标签:power code cost 包括 ima 选择 应用 优化 就会
到现在为止,我们已经学习了几种不同的学习算法,包括线性回归和逻辑回归,它们能够有效地解决许多问题,但是当将它们应用到某些特定的机器学习应用时,会遇到过拟合(over-fitting)的问题,可能会导致它们效果很差。
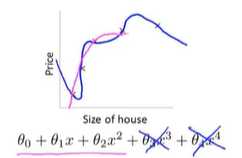
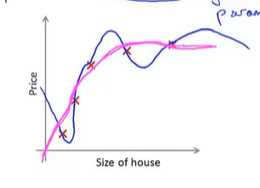
继续使用线性回归来预测房价的例子,我们通过建立以住房面积为自变量的函数来预测房价。
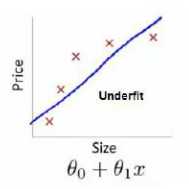
但是这不是一个很好的模型,通过数据可以明显的看出随着数据房子面积的增大,住房价格逐渐稳定。---越往后越平缓。
所以该算法没有很好的拟合训练集。我们把这个问题称为欠拟合(underfitting)。这个问题的另一个术语叫做高偏差(bias)
这两种说法大致相似,意思是它只是没有很好地拟合训练数据。
它的意思是如果拟合一条直线到训练数据,就好像算法有一个很强的偏见或者说非常大的偏差,因为该算法认为房子价格与面积仅仅线性相关。
与实际数据规律不符合,先入为主的拟合一条直线,最终导致拟合数据效果很差。
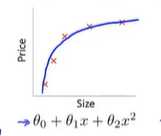
如果我们拟合一个高阶多项式,那么这个函数能很好的拟合训练集,能拟合几乎所有的训练数据。这就面临可能的函数,太过庞大,变量太多的问题。
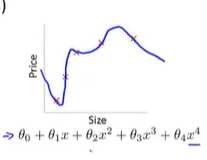
同时如果我们没有足够的数据,去约束这个变量过多的模型,那么这就是过度拟合。
概括的说:过度拟合的问题,将会在变量过多的时候出现,这时训练出的假设能很好的拟合训练集。所以,代价函数实际上可能非常接近于0。
![]()
但是你可能会得到这样的曲线:
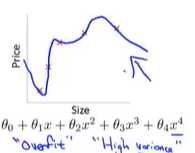
它虽然可以很好的拟合训练集,但是会导致它无法泛化到新的样本中,无法预测新样本的价格
泛化:一个假设模型应用到新样本的能力
新样本的数据:没有出现在训练集的数据
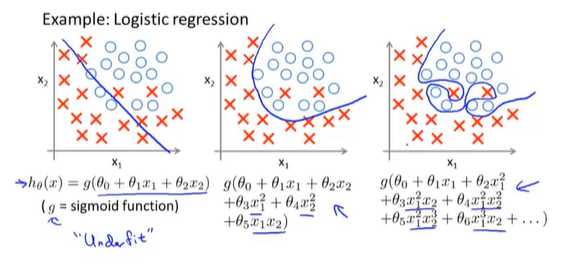
图一:不能很好的拟合数据---欠拟合
图二:很好的拟合了数据
图三:千方百计的找到一个判定边界,来拟合训练数据---过拟合
1.丢弃一些不能帮助我们正确预测的特征(减少特征变量)。可以是手工选择保留哪些特征,或者使用一些模型选择的算法来帮忙(例如PCA)---可以有效的减少过拟合的发生,但是也可能丢弃关于问题的一些信息
2.正则化。 保留所有的特征,但是减少量级或者参数θ_j的大小(magnitude)。---因为很可能我们的每一个特征变量都是有一定用的,因此我们不希望舍弃这些特征变量。
当我们进行正则化的时候,我们还将写出相应的代价函数。
由前面可以知道,下面两种拟合方式,第一个可以很好的拟合训练集,第二个则是过拟合(泛化得不好)
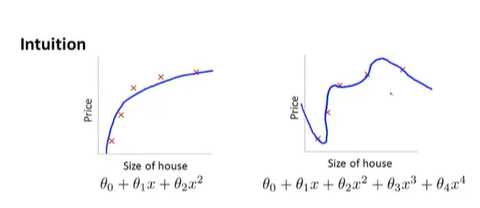
而我们想要保留所有得特征,那应该如何做?
我们不妨在函数中加入惩罚项。使得参数θ_3和θ_4都非常小---看后面1000* 看下
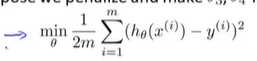
这是我们得优化目标。 我们要最小化其均方误差代价函数。----优化目标(代价函数)不等于假设函数(但是对其有影响)
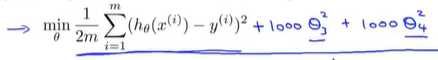
我们对上面得函数进行了一些修改,对于θ_3方和θ_4方乘以一个很大的数(比如1000)
假如我们要最小化这个函数,那么要使修改后的函数尽可能的小的方法只有一个:就是θ_3和θ_4尽可能的小(这些参数越小,我们得到的函数就会越平滑,也简单) 启上
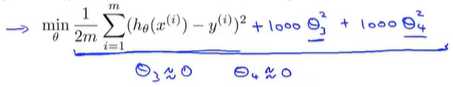
就好像省略的θ_3和θ_4这两项一样,那么这个函数还是相当于二次函数:最后我们拟合数据的函数,实际上还是一个二次函数
那么,这就是一种很好的假设模型。
在该例子中,可以看到,加入了惩罚项,增大两个参数所带来的效果。
总的来说:这就是正则化背后的思想。

