标签:inter 影响 src alt cti 复杂度 article div 分类
在自然语言处理中,我们该怎样从语料中提取信息?语料是string的形式,无法计算,所以我们必须要把语料用向量表示。
最先引入最基本的表示方法 One Hot,根据词在词汇表的位置来表示这个词。
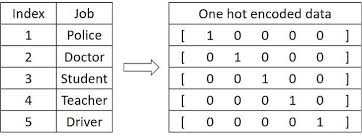
表示后怎么用呢?一个朴素的概念是,当我们知道了上文,就能预测下个词是什么。设我们要预测的词语是\(w_k\),它前面有\(k-1\)个词语,那么到了第\(k\)个词时为\(w_k\)的概率是:
那么如何求的下个词的概率 \(P(w_1,w_2,w_3,...,w_k)\) ?
最朴素的思想,把其中每一个子项的概率全部求解出来,每一项都有 \(P(w_k|w_{1}^{k-1})=\frac{P(w_{1}^{k})}{P(w_{1}^{n-1})}\approx \frac{Count(w_{1}^{k})}{Count(w_{1}^{k-1})}\) ,只要求出来每一项,就知道下个词为的概率 \(w_k\) 了,这就是统计语言模型。
但显然基于统计的语言模型复杂度非常高,遍历统计每种几率不现实,所以逐步发展出了N-gram模型、基于神经网络的模型……
在上一节中,计算每一项 \(Count(w_{1}^{k})\) 是唯一耗时。为了简化问题,我们做一个假设,每个词的出现概率,只和它前面的N个词语有关,这就是N-gram模型了。
根据N-gram,我们有
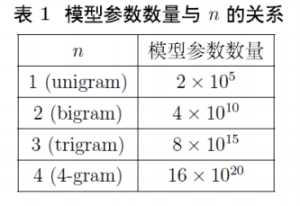
这样一来,需要统计的数量就变少了。那么 \(n\) 取多少呢?一般来说要考虑到模型复杂度和模型效果。复杂度方面,假定词汇有N=2*10^5个,由于整体复杂度是 \(O({N}^{n})\) ,因此一般不会取太大的n。实践中一般取n=3,称为 Three-Gram Model (三元模型)。
N-gram思路将计算的窗口范围缩减到了n个,但是仍然是一个统计概率语言模型,基于统计去进行概率估计。就像分类问题我们可以建模成神经网络模型,在语言模型中我们也可以引入神经网络的结构,通过训练每层之间的参数,拟合出语言概率的结果,这就是NNLM。
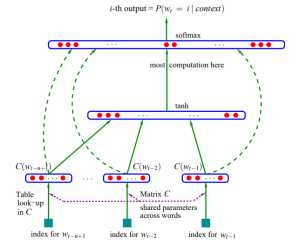
第一层是输入层,设每个词语是长度为 m 的 “distribution representation” 向量,一共有 n 个词,那么输入层shape 就是 (n, m)
第二层是投影层,把输入的每个词concat起来,输出shape = (1, nm)
第三层是隐藏层,是一个Dense(activation=‘tanh‘)的全连接,有参数 W 和 b 在这里训练,设隐藏层的输出是 h 维的(这里一般较小的数字就可以了,因为很影响计算量),那么输出shape = (nm, h)
第四层是输出层,是一个Dense(activation=‘tanh‘)的全连接softmax输出。有参数也在这一层训练。同时输出的向量大小是 (|V|, 1),|V|就是词汇表的大小。
标签:inter 影响 src alt cti 复杂度 article div 分类
原文地址:https://www.cnblogs.com/hxmp/p/WordRepresentation-OneHot-NGRAM-NNLM-Word2Vec.html