标签:clear include size 更新 核心 目录 int http 不同
概述:对字符串集合的单个字符串进行操作(配合数据结构或STL判重、统计、查询、修改等操作),在字符串集合中去寻找该字符串过程中,对字符串集合进行遍历和map映射在规模较大时都会浪费很多时间。字符串哈希是将单个字符串离散化映射为一个哈希值(哈希函数),在通过一些方式去解决冲突(不同的字符串可能对应相同的数值)后,使用哈希值找到该字符串,然后进行操作。
同时哈希函数对应的结果一般都比较大,通过取余等方式来分配到一个合适的空间。
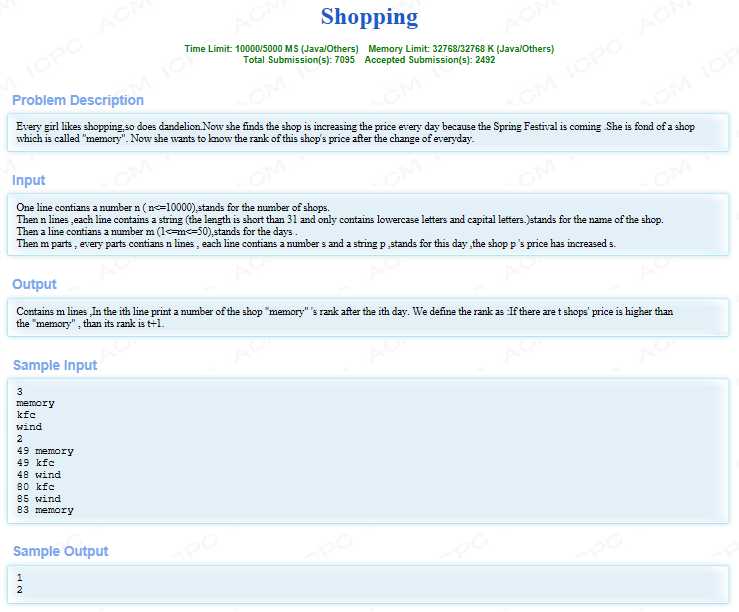
思路:简单hash,每一个字符串对应一个数值,一次更新操作,将所有的字符串全部加上某个价格,求解某个商店的排行。使用hash函数,映射字符串,同时取余分配到一个较小的空间,这样来每个店铺名称都对应一个位置,可以随机存取。该题难点在于解决冲突,在hash表上进行扩展,同样值得字符串,使用动态数组来增加,名字正确匹配之后进行操作解决冲突。
#include <iostream>
#include<cstdio>
#include<cstring>
#include<string>
#include<vector>
#define Max 10050
using namespace std;
struct Node {
int price;
string name;
};
int seed = 31;
int H(string s) {
int key = 0;
for (int i = 0; i < s.size(); i++) {
key = key * seed + s[i];
}
return key & 0x7ffffff;
}
int main()
{
vector<Node>List[Max];
int n, m,len,price=0,rank,p[Max];
Node t;
while (cin >> n) {
for (int i = 0; i < Max; i++) {
List[i].clear();
}
for (int i = 1; i <= n; i++) {
cin >> t.name;
int key = H(t.name) % Max;
t.price = 0;
List[key].push_back(t);
}
cin >> m;
for (int i = 1; i <= m; i++) {
rank = 0;
len = 0;
for (int s = 1; s <= n; s++) {
cin >> t.price >> t.name;
int key = H(t.name) % Max;
for (int j = 0; j < List[key].size(); j++) {
if (List[key][j].name == t.name) {
List[key][j].price += t.price;
p[++len] = List[key][j].price;
if (List[key][j].name == "memory")price = List[key][j].price;
break;
}
}
}
for (int j = 1; j <= len; j++) {
if (p[j] > price) rank++;
}
cout << rank + 1 << endl;
}
}
}
标签:clear include size 更新 核心 目录 int http 不同
原文地址:https://www.cnblogs.com/508335848vf/p/12807996.html