标签:爬虫 图片 比较 code 工作 inf mamicode 而且 image
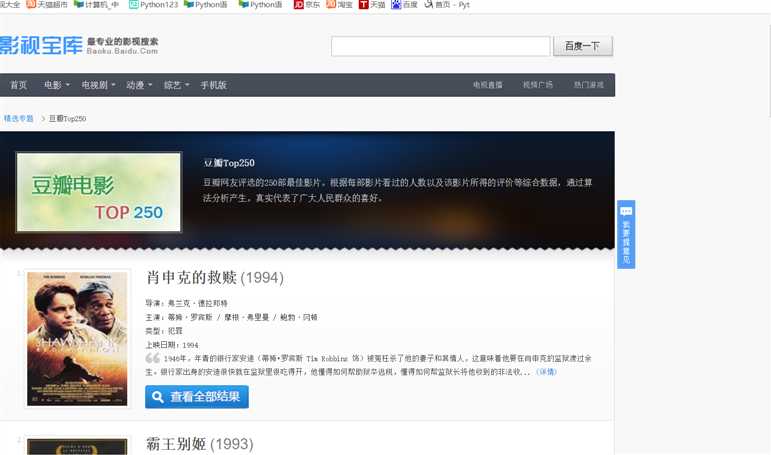
1.主题:豆瓣电影top250的爬取
2.requests库和beautifulsoup4的安装
中间遇到了一次pip的升级,整体的安装还是比较顺利的
3.在看了requests库和beatufulsoup4库的用法后就开始做了
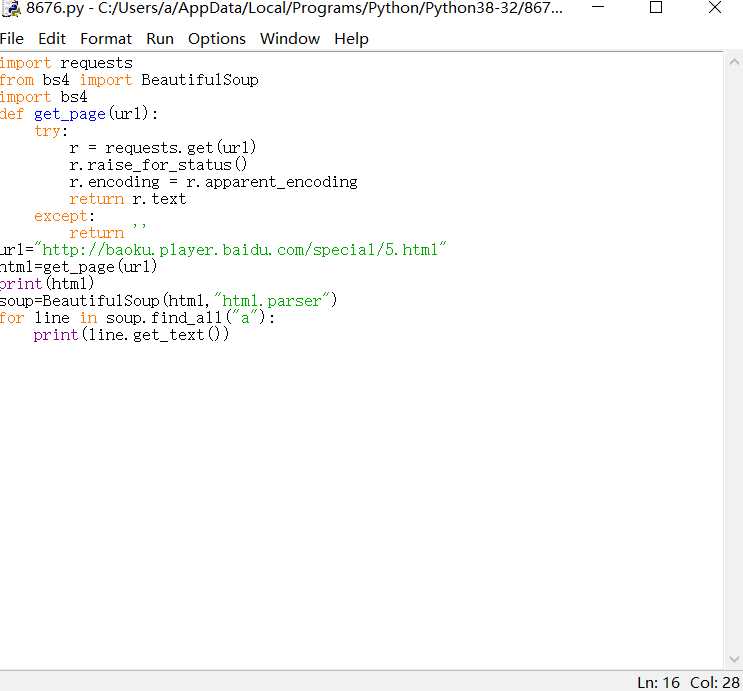
做的还是比较简单

遇到的困难:事实上这个网站是经过了5次的实验才得到的可以用的,之前的网站是不能被爬取的

本来打算用这个做的,爬起来理论上也相对比较简单,可是
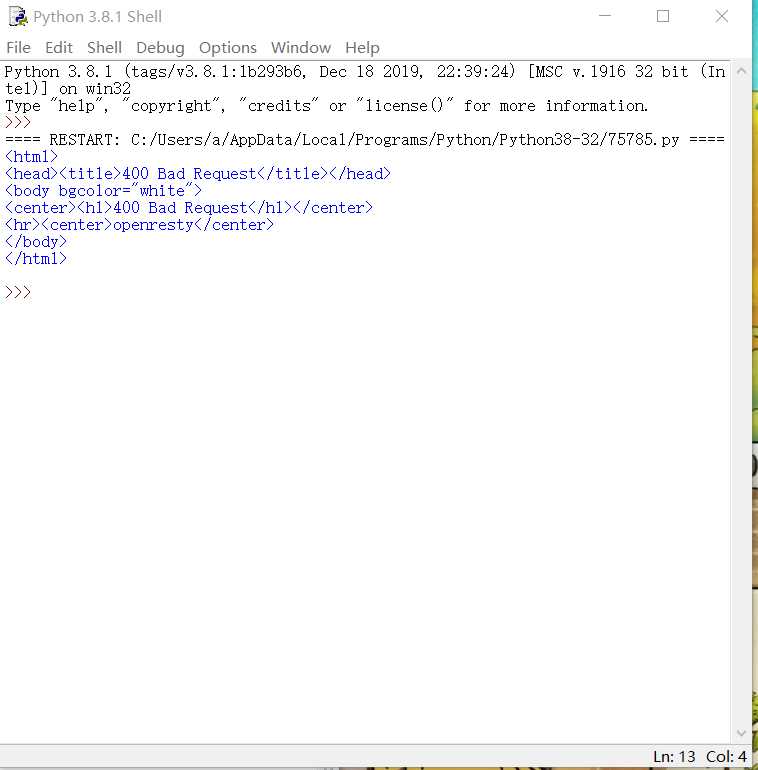
这就难受坏了,我对着电脑,喊着“给我爬!”
网站不让爬,那只能我爬了,不得不说找网站真的是很耗时的工作。
而且这样好像只能爬取一个网页的内容,想要爬取“下一页”的内容又会很麻烦,想要得到整整250个数据还是很难的任务。
技术有限,也就能做到这里了,还是希望可以与同学们交流,得到大家的帮助。
标签:爬虫 图片 比较 code 工作 inf mamicode 而且 image
原文地址:https://www.cnblogs.com/lzplzp123/p/12822719.html