标签:神经元 hid poc sof moment 区域 port img oid
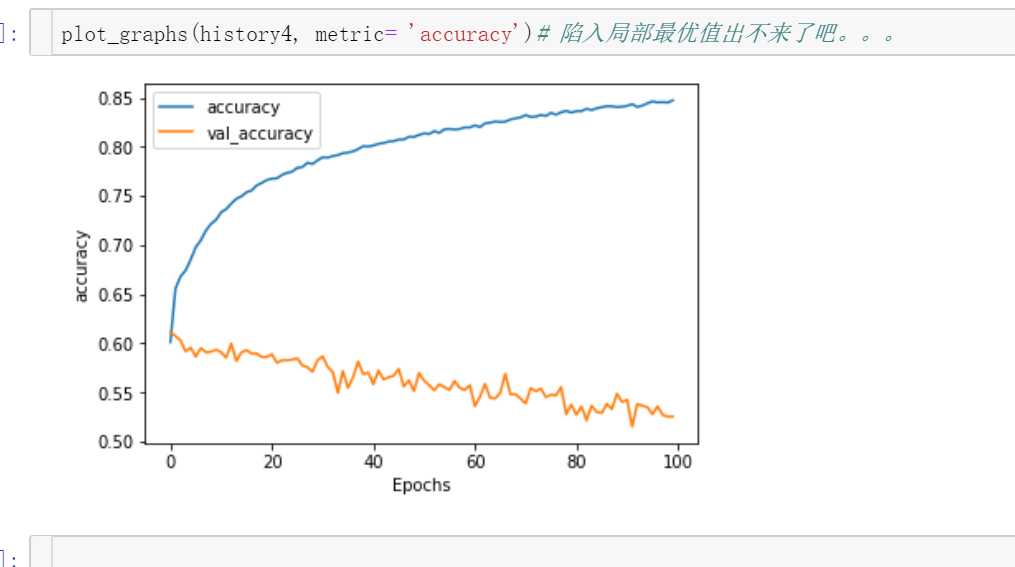
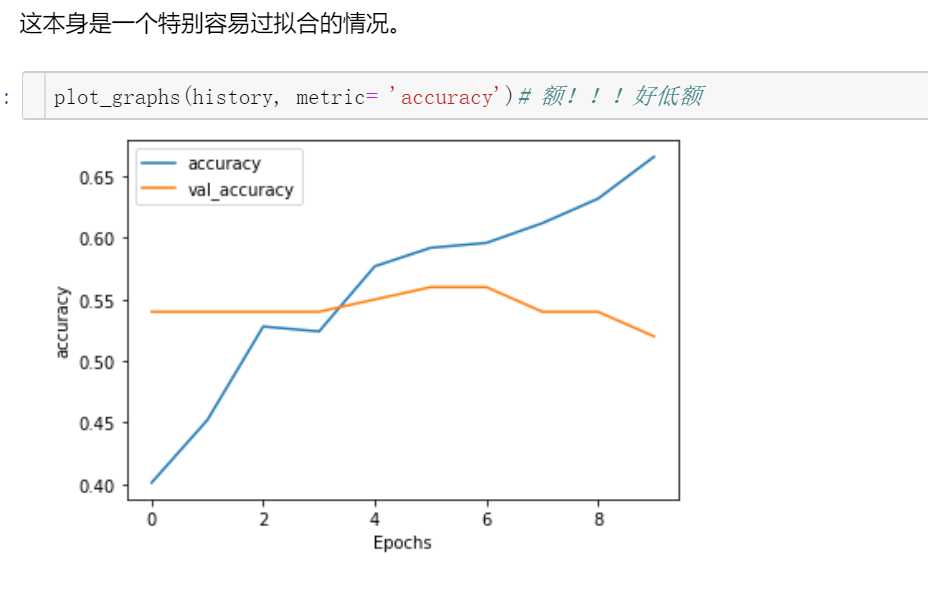
没有加batch normalization,过拟合,也就是训练集的效果还不错,但是测试集的效果真的差
BN的基本思想其实相当直观:因为深层神经网络在做非线性变换前的激活输入值(就是那个x=WU+B,U是输入)随着网络深度加深或者在训练过程中,其分布逐渐发生偏移或者变动,之所以训练收敛慢,一般是整体分布逐渐往非线性函数的取值区间的上下限两端靠近(对于Sigmoid函数来说,意味着激活输入值WU+B是大的负值或正值),所以这导致后向传播时低层神经网络的梯度消失,这是训练深层神经网络收敛越来越慢的本质原因,而BN就是通过一定的规范化手段,把每层神经网络任意神经元这个输入值的分布强行拉回到均值为0方差为1的标准正太分布而不是萝莉分布(哦,是正态分布),其实就是把越来越偏的分布强制拉回比较标准的分布,这样使得激活输入值落在非线性函数对输入比较敏感的区域,这样输入的小变化就会导致损失函数较大的变化,意思是这样让梯度变大,避免梯度消失问题产生,而且梯度变大意味着学习收敛速度快,能大大加快训练速度。张俊林博客」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
以一个图为例,epoch设置为100
这是tokenizer之后词条化的处理

很明显需要特征标准化处理,因为差别挺大的,某些数值较小的特征是不显著的。
用keras实现还是比较简单的,只要在dense层后面增加一个标准化层就好了
# import BatchNormalization
from keras.layers.normalization import BatchNormalization
# instantiate model
model = Sequential()
# we can think of this chunk as the input layer
model.add(Dense(64, input_dim=14, init=‘uniform‘))
model.add(BatchNormalization())
model.add(Activation(‘tanh‘))
model.add(Dropout(0.5))
# we can think of this chunk as the hidden layer
model.add(Dense(64, init=‘uniform‘))
model.add(BatchNormalization())
model.add(Activation(‘tanh‘))
model.add(Dropout(0.5))
# we can think of this chunk as the output layer
model.add(Dense(2, init=‘uniform‘))
model.add(BatchNormalization())
model.add(Activation(‘softmax‘))
# setting up the optimization of our weights
sgd = SGD(lr=0.1, decay=1e-6, momentum=0.9, nesterov=True)
model.compile(loss=‘binary_crossentropy‘, optimizer=sgd)
# running the fitting
model.fit(X_train, y_train, nb_epoch=20, batch_size=16, show_accuracy=True, validation_split=0.2, verbose = 2)
改完之后结果确实收敛了
标签:神经元 hid poc sof moment 区域 port img oid
原文地址:https://www.cnblogs.com/gaowenxingxing/p/12819927.html