标签:就是 strong image solution sub group ams lse 字母
题目:
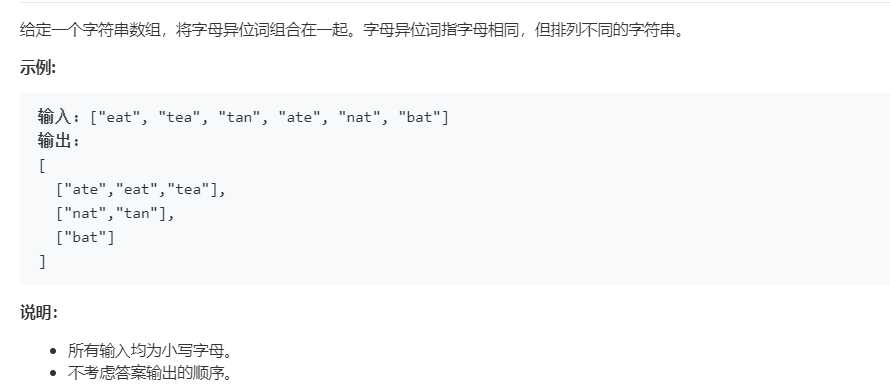
解答:
因为要找组成一样的单词,如何判断?
最简单的,一排序,如果是同一个单词,那么就是组成一样的。
比如 “eat” "tea" 排序后都为 “aet”。
只要引入一个hash表,索引是排序后的单词,值为结果vector的下标,循环一遍就好了。
1 class Solution { 2 public: 3 vector<vector<string>> groupAnagrams(vector<string>& strs) 4 { 5 vector<vector<string>> res; 6 int sub=0; //结果vector的下标值 7 string tmp; //临时string 8 9 unordered_map<string,int> work; //判断排序后单词是否存在,即字母组成是否一致 10 for(auto str:strs) 11 { 12 tmp=str; 13 sort(tmp.begin(),tmp.end()); 14 if(work.count(tmp)) 15 { 16 res[work[tmp]].push_back(str); 17 } 18 else 19 { 20 vector<string> vec(1,str); 21 res.push_back(vec); 22 work[tmp]=sub++; 23 } 24 } 25 return res; 26 } 27 };
标签:就是 strong image solution sub group ams lse 字母
原文地址:https://www.cnblogs.com/ocpc/p/12825924.html