标签:top def size 每日 net ext rod 信息 bsp
//使用kafka+sparkStreaming进行数据处理
//从kafka拉取数据
package com.swust.predict
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.{DStream, InputDStream}
import org.apache.spark.streaming.kafka010.ConsumerStrategies.Subscribe
import org.apache.spark.streaming.kafka010.{CanCommitOffsets, HasOffsetRanges, KafkaUtils, OffsetRange}
import org.apache.spark.streaming.kafka010.LocationStrategies.PreferConsistent
import org.apache.spark.streaming.{Seconds, StreamingContext}
object GetDataFromKafka {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("GetDataFromKafka").setMaster("local[*]")
conf.set("spark.streaming.kafka.consumer.cache.enabled","false")
val ssc = new StreamingContext(conf,Seconds(5))
val topics = Set("car_events")
val brokers = "data001:9092,data003:9092,data004:9092"
val kafkaParams = Map[String,Object](
"bootstrap.servers" -> brokers,
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "predictGroup",//
"auto.offset.reset" -> "latest",
"enable.auto.commit" -> (false: java.lang.Boolean)//默认是true
)
val index = 1
//创建Dstream
val kafkaDstream: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream(
ssc,
PreferConsistent,
Subscribe[String, String](topics, kafkaParams)
)
val events: DStream[String] = kafkaDstream.map(line => {
val value: String = line.value().toString
value
})
val show: Unit = events.foreachRDD(rdd => {
rdd.foreachPartition(data => {
//data.take(200)
data.foreach(one => {
println(one)
})
})
})
// events.foreachRDD(rdd =>{
// val ranges: Array[OffsetRange] = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
// events.asInstanceOf[CanCommitOffsets].commitAsync(ranges)
