标签:随机 完全 头部 class 地址 usr ihs pad 一个
先认识几个东西:
1、Elasticsearch :开源分布式搜索引擎,它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制, restful 风格接口,多数据源,自动搜索负载等。
2、Logstash :完全开源的工具,对日志进行收集、分析,并将其存储供以后使用(如,搜索)。
3、kibana:开源和免费的工具,Kibana 可以为 Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面,可以帮助您汇总、分析和搜索重要数据日志。
1:安装jdk:Elasticsearch基于java,先配置java环境。
(2):我们到oracle去下载安装包:https://www.oracle.com/technetwork/java/javase/downloads/index.html
我这里用:jdk-11.0.4_linux-x64_bin.tar.gz
(1):安装jdk,先看看服务器上是否安装过java
[root@localhost local]# java -version
-bash: java: 未找到命令
下载上面的jdk
tar -zxvf jdk-11.0.4_linux-x64_bin.tar.gz -C /usr/local/ //我解压到这里
cd /usr/local/
ls
改一下目录名字吧
mv jdk-11.0.4/ jdk
(3):添加环境变量
vi /etc/profile
然后把环境变量添加到最后:
export JAVA_HOME=/usr/local/jdk
export CLASSPATH=$JAVA_HOME/lib/
export PATH=$JAVA_HOME/bin //这一行如果有添加在后面
红色部分是我加的环境变量
执行命令使环境变量生效:
source /etc/profile
再看看 java命令:
[root@localhost config]# java -version
java version "11.0.4" 2019-07-16 LTS
Java(TM) SE Runtime Environment 18.9 (build 11.0.4+10-LTS)
Java HotSpot(TM) 64-Bit Server VM 18.9 (build 11.0.4+10-LTS, mixed mode)
安装成功了!7.3自带了一个jdk,可以不用去下载,用这个也可以,如图:

下载地址:https://www.elastic.co/cn/downloads/
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.3.1-linux-x86_64.tar.gz #下载
tar -xvf elasticsearch-7.3.1-linux-x86_64.tar.gz
mv elasticsearch-7.3.1/ elasticsearch #改个名字
这玩意儿解压就可以启动了,试一下:
./bin/elasticsearch
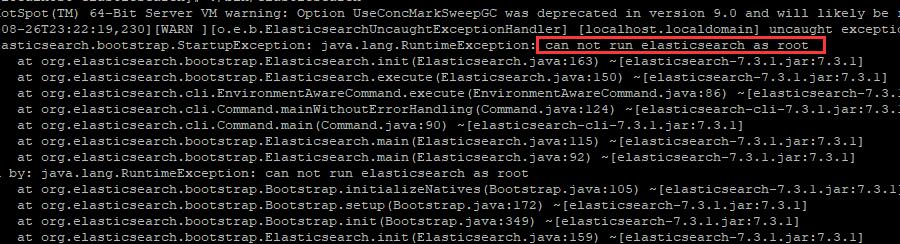
报错,这里提示这个,因为es5.0以后,为了安全不允许root用户操作,我们创建一个专门的账号。
groupadd es_g //创建用户组
useradd es -g es_g -p 123 //在es_g用户组下添加一个es用户
给elasticsearch目录赋予权限
chown -R es:es_g elasticsearch/
切换用户
su es
再启动一下:
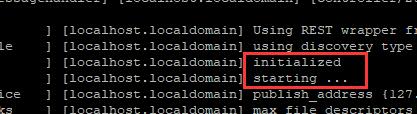 看见这个表示启动成功。
看见这个表示启动成功。
我们试一下,这里窗口先别关,重新打开一个终端(也可以后台启动,-d),用linux的curl命令检测一下,如果要查看http头:curl -i -XGET ‘localhost:9200‘
[root@localhost ~]# curl "127.0.0.1:9200"
{
"name" : "localhost.localdomain",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "iHsxZzqiQMWcAgw3yBdY9Q",
"version" : {
"number" : "7.3.1",
"build_flavor" : "default",
"build_type" : "tar",
"build_hash" : "4749ba6",
"build_date" : "2019-08-19T20:19:25.651794Z",
"build_snapshot" : false,
"lucene_version" : "8.1.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