比如:我们有很多特征变量(这里101个),我们并不知道谁的相关性比较小,那么我们应该决定缩小哪一个特征变量呢?
正则化处理:直接修改代价函数,在后面添加一个新的项(额外的正则化项)---来缩小每一个参数,从θ_1到θ_100(约定),实际上假设θ_0也没有影响
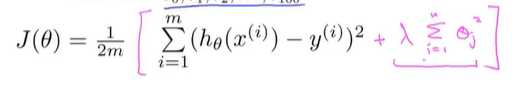

其中入是正则化参数---控制两个不同目标之间的取舍(平衡关系):
第一个目标:与目标函数的第一项有关,该目标是想要更好的拟合数据,训练集
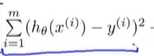
第二个目标:与目标函数第二项(正则化项)有关,该目标就是要保持参数尽量的小
从而简化模型,避免过拟合的情况。
如果正则化参数入设置过大:结果会导致对正则化项中的参数θ_j的惩罚程度太大。导致这些参数都会接近于0
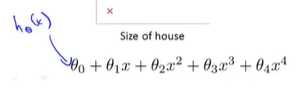
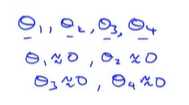
这样的话,就相当于把假设函数的全部项都忽略掉了。导致假设模型最后只剩下一个θ_0。

导致使用一条直线去拟合训练集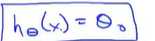 ,导致欠拟合。
,导致欠拟合。
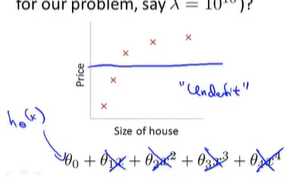
所以为了让正则化起到好的效果,我们应该去选择一个更加合适的正则化参数入。
对于线性回归的求解,我们之前推导了两种学习算法:
一种基于梯度下降
一种基于正规方程
这里,我们将继续学习这两个算法,并把它们推广到正则化线性回归中去。

这是我们之前学到的,正则化线性回归的代价函数。
如果我们要使用梯度下降法令这个代价函数最小化,因为我们未对θ_0进行正则化,所以梯度下降算法将分两种情形:

对上面两种情况进行合并简化:

