标签:打开 exce dem lte ext 爬取 http raise html
1.主题:百度新闻爬取
2.
python代码:
import requests
from bs4 import BeautifulSoup
def getHTMLText(url):
try:
r = requests.get(url,timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""
def filllist(demo):
soup=BeautifulSoup(demo,"html.parser")
for i in soup.find_all("a"):
list1=i.attrs
print(i.text,end=‘ ‘)
print(list1[‘href‘])
def main():
url="http://news.baidu.com/"
demo=getHTMLText(url)
getHTMLText(url)
filllist(demo)
main()
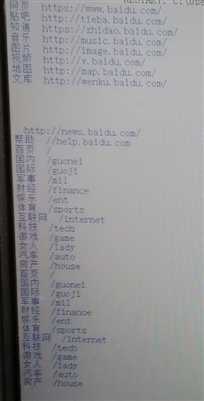
代码完成之后就是这个样子

3.问题:在代码编写过程中,我遇到了很多问题,比如一开始用find函数总是出现错误,我也是看大家的代码才找到正确的打开方式。
另外开始是这样的,一下子所有的属性都打出

我的本意是只要链接的那部分属性,经过反复看视频和多次的实验终于解决了这个难题,形成了开头那个样子。很开心!
但是开头和结尾还是有多余的部分不知道怎么解决,求助!

标签:打开 exce dem lte ext 爬取 http raise html
原文地址:https://www.cnblogs.com/732jbw/p/12820719.html