标签:简洁 前言 超越 ima 安装 src 成就感 爱奇艺 request
前言
曾经年少无知,笑对python爬虫。
如今首战未捷,却已头顶清凉...
奈何心中执着,不愿面对结果。
若有江湖侠客,还望拔刀相助!
思路
网站选取的是爱奇艺的电影排行
requests和bs4库的安装也较为轻松
爬取的过程比较顺利,问题出现在对信息的处理上
处理过程:1.简单了解函数find_all()
2.在漫漫代码海中寻找有用信息【红】& 标签【黄】(如下)


3.于是有代码诞生: soup.find_all(‘p‘,"site-piclist_info_title");
but,康康运行结果....
源代码:
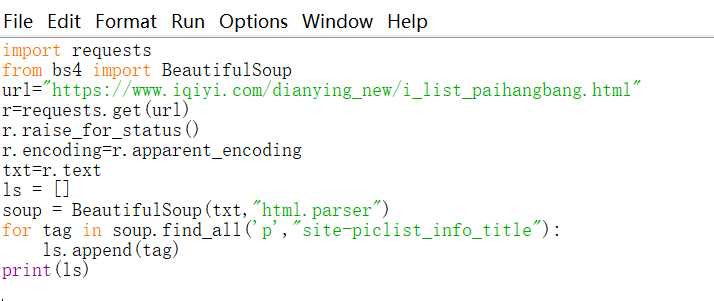
运行结果:

问题:
1.影片名(有重复)且缩在一堆代码中间...怎么弄出来??
2.除了find_all()函数,有没有更简洁的直接将文字信息提取出来的方法??
总结:
这是一个神奇的过程,尝试尝试再尝试,上头上头还是上头...
但这也是一个很快乐的过程,一直在探索,暂且不说结果或许不尽如人意,但是过程中但凡有的一点点进步,小的胜利,都让人无比愉悦,成就感爆棚。
我想,实践,大概就是编程的魅力所在吧,一直在尝试,一直在超越。
加油哦!
标签:简洁 前言 超越 ima 安装 src 成就感 爱奇艺 request
原文地址:https://www.cnblogs.com/zzyyy/p/12821148.html