标签:影响 tooltip orm 内容 价值 fill alt ngx 网址
一、目的 :
爬取晋江文学网总分榜
二、python爬取数据
网址:http://www.jjwxc.net/topten.php?orderstr=7&t=0
三、爬取

在开始多出现了38号而且顺序内容不准确
代码:
import requests
from bs4 import BeautifulSoup
import bs4
url="http://www.jjwxc.net/topten.php?orderstr=7&t=0"
def getHtml(url):
r=requests.get(url)
r.raise_for_status()
r.encoding=r.apparent_encoding
return r.text[26000:100000]
def fillList(html):
l1,l2 = [],[]
soup = BeautifulSoup(html,"html.parser")
for i in soup.find_all(‘a‘,"tooltip"):
l1.append(str(i.string))
for tag in soup.find_all(‘td‘,{"align":"center"}):
s=str(tag.string)
s.replace(" "," ")
l2.append(s)
return l1,l2
def printList(l1,l2):
n1,n2 = len(l1),len(l2)
n=max(n1,n2)
for i in range(n):
print("第{}名:《{}》".format(i+1,l1[i]))
print("积分:{}".format(l2[i]))
print("")
def main():
html=getHtml(url)
l1,l2=fillList(html)
printList(l1,l2)
main()
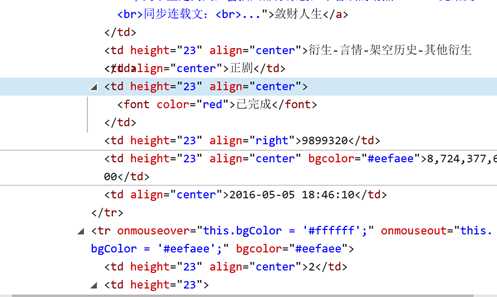

这几类数据我分不开,绝望
百度了一下就发现
内容网址:https://www.cnblogs.com/wangyongfengxiaokeai/p/11869595.html
而且好像height=‘23’和alig前后位置不同对结果也有影响
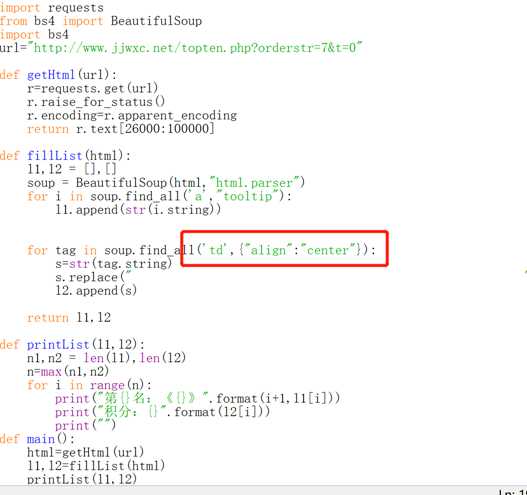
又换了试就发现是红框的问题,但是红框内换了几次代码还是都不能完全分开,最后只有l2中为作品字数时可以完全带进去,但是字数在这里没有什么实际价值。
标签:影响 tooltip orm 内容 价值 fill alt ngx 网址
原文地址:https://www.cnblogs.com/ZZRlomaz/p/12824598.html