再用浏览器试下:
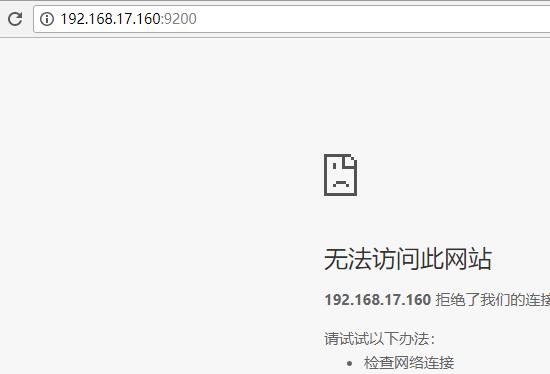
竟然访问不到,防火墙也是关着的。
切换到root用户查看一下端口:
[root@localhost ~]# netstat -aon|grep 9200
tcp6 0 0 127.0.0.1:9200 :::* LISTEN off (0.00/0/0)
tcp6 0 0 ::1:9200 :::* LISTEN off (0.00/0/0)
原来这里绑定的是127,难怪访问不到,改一下配置:
vi config/elasticsearch.yml
搜索 network.host
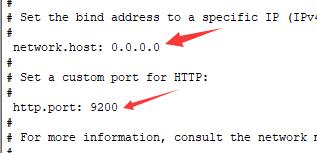 注意前面有个空格,冒号后面也有个空格
注意前面有个空格,冒号后面也有个空格
再切换到se用户运行一下,发现报错。看看报错死马:
ERROR: [3] bootstrap checks failed
[1]: max file descriptors [4096] for elasticsearch process is too low, increase to at least [65535]
[2]: max number of threads [3796] for user [es] is too low, increase to at least [4096]
[3]: the default discovery settings are unsuitable for production use; at least one of [discovery.seed_hosts, discovery.seed_providers, cluster.initial_master_nodes] must be configured
1:ElasticSearch进程的最大文件描述符,2:es最大线程个数低,3:这两个什么狗屁配置至少要配置一个。一个个来。首先切换到root账号
(1)设置最大文件描述符,我们查看下现在是多少?
[root@localhost elasticsearch]# ulimit -Hn
4096
[root@localhost elasticsearch]# ulimit -Sn
1024
可以看到默认硬资源限制是 4096,软资源限制是 1024,这两个啥意思?
#硬限制是指对资源节点和数据块的绝对限制,在任何情况下都不允许用户超过这个限制
ulimit -Hn #硬资源数值
#软限制在一定时间范围内(默认为一周,在/usr/include/sys/fs/ufs_quota.h文件中设置)超过软限制的额度。
#在硬限制的范围内继续申请资源,同时系统会在用户登录时给出警告信息和仍可继续申请资源剩余时间
#超过期限则不允许再申请资源
ulimit -Sn #软资源数值
#所以软资源限制数目不能超过硬资源限制
编辑 /etc/security/limits.conf文件:加入以下到文件开头:
* soft nofile 65536
* hard nofile 65536
我这里的配置
加入后重新登录有效,也就是把当前的终端关了,再进去,可以用上面两个命令查下,已经改过来了。接着看下一个
(2)最大线程个数,查看一下当前是多少?
[es@localhost elasticsearch]$ ulimit -Hu #单个用户可用的最大进程数量(硬限制)
3796
[es@localhost elasticsearch]$ ulimit -Su #单个用户可用的最大进程数量(软限制)
3796
还是修改 /etc/security/limits.conf文件,添加:
* soft nproc 4096
* hard nproc 4096
重新登录生效
(3)the default discovery settings are unsuitable for production use; at least one of [discovery.seed_hosts, discovery.seed_providers, cluster.initial_master_nodes] must be configured
编辑文件:
vi config/elasticsearch.yml
这里有两个节点,node-1,node-2,错误说必须打开一个,这里我们就打开node-1,表示集群必须信任某个节点,哪怕是本机。
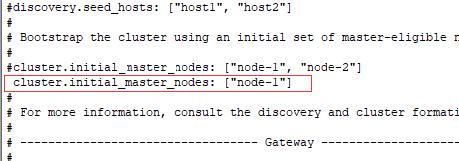
然后切换到se用户,再运行一下:
又报一个错误:
[root@bogon elasticsearch]# ./bin/elasticsearch -d
Java HotSpot(TM) 64-Bit Server VM warning: Option UseConcMarkSweepGC was deprecated in version 9.0 and will likely be removed in a future release.