// })
ssc.start()
ssc.awaitTermination()
}
}
//向kafka推送数据
package com.traffic.streaming
import java.util.Properties
import net.sf.json.JSONObject
import org.apache.kafka.clients.producer.{KafkaProducer, ProducerRecord}
import org.apache.spark.{SparkConf, SparkContext}
//向kafka car_events中生产数据
object KafkaEventProducer {
def main(args: Array[String]): Unit = {
//设置需要写入数据的消息队列
val topic = "car_events"
//设置配置属性信息
val props = new Properties()
props.put("bootstrap.servers", "data001:9092,data003:9092,data004:9092")
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer")
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer")
//创建kafka消息队列的生产者对象
val producer = new KafkaProducer[String,String](props)
val sparkConf = new SparkConf().setAppName("traffic data").setMaster("local[4]")
val sc = new SparkContext(sparkConf)
val records: Array[Array[String]] = sc.textFile("F:\\code\\AnyMaven\\data\\carFlow_all_column_test.txt")
.filter(!_.startsWith(";")) //过滤掉不以;开头的数据
.map(_.split(",")).collect()
for (i <- 1 to 1000) {
for (record <- records) {
// prepare event data
val event = new JSONObject()
event.put("camera_id", record(0))
event.put("car_id", record(2))
event.put("event_time", record(4))
event.put("speed", record(6))
event.put("road_id", record(13))
// produce event message
//向kafka中输入数据
producer.send(new ProducerRecord[String, String](topic, event.toString))
// println("Message sent: " + event)
Thread.sleep(200)
}
}
sc.stop
}
}
//运行结果
//向kafka集群拖送数据
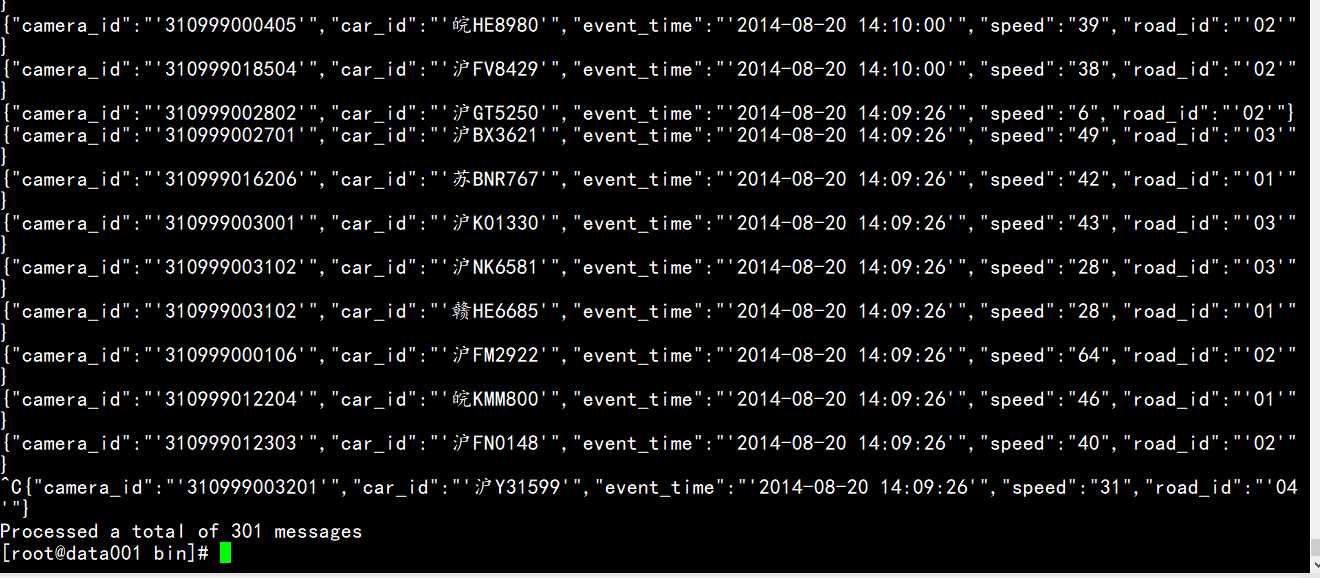
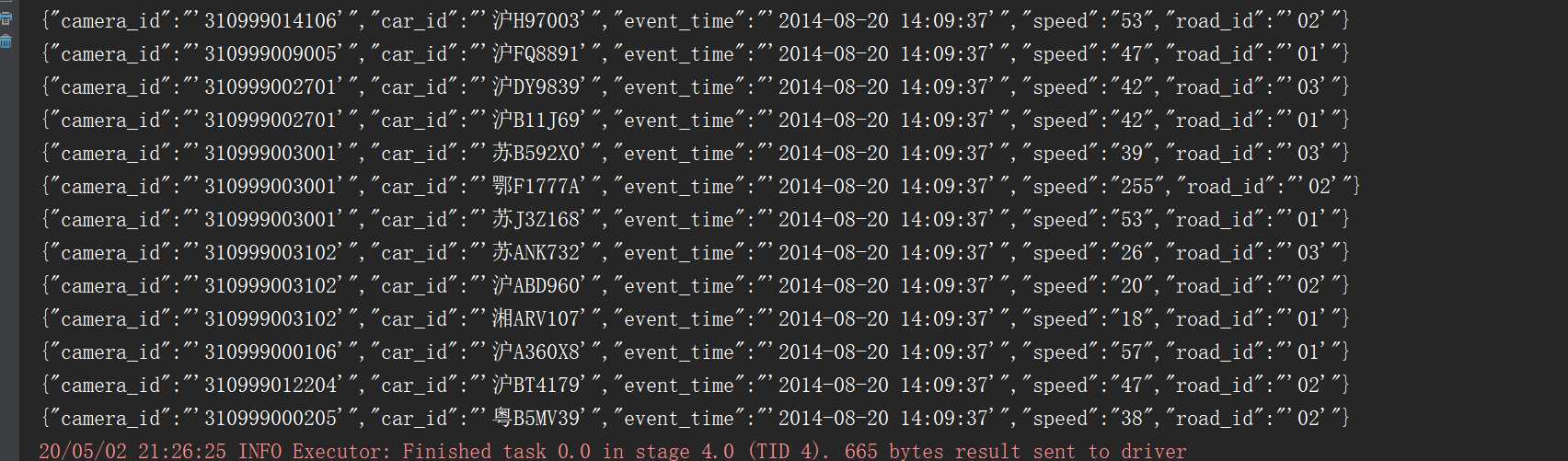
//从kafka集群拉取数据
标签:top def size 每日 net ext rod 信息 bsp
原文地址:https://www.cnblogs.com/walxt/p/12819736.html