标签:详细 人人 排序 分数线 不能 审核 质量 欺诈 href
信用评分模型的出现改变了传统人工信贷审批过程低效的局面,为自动化审批开启了一扇大门,从而充分发挥出规模经济的优势。但是,无论多智能的模型终归只是一个工具,它无法完全代替人来审核人,在业务中起关键作用的还是人的决策。
模型优势在于准确、客观、自动化,人工优势在于灵活、善于推理、有业务温度。因此,若能将人和模型的优势有机结合,那么就能达到“1+1>2”的效果。
目录
Part 1. 风控系统流程
Part 2. 决策否决(Override)的概念
Part 3. 决策否决的原因
Part 4. 决策否决的建议
Part 5. 否决报告记录及报表
Part 6. 否决报告对模型优化的指导
致谢
版权声明
参考资料
当前P2P互金公司的风控流程一般可以简化为以下几个必要模块,实际风控流程则要复杂得多,包含各细节分支,比如按新客老客、获客渠道会有不同的分支去处理。一般而言,老客风险都较低,因此流程就会简略;新客风险高,审批流程就会拉长。( 新客风险识别也是一个值得探讨的命题)
 图 1 - 风控流程简化版(仅供参考)
图 1 - 风控流程简化版(仅供参考)
信用评分模型帮助我们批量有效地处理信贷审批流程,在某个最低评分阈值(cutoff)上,信用策略给出通过(accept)的决策,反之予以拒绝(reject)。
但在实际业务中,我们可能并不会严格按照信用评分进行决策。对于某些用户,我们可能会在人工信审中给出与信用评分完全不同的结论,这种前后决策不一致的现象,我们称之为Override(否决)。
我们一般可分为以下两种情况:
 图 2 - 否决矩阵
图 2 - 否决矩阵
根据图2所示否决矩阵,我们又可以得到以下指标:
否决比例(override ratio)通常依赖于信贷产品属性,并受到很多因素制约。
这也是大数据风控和传统风控之间的一个差异点。
既然评分卡模型是在成千上万个样本中学习得到的模式,相比于人工决策更加真实客观,那么为什么还需要人工介入呢?主要有以下原因:
低端否决是在从"劣质"人群(低信用分)中捞回,如果人工判断有误(或者有意放水),那就会导致资产质量下降,引入更多坏账;而过多的高端否决则会导致"优质"人群(高信用分)流失。
因此,我们一般会控制否决比例,以模型决策为主,人工信审为辅,不应本末倒置,从而导致审批效率低下,回到原始时代。