这个只是一个
警告,看不出来啥问题,
这个警告TM很容易误解,让人一直以为是jdk版本问题。
为了在屏幕看完整的信息,这里启动的时候不加-d 后台启动,看看到底什么鬼问题:
ERROR: [1] bootstrap checks failed
[1]: max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
果然问题出来了:这段报错的意思是:最大虚拟内存区域vm.max_map_count只有65530,太低,至少增加到[262144]
切入到root账号,我们查看一下:
sysctl -a|grep vm.max_map_count
果然是啊
改吧,继续改,修改/etc/sysctl.conf文件最后添加一行:
vm.max_map_count=262144
这样是永久修改!然后执行载入生效命令:
sysctl -p
好,切入到es账号,再启动,终于可以了!浏览器访问一下:
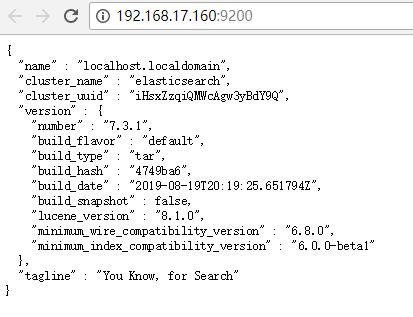 大功告成,外面可以访问了!
大功告成,外面可以访问了!
1:基本概念:es本质上是一个分布式文件数据库,允许多台服务器协同工作,每台服务器可以运行多个 Elastic 实例。单个 Elastic 实例称为一个节点(node)。一组节点构成一个集群(cluster);
Elasticsearch集群可以包含多个索引(相当于mysqlindices)(数据库),每一个索引可以包含多个类型(types)(相当于mysql表),每一个类型包含多个文档(documents)(行),然后每个文档包含多个字段(Fields)(列)。
注意:类型types(相当于mysql表)在6.0以后一个索引下只能有一个type,7.0以后不建议用type类型,8.0开始正式抛弃
2:cat命令:
cat提供了查询集群状态的api,可以通过 curl -XGET localhost:9200/_cat 获取所有cat操作
[root@localhost elasticsearch]# curl -XGET localhost:9200/_cat
=^.^=
/_cat/allocation #节点分配情况
/_cat/shards #分片情况
/_cat/shards/{index}
/_cat/master #主节点
/_cat/nodes #所有节点
/_cat/tasks
/_cat/indices #所有索引列表
/_cat/indices/{index}
/_cat/segments #索引分片信息
/_cat/segments/{index}
/_cat/count #文档个数
/_cat/count/{index}
/_cat/recovery
/_cat/recovery/{index}
/_cat/health #集群运行状况
/_cat/pending_tasks
/_cat/aliases
/_cat/aliases/{alias}
/_cat/thread_pool
/_cat/thread_pool/{thread_pools}
/_cat/plugins
/_cat/fielddata
/_cat/fielddata/{fields}
/_cat/nodeattrs
/_cat/repositories
/_cat/snapshots/{repository}
/_cat/templates
这些命令后面加上?v,格式化输出,也可以加上?help查看命令相关帮助信息
比如查询所有的节点:
[root@localhost usr]# curl -XGET ‘http://localhost:9200/_cat/nodes?v‘ #?v 格式化输出
ip heap.percent ram.percent cpu load_1m load_5m load_15m node.role master name
192.168.17.160 11 92 0 0.11 0.07 0.05 dim * localhost.localdomain
查看所有索引:
curl -XGET ‘http://localhost:9200/_cat/indices?v‘
返回:
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
表示还未有任何索引
查看集群状态是否正常:
curl -XGET localhost:9200/_cat/health?v
green 绿色表示一切正常
绿色——正常。黄色——所有主分片shard可用,部分副本分片replica不可用。红色——部分主分片shard不可用。
详细的后面结合例子理解!
[elastic@console bin]$ vim ../config/elasticsearch.yml
http.cors.enabled: true
http.cors.allow-origin: "*"
http.cors.allow-headers: Authorization
xpack.security.enabled: true
xpack.security.transport.ssl.enabled: true
添加密码:
[elastic@console bin]$ ./elasticsearch-setup-passwords interactive
future versions of Elasticsearch will require Java 11; your Java version from [/usr/java/jdk1.8.0_181/jre] does not meet this requirement
Initiating the setup of passwords for reserved users elastic,apm_system,kibana,logstash_system,beats_system,remote_monitoring_user.
You will be prompted to enter passwords as the process progresses.
Please confirm that you would like to continue [y/N]y
Enter password for [elastic]:
Reenter password for [elastic]:
Passwords do not match.
Try again.
