标签:this 之间 linear 标准化 频率 空格 sse pre 方法
TF-IDF(Term Frequency-InversDocument Frequency)是一种常用于信息处理和数据挖掘的加权技术。该技术采用一种统计方法,根据字词的在文本中出现的次数和在整个语料中出现的文档频率来计算一个字词在整个语料中的重要程度。它的优点是能过滤掉一些常见的却无关紧要本的词语,同时保留影响整个文本的重要字词。
计算方法:通过将局部分量(词频)与全局分量(逆文档频率)相乘来计算tf-idf,并将所得文档标准化为单位长度。文件中的文档中的非标准权重的公式,如图:
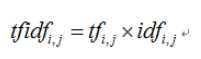
计算词频:
词频 (TF)= 某个词在文章出现总次数/文章总词数
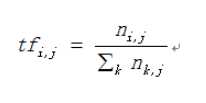
计算逆文档频率:(权重)
让我们从一个实例开始讲起。假定现在有一篇长文《中国的蜜蜂养殖》,我们准备用计算机提取它的关键词。
一个容易想到的思路,就是找到出现次数最多的词。如果某个词很重要,它应该在这篇文章中多次出现。于是,我们进行”词频”(Term Frequency,缩写为TF)统计。
(注意:出现次数最多的词是—-“的”、”是”、”在”—-这一类最常用的词。它们叫做”停用词”(stop words),表示对找到结果毫无帮助、必须过滤掉的词。)
假设我们把它们都过滤掉了,只考虑剩下的有实际意义的词。这样又会遇到了另一个问题,我们可能发现”中国”、”蜜蜂”、”养殖”这三个词的出现次数一样多。这是不是意味着,作为关键词,它们的重要性是一样的?
显然不是这样。因为”中国”是很常见的词,相对而言,”蜜蜂”和”养殖”不那么常见。如果这三个词在一篇文章的出现次数一样多,有理由认为,”蜜蜂”和”养殖”的重要程度要大于”中国”,也就是说,在关键词排序上面,”蜜蜂”和”养殖”应该排在”中国”的前面。
所以,我们需要一个重要性调整系数,衡量一个词是不是常见词。如果某个词比较少见,但是它在这篇文章中多次出现,那么它很可能就反映了这篇文章的特性,正是我们所需要的关键词。
用统计学语言表达,就是在词频的基础上,要对每个词分配一个”重要性”权重。最常见的词(”的”、”是”、”在”)给予最小的权重,较常见的词(”中国”)给予较小的权重,较少见的词(”蜜蜂”、”养殖”)给予较大的权重。这个权重叫做”逆文档频率”(Inverse Document Frequency,缩写为IDF),它的大小与一个词的常见程度成反比。
知道了”词频”(TF)和”逆文档频率”(IDF)以后,将这两个值相乘,就得到了一个词的TF-IDF值。某个词对文章的重要性越高,它的TF-IDF值就越大。所以,排在最前面的几个词,就是这篇文章的关键词。
下面就是算法的细节:
计算词频:

计算逆文档频率:
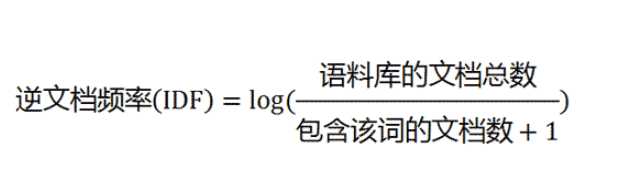
计算TF-IDF:
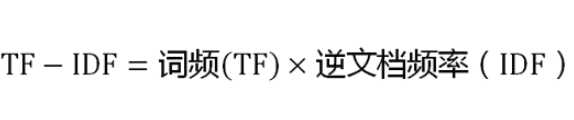
a[i][j] ,它表示J词再i类文本下的词频.