那么,怎样的否决分布才是合理的呢?在灰色地带(cutoff附近),代表模型给出的决策模棱两可,那么否决比例会比较高。但如果模型是具有排序性的,那么离cutoff越远,好坏的界限就应该越清晰,否决比例也应该越低。因此,否决分布呈现cutoff处高,而往低分段和高分段呈现衰减趋势,如图3所示。注意,实际否决分布并不一定服从正态分布,而且最大否决比例也是因各家而异。
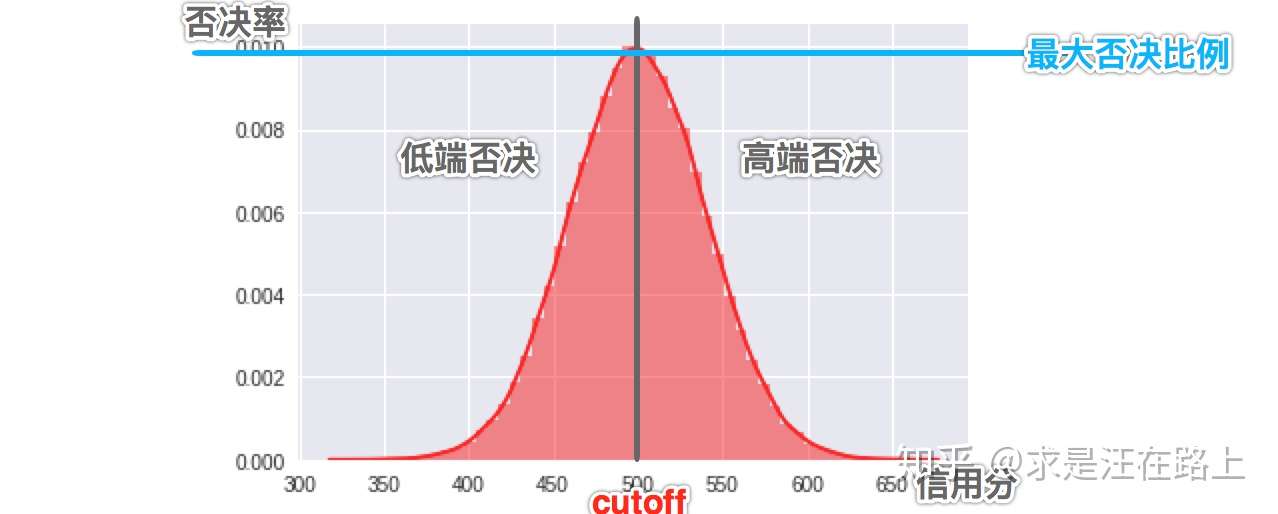 图 3 - 合理的否决分布
图 3 - 合理的否决分布
人工否决时,需要详细记录否决原因(override reason code),便于追溯案件和可解释性,这将是一块宝贵的数据。另一方面,否决报告也将约束规范信审人员行为,降低操作风险(operation risk)。例如,内外勾结,联合骗贷。
设计否决报告日志,可考虑落实到日期、否决原因、产品线、订单号、借款人、模型编号、信用分、信审人员。其中否决原因可由信审主管组织大家头脑风暴,确定否决原因的大类、小类以及其他(为应对新出现的事件)。
 图 4 - 否决报告日志
图 4 - 否决报告日志
同时,我们也需要周期性统计否决原因分布,形成报表。
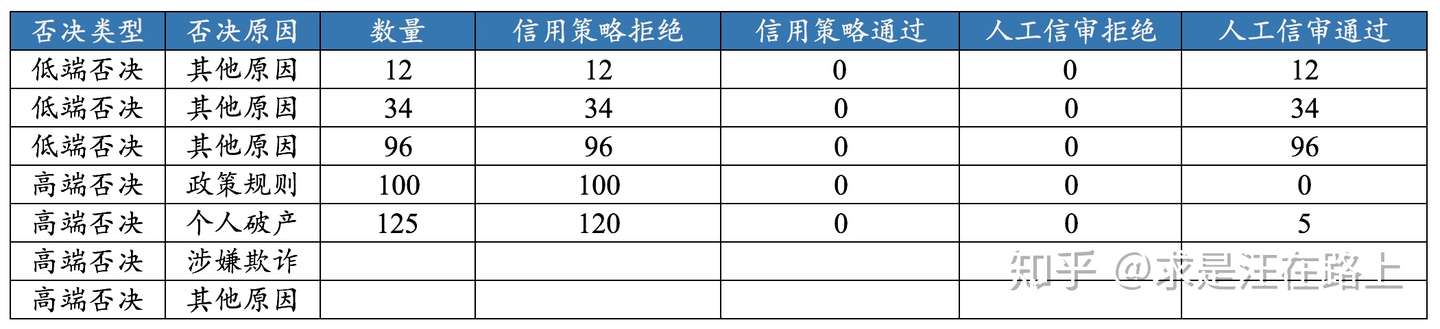 图 5 - 否决统计报表
图 5 - 否决统计报表
风控模型在迭代过程中总会遇到瓶颈——我们该如何寻找优化思路?
如果我们的模型足够好,那么人工否决比例就会很低,也就是说两者的一致性会很高。从这个角度看,模型优化的思路可以从否决样本上去寻找。
例如,人工信审给出一批借款人的信用卡账单消费地点与平时生活地点并不一致,那么我们就有理由怀疑账单造假。因此,我们将在反欺诈模型中加入“消费地点与平时活动地点是否一致”的特征来提升模型。
感谢参考资料中的作者,尤其是《现代信用卡管理》的作者——陈健老师。本文主要是一些阅读笔记,仍有理解不到位之处。
欢迎转载分享,请在文章中注明作者和原文链接,感谢您对知识的尊重和对本文的肯定。
原文作者:求是汪在路上(知乎ID)
原文链接:https://zhuanlan.zhihu.com/p/81152807/
??著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处,侵权转载将追究相关责任。
标签:详细 人人 排序 分数线 不能 审核 质量 欺诈 href
原文地址:https://www.cnblogs.com/cx2016/p/12820920.html