标签:gbk enc 针对 经验 targe 中文 microsoft 爬虫 遇到
本篇文章很短,只是作为一个小技巧分享
今天在分析某网站的时候,遇到一个神奇的编码,如下
13555555555
不管我怎么搞都解码不出来,查了下,说的是在 Node 层利用 cheerio 解析网页时,输出的中文内容都是以 &#x 开头的一堆像乱码一样的东西,尝试过各种编码都无效,而且神奇的是,将这一堆“乱码”保存成网页后,通过浏览器打开又可以正常显示,凭我多年的爬虫分析经验来看,这应该就是我要的东西,并不是随机生成的,想了很久,我突然想起了一种html的页码表现形式,有没有觉得很像那种html的特征码,比如 空格就是 以上的数据,格式是是不是非常像
搜了下,说的是这种形式是numeric character reference,数字取值为目标字符的 Unicode code point;以「&#」开头的后接十进制数字,「&#x」开头的后接十六进制数字。
从 HTML4 开始,numeric character reference 以 Unicode 为准,与文档编码无关。
我突然想起,之前遇到过一个网站,他的数据就是这样的,用lxml库里的fromtring就可以解析出来
于是:
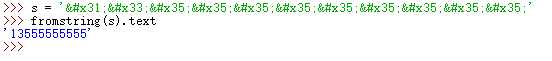
from lxml.html import formstring
s = ‘13555555555‘
print(fromstring(s).text)
‘13555555555‘
后面发现,其实还有一种方法可以解决:

s = ‘13555555555‘
k = s.replace(‘;‘, ‘‘).replace(‘&#x‘, r‘\u00‘).encode(‘utf-8‘).decode(‘unicode-escape‘)
pirnt(k)
# ‘13555555555‘
unicode-escape和unicode是同级别的一种字符集,但是很少用,针对一些特殊情况时会用,其实还有string-escape,其实这两个我搜了下资料,感觉看了跟没看一样,我写这个博客的5分钟以前看了的,我现在都忘了说的啥了,反正说白了就是在解析一些数据无法正常解析时,就可以使用unicode-escape
顺便一说,在解析时的编码,如果utf-8,gbk,gb2312都无法解析,可以用gb18030解码
标签:gbk enc 针对 经验 targe 中文 microsoft 爬虫 遇到
原文地址:https://www.cnblogs.com/Eeyhan/p/12822979.html