document.addField("title", "李四"); cloudSolrServer.add(document); cloudSolrServer.commit(); } // 搜索索引 @Test public void testSearchIndexFromSolrCloud() throws Exception { SolrQuery query = new SolrQuery(); query.setQuery("*:*"); try { QueryResponse response = cloudSolrServer.query(query); SolrDocumentList docs = response.getResults(); System.out.println("文档个数:" + docs.getNumFound()); System.out.println("查询时间:" + response.getQTime()); for (SolrDocument doc : docs) { ArrayList title = (ArrayList) doc.getFieldValue("title"); String id = (String) doc.getFieldValue("id"); System.out.println("id: " + id); System.out.println("title: " + title); System.out.println(); } } catch (SolrServerException e) { e.printStackTrace(); } catch (Exception e) { System.out.println("Unknowned Exception!!!!"); e.printStackTrace(); } } // 删除索引 @Test public void testDeleteIndexFromSolrCloud() throws SolrServerException, IOException { // 根据id删除 UpdateResponse response = cloudSolrServer.deleteById("zhangsan"); // 根据多个id删除 // cloudSolrServer.deleteById(ids); // 自动查询条件删除 // cloudSolrServer.deleteByQuery("product_keywords:教程"); // 提交 cloudSolrServer.commit(); } }
标签:png keep 开源 代码 出现 zha add 客户 分布
原文地址:https://www.cnblogs.com/ZJOE80/p/12807519.html