其中α一般很小,而m比较大。所以会导致1-α入/m接近1:比如可以想成0.99
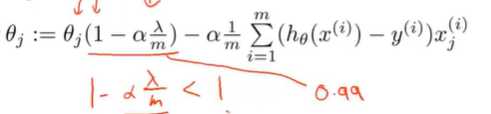
只是把θ_j变小的速度降低了。其他的没有太大区别。
其优点:可以看出,正则化线性回归的梯度下降算法的变化在于,每次都在原有算法更新规则的基础上令值减少了一个额外的值。
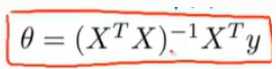
含推导过程:https://www.cnblogs.com/ssyfj/p/12791935.html---就是将代价函数的偏导求0,即可。
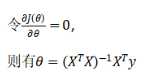
其中X是一个m*(n+1)维矩阵,y会是一个m维向量。

其中m是训练样本数量,n是特征变量数。n+1是因为我加的这个额外的特征变量x0。
上面的正规方程,还是没有正则化项的。
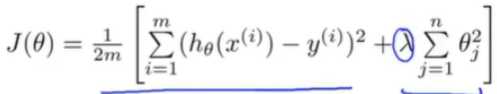
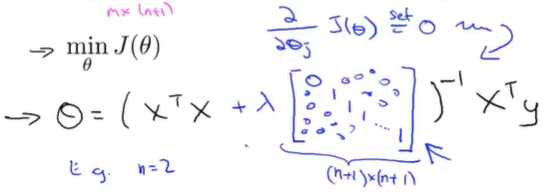

其实就是,C=AB,r(C)<=min(A,B)<=m,由于m<n,这里的C是XT*X,为(n+1)*(n+1)的矩阵,秩最大为m所以不可逆
其中当入>0时,后面的矩阵的秩=n,与前面的XTX相加,可以解决一些不可逆问题。
针对逻辑回归问题,已经学习过两种优化算法:
1.我们首先学习了使用梯度下降法来优化代价函数J(θ),
2.接下来学习了更高级的优化算法,这些高级优化算法需要自己设计代价函数J(θ)。
使用正则化改进这两种算法 。
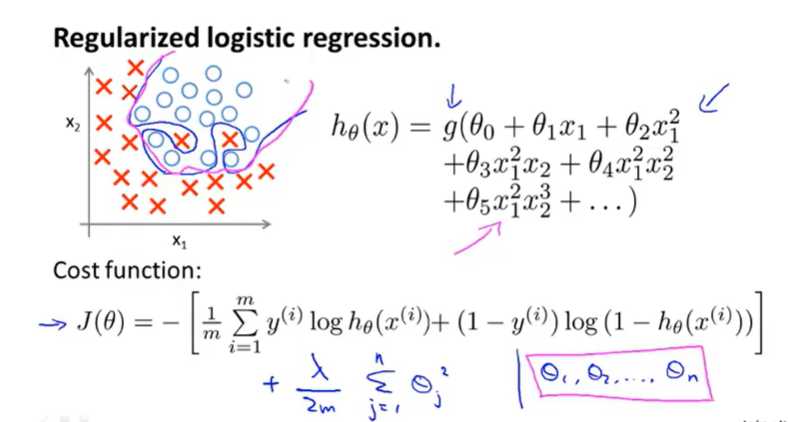
可以很好的区分正样本和负样本。
代码实现:
import numpy as np def costReg(theta, X, y, learningRate): theta = np.matrix(theta) X = np.matrix(X) y = np.matrix(y) first = np.multiply(-y, np.log(sigmoid(X*theta.T))) second = np.multiply((1 - y), np.log(1 - sigmoid(X*theta.T))) reg = (learningRate / (2 * len(X))* np.sum(np.power(theta[:,1:theta.shape[1]],2)) return np.sum(first - second) / (len(X)) + reg

与线性回归不同之处就在于假设函数的不同。
对于高级算法,我们想要自己定义一个costFunction函数:---使用fminuc函数调用函数costFunction或者其他高级优化函数

这个函数以参数向量θ为输入 。
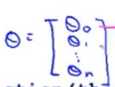
返回:实现正则化代价函数:
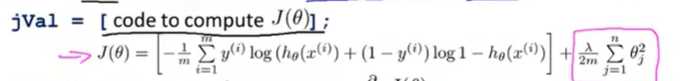
返回:梯度求取:

标签:power code cost 包括 ima 选择 应用 优化 就会
原文地址:https://www.cnblogs.com/ssyfj/p/12811577.html