标签:host 校验和 copyto com 硬件 dir 分布式文件 分布式文件系统 map
一、简介
Hadoop是使用Java编写,允许分布在集群,使用简单的编程模型的计算机大型数据集处理的Apache的开源框架。
解决的问题:
(1)海量数据的存储 [HDFS]
(2)海量数据的分析 [MapReduce]
(3)资源管理调度 [YARN]
二、hadoop架构
在其核心,Hadoop主要有两个层次,即:
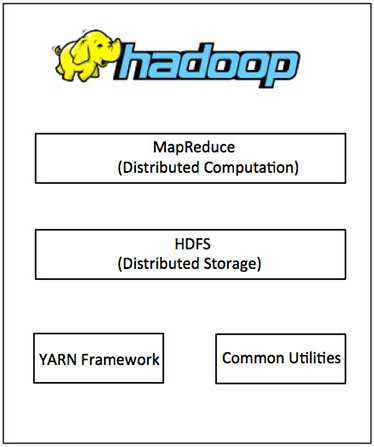
除了上面提到的两个核心组件,Hadoop的框架还包括以下两个模块:
Hadoop通用:这是Java库和其他Hadoop组件所需的实用工具。
Hadoop YARN :这是作业调度和集群资源管理的框架。
Hadoop运行整个计算机集群代码。这个过程包括以下核心任务由 Hadoop 执行:
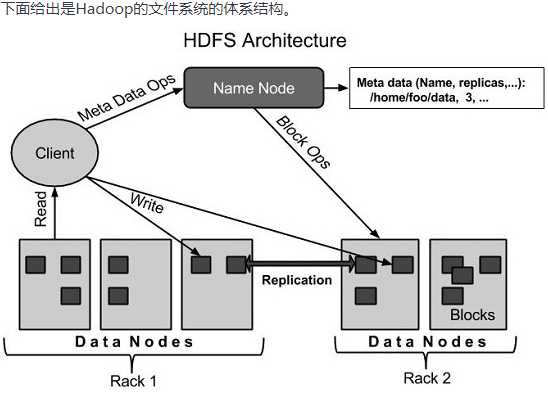
————————————————————————————————————————————
(1)名称节点 - Namenode
它执行以下任务:

-ls
使用方法:hadoop fs -ls [-h] [-R] <args>
功能:显示文件、目录信息。
-h优化文件大小显示
-R查出文件夹及其子文件的所有信息
-mkdir
使用方法:hadoop fs -mkdir [-p] <paths>
功能:在 hdfs 上创建目录,-p 表示会创建路径中的各级父目录。
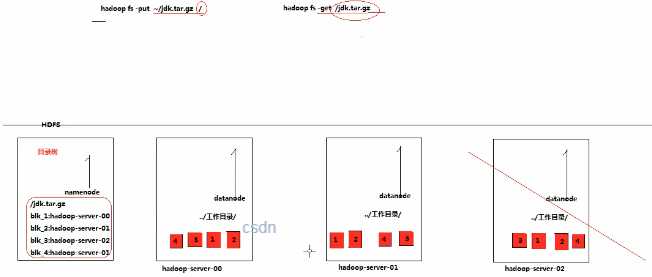
-put
使用方法:hadoop fs -put [-f] [-p] [ -|<localsrc1> .. ]. <dst>
功能:将单个 src 或多个 srcs 从本地文件系统复制到目标文件系统。
-p:保留访问和修改时间,所有权和权限。
-f:覆盖目的地(如果已经存在)
示例:hadoop fs -put -f localfile1 localfile2 /user/hadoop/hadoopdir
-get
使用方法:hadoop fs -get [-ignorecrc] [-crc] [-p] [-f] <src> <localdst>
-ignorecrc:跳过对下载文件的 CRC 检查。
-crc:为下载的文件写 CRC 校验和。 功能:将文件复制到本地文件系统。
示例:hadoop fs -get hdfs://host:port/user/hadoop/file localfile
-appendToFile
使用方法:hadoop fs -appendToFile <localsrc> ... <dst>
功能:追加一个文件到已经存在的文件末尾
注:hdfs不能进行修改,但是可以进行追加
示例:hadoop fs -appendToFile localfile /hadoop/hadoopfile
-cat
使用方法:hadoop fs -cat [-ignoreCrc] URI [URI ...]
功能:显示文件内容到 stdout
示例:hadoop fs -cat /hadoop/hadoopfile
-tail
使用方法:hadoop fs -tail [-f] URI
功能:将文件的最后一千字节内容显示到 stdout。
-f 选项将在文件增长时输出附加数据。 示例:hadoop fs -tail /hadoop/hadoopfile
-chgrp
使用方法:hadoop fs -chgrp [-R] GROUP URI [URI ...]
功能:更改文件组的关联。用户必须是文件的所有者,否则是超级用户。
-R 将使改变在目录结构下递归进行。
示例:hadoop fs -chgrp othergroup /hadoop/hadoopfile
-chmod
功能:改变文件的权限。使用-R 将使改变在目录结构下递归进行。 示例:hadoop fs -chmod 666 /hadoop/hadoopfile
-chown
功能:改变文件的拥有者。使用-R 将使改变在目录结构下递归进行。 示例:hadoop fs -chown someuser:somegrp /hadoop/hadoopfile
-copyFromLocal
使用方法:hadoop fs -copyFromLocal <localsrc> URI
功能:从本地文件系统中拷贝文件到 hdfs 路径去
示例:hadoop fs -copyFromLocal /root/1.txt /
-copyToLocal
功能:从 hdfs 拷贝到本地
示例:hadoop fs -copyToLocal /aaa/jdk.tar.gz
-cp
功能:从 hdfs 的一个路径拷贝 hdfs 的另一个路径
示例: hadoop fs -cp /aaa/jdk.tar.gz /bbb/jdk.tar.gz.2
-mv
功能:在 hdfs 目录中移动文件
示例: hadoop fs -mv /aaa/jdk.tar.gz /
-getmerge
功能:合并下载多个文件
示例:比如 hdfs 的目录 /aaa/下有多个文件:log.1, log.2,log.3,... hadoop fs -getmerge /aaa/log.* ./log.sum
-rm
功能:删除指定的文件。只删除非空目录和文件。-r 递归删除。 示例:hadoop fs -rm -r /aaa/bbb/
-df
功能:统计文件系统的可用空间信息
示例:hadoop fs -df -h /
-du
功能:显示目录中所有文件大小,当只指定一个文件时,显示此文件的大小。
示例:hadoop fs -du /user/hadoop/dir1
-setrep
功能:改变一个文件的副本系数。-R 选项用于递归改变目录下所有文件的副本 系数。
注:实际中这个功能不常用,副本大小会预先定义好。
示例:hadoop fs -setrep -w 3 -R /user/hadoop/dir1
标签:host 校验和 copyto com 硬件 dir 分布式文件 分布式文件系统 map
原文地址:https://www.cnblogs.com/feixian-blog/p/12291234.html