from sklearn.feature_extraction.text import CountVectorizer
#语料库:
corpus = [
‘This is the first document.‘,
‘This is the second second document.‘,
‘And the third one.‘,
‘Is this the first document?‘,
]
#将文本中的词语转换为词频矩阵
vectorizer = CountVectorizer()
#计算单个词出现次数
X = vectorizer.fit_transform(corpus)
#获取词袋中所有文本关键词
word = vectorizer.get_feature_names()
print(word)#[‘and‘, ‘document‘, ‘first‘, ‘is‘, ‘one‘, ‘second‘, ‘the‘, ‘third‘, ‘this‘]
#查看词频结果
print(X.toarray())
"""
[[0 1 1 1 0 0 1 0 1]
[0 1 0 1 0 2 1 0 1]
[1 0 0 0 1 0 1 1 0]
[0 1 1 1 0 0 1 0 1]]
"""
#解析:
从结果中看到9个特征词:[‘and‘, ‘document‘, ‘first‘, ‘is‘, ‘one‘, ‘second‘, ‘the‘, ‘third‘, ‘this‘] 同时再输出每个句子中包含特征词个数:
例如第一句:‘This is the first document.‘它对应词频数组中第一排[0 1 1 1 0 0 1 0 1],表示意思:假设初始序号从1开始计数,则该词频表示存在第2个位置的单词“document”共1次、第3个位置的单词“first”共1次、第4个位置的单词“is”共1次、第9个位置的单词“this”共1词。
from sklearn.feature_extraction.text import TfidfTransformer
transformer = TfidfTransformer()
print(transformer)
#TfidfTransformer(norm=‘l2‘, smooth_idf=True, sublinear_tf=False, use_idf=True)
tfidf = transformer.fit_transform(X)
print(tfidf.toarray())
"""
[[0. 0.43877674 0.54197657 0.43877674 0. 0.
0.35872874 0. 0.43877674]
[0. 0.27230147 0. 0.27230147 0. 0.85322574
0.22262429 0. 0.27230147]
[0.55280532 0. 0. 0. 0.55280532 0.
0.28847675 0.55280532 0. ]
[0. 0.43877674 0.54197657 0.43877674 0. 0.
0.35872874 0. 0.43877674]]
"""
import jieba
import jieba.posseg as pseg
import os
import sys
from sklearn import feature_extraction
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.feature_extraction.text import CountVectorizer
if __name__ == ‘__main__‘:
corpus = ["我 来到 北京 清华大学", # 第一类文本切词后的结果,词之间以空格隔开
"他 来到 了 网易 杭研 大厦", # 第二类文本的切词结果
"小明 硕士 毕业 与 中国 科学院", # 第三类文本的切词结果
"我 爱 北京 天安门"] # 第四类文本的切词结果
vectorizer = CountVectorizer() # 该类会将文本中的词语转换为词频矩阵,矩阵元素a[i][j] 表示j词在i类文本下的词频
transformer = TfidfTransformer() # 该类会统计每个词语的tf-idf权值
tfidf = transformer.fit_transform(
vectorizer.fit_transform(corpus)) # 第一个fit_transform是计算tf-idf,第二个fit_transform是将文本转为词频矩阵
word = vectorizer.get_feature_names() # 获取词袋模型中的所有词语
weight = tfidf.toarray() # 将tf-idf矩阵抽取出来,元素a[i][j]表示j词在i类文本中的tf-idf权重
for i in range(len(weight)):
print("这里输出第",i,"类文本的词语tf-idf权重")
for j in range(len(word)):
print(word[j],weight[i][j])
"""
这里输出第 0 类文本的词语tf-idf权重
中国 0.0
北京 0.5264054336099155
大厦 0.0
天安门 0.0
小明 0.0
来到 0.5264054336099155
杭研 0.0
毕业 0.0
清华大学 0.6676785446095399
硕士 0.0
科学院 0.0
网易 0.0
这里输出第 1 类文本的词语tf-idf权重
中国 0.0
北京 0.0
大厦 0.5254727492640658
天安门 0.0
小明 0.0
来到 0.41428875116588965
杭研 0.5254727492640658
毕业 0.0
清华大学 0.0
硕士 0.0
科学院 0.0
网易 0.5254727492640658
这里输出第 2 类文本的词语tf-idf权重
中国 0.4472135954999579
北京 0.0
大厦 0.0
天安门 0.0
小明 0.4472135954999579
来到 0.0
杭研 0.0
毕业 0.4472135954999579
清华大学 0.0
硕士 0.4472135954999579
科学院 0.4472135954999579
网易 0.0
这里输出第 3 类文本的词语tf-idf权重
中国 0.0
北京 0.6191302964899972
大厦 0.0
天安门 0.7852882757103967
小明 0.0
来到 0.0
杭研 0.0
毕业 0.0
清华大学 0.0
硕士 0.0
科学院 0.0
网易 0.0
"""
标签:this 之间 linear 标准化 频率 空格 sse pre 方法
原文地址:https://www.cnblogs.com/xujunkai/p/12807359.html