Enter password for [elastic]:
Reenter password for [elastic]:
Enter password for [apm_system]:
Reenter password for [apm_system]:
Enter password for [kibana]:
Reenter password for [kibana]:
Enter password for [logstash_system]:
Reenter password for [logstash_system]:
Enter password for [beats_system]:
Reenter password for [beats_system]:
Enter password for [remote_monitoring_user]:
Reenter password for [remote_monitoring_user]:
Changed password for user [apm_system]
Changed password for user [kibana]
Changed password for user [logstash_system]
Changed password for user [beats_system]
Changed password for user [remote_monitoring_user]
Changed password for user [elastic]
数据交互有两种:
1:java api:java代码调用es的API方式,默认端口:9300
2:RESTful API:基于http协议,任何语言都可以交互,我们就用这种。默认端口:9200
语法:curl -X[VERB] ‘[PROTOCOL]://[HOST]/[PATH]?[QUERY_STRING]‘ -d ‘[BODY]‘
******************************************************************************************
VERB HTTP方法: GET , POST , PUT , HEAD , DELETE
PROTOCOL http或者https协议(只有在Elasticsearch前面有https代理的时候可用)
HOST Elasticsearch集群中的任何一个节点的主机名,如果是在本地的节点,那么就叫localhost
PORT Elasticsearch HTTP服务所在的端口,默认为9200
QUERY_STRING 一些可选的查询请求参数,例如 ?pretty 参数将使请求返回更加美观易读的JSON数据
BODY 一个JSON格式的请求主体(如果请求需要的话)
******************************************************************************************
3:小试身手,搞个例子
curl -H "Content-Type: application/json" -XPUT ‘localhost:9200/shcool/student/1‘ -d ‘
{
"name" : "李小龙",
"age" : 25,
"about" : "他是个伟大的武术家"
}‘
我们准备执行一下这个命令,看看这个命令是什么意思:
curl:linux命令,可以发送HTTP请求,
-H:-H "Content-Type: application/json":代表head头,表示数据为json格式(新版本需要加这个)
-XPUT:-XPUT 是一个 PUT 请求,-PUT:其实是GET请求,所以必须加-X
shcool:索引名称(相当于mysql的数据库)
student:类型(相当于mysql中的表)
红色的 1 :表示ID,-XPUT必须写id,可以为string,如果不写必须用 -XPOST,这样表示自增,系统自动分配随机字符串
-d:表示要发送的数据
json数据:必须用单引号括号起来,否则格式不对,比如上面大括号外面的单引号
好了,现在执行一下!返回:
{
"_index": "shcool", //索引名
"_type": "student", //类型名
"_id": "1", //该条数据id
"_version": 1, //第一次创建一个document的时候,_version内部的版本号为1,以后每次写操作都会加1
"result": "created", //result:结果,created:创建成功
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 0,
"_primary_term": 1
}
更多参数介绍:https://www.elastic.co/guide/en/elasticsearch/reference/7.x/docs-index_.html
上面这串命令干了什么?
建立了名为:shcool的索引,在该索引下创建了名为:student的类型,然后往该类型中添加了一条数据(文档),发现这和mysql不一样,mysql添加数据必须要先建个数据库,表。而这里如果没有该数据库和表,es会自动建立。
确认一下这个索引是否存在:
[root@bogon ~]# curl -XGET ‘http://localhost:9200/_cat/indices?v‘
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
yellow open shcool -wSnblotSEWb6XyvTEA5QQ 1 1 1 0 4.5kb 4.5kb
索引果然有了!
再查看一下索引下的type(类型):
[root@bogon ~]# curl -XGET ‘http://localhost:9200/shcool/_mapping?pretty=true‘
{
"shcool" : {
"mappings" : {
"properties" : {
"about" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"age" : {
"type" : "long"
},
"name" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
}
}
}
?pretty=true
参数是格式化json数据,不然堆在一起很难看。这里可以发现有about,name,age,三个字段,但是有个问题,为什么没有type名字?我们当时添加数据的时候,type:student。
因为6.0以后一个索引下只能有一个type,7.0以后不建议用type类型,8.0开始正式抛弃。
继续,查询一下shcool索引下是否有数据:
[root@bogon ~]# curl -XGET ‘localhost:9200/shcool/student/_search?pretty=true‘
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "shcool",
"_type" : "student",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"name" : "李小龙",
"age" : 25,
"about" : "他是个伟大的武术家"
}
}
]
}
}
_search:返回全部数据,默认返回前面10条,因为type是计划抛弃的,所以7.0以后可以不带这个type,所以上面的命令也可以这样写:
curl -XGET ‘localhost:9200/shcool/_search?pretty=true‘
这里只带了索引!
