标签:ring 除了 关系 实战 produce rto https 一个 读写
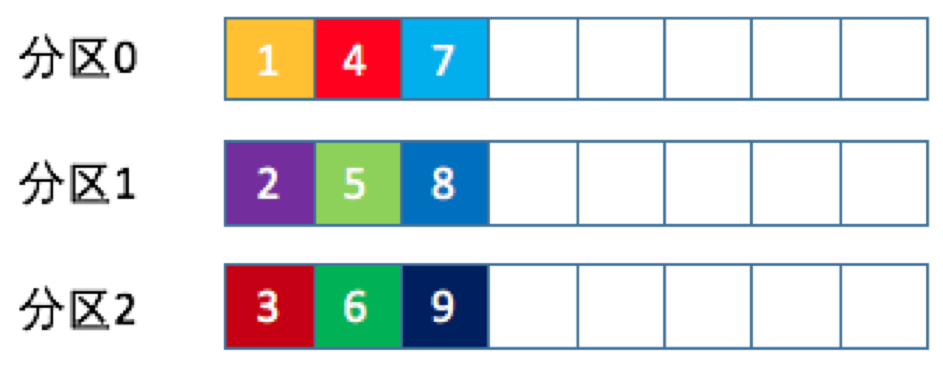
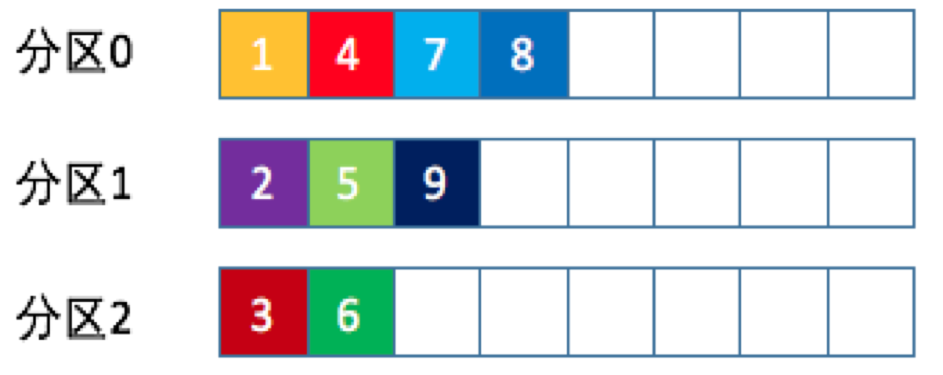
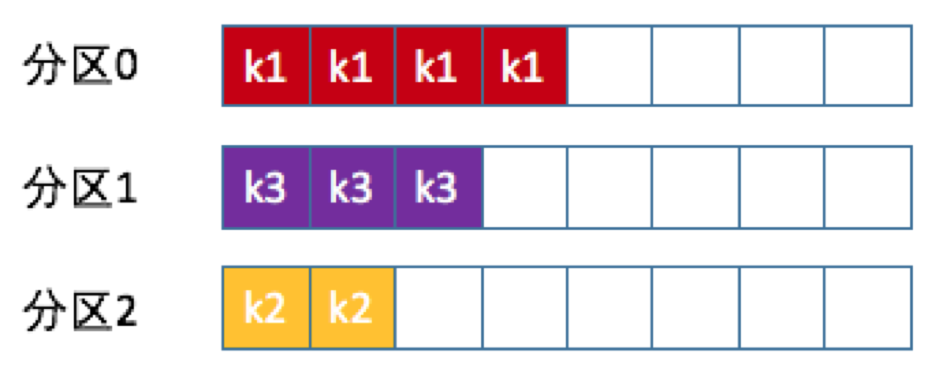
Kafka核心技术与实战——09 | 生产者消息分区机制原理剖析
原文地址:https://www.cnblogs.com/minimalist/p/12821602.html