用POST发送一下,POST发送的时候,不用带ID,es自己分配一个字符串ID
curl -H "Content-Type: application/json" -XPOST ‘localhost:9200/shcool/student‘ -d ‘
{
"name" : "甄子丹",
"age" : 25,
"about" : "他是个伟大的功夫明星"
}‘
返回:
{
"_index": "shcool",
"_type": "student",
"_id": "QRoP22wBkRiy3LLk_GC3", //es自己生成的字符串ID
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 1,
"_primary_term": 1
}
官网文档:https://www.elastic.co/guide/en/elasticsearch/reference/current/docs.html
1:索引操作:
(1);创建索引:发送:PUT 请求
curl -XPUT ‘localhost:9200/goods‘ //创建名为:goods的索引,索引名称只能小写,7.0之前的索引可能包含冒号(:),但已被弃用,7.0+不支持
(2):删除索引:发送:DELETE 请求
curl -XDELETE ‘localhost:9200/goods‘ //删除索引:goods
(3):查看索引,发送:GET请求
curl -XGET ‘localhost:9200/goods‘ //查看索引:goods
更多索引操作查看官方文档
2:文档操作
(1)写入操作:
将JSON文档添加到指定的索引并使其可搜索。如果文档已存在,则更新文档并增加其版本。
请求:
PUT //_doc/<_id> //创建,必须带ID 如果有相同文档,更新
POST //_doc/ //创建,系统自动分配string id 如果有相同文档,更新
PUT //_create/<_id> //创建,必须带ID,如果有相同文档 创建失败
POST //_create/<_id> //创建,系统自动分配string id 如果有相同文档 创建失败
DELETE //_doc/<_id> //删除文档
因为type未来会放弃,所以7.X版本不需要创建type,这里的_doc,_create:相当于以前的type
创建一条:
curl -H "Content-Type: application/json" -XPUT ‘localhost:9200/goods/_doc/1‘ -d ‘
{
"name" : "甄子丹",
"age" : 25,
"about" : "他是个伟大的功夫明星"
}‘
这和我们小试身手那个例子基本是一样的,唯一不同的地方,我们这里没有type,注意红色部分,最开始的那个例子红色部分是:student类型。为什么不用类型?前面已经提过多次。
(2):读取操作,检索文档数据
基本检索:
curl -XGET ‘localhost:9200/goods/_doc/_search‘ //全部
curl -XGET ‘localhost:9200/goods/_doc/1‘ #检索 索引goods 下ID为1
curl -i -XHEAD ‘localhost:9200/goods/_doc/1‘ #检索 索引goods 下ID为1s是否存在,必须加-i
组合检索:
1):from,size
控制查询返回的数量,相当于mysql 里面的limit
from:返回位置
size:定义返回最大的结果数
curl -H "Content-Type: application/json" -XGET ‘localhost:9200/goods/_doc/_search?pretty=true‘ -d ‘
{
"from" : 0, "size" : 2
}‘
注意:
新版本es,必须要带head头部:-H "Content-Type: application/json",?pretty=true:格式化json
2):Match 查询:
match会给字段提供合适的分析器,相当于mysql的模糊查询,term相当于精确查询
https://www.elastic.co/guide/en/elasticsearch/reference/7.3/query-dsl-match-query.html
查询 goods 索引,字段:name 为:李小 的数据,下面两个写法一样
curl -H "Content-Type: application/json" -XGET ‘localhost:9200/goods/_doc/_search?pretty=true‘ -d ‘
{
"query": {
"match" : {
"name" : {
"query" : "李小"
}
}
}
}‘
curl -H "Content-Type: application/json" -XGET ‘localhost:9200/goods/_doc/_search?pretty=true‘ -d ‘
{
"query" : { "match" : { "name" : "李小" }}
}‘
搜索字段name = 李 or name = 甄;中间空格即可 or
curl -H "Content-Type: application/json" -XGET ‘localhost:9200/goods/_doc/_search?pretty=true‘ -d ‘
{
"query" : { "match" : { "name" : "李 甄" }}
}‘
这样也可以:
curl -H "Content-Type: application/json" -XGET ‘localhost:9200/goods/_doc/_search?pretty=true‘ -d ‘
{
"query": {
"match" : {
"name" : {
"query" : "李 甄",
"operator" : "or"
}
}
}
}‘
搜索字段
name = 李 and name = 甄
标签:随机 完全 头部 class 地址 usr ihs pad 一个
原文地址:https://www.cnblogs.com/xbq8080/p/12813781.html