标签:耦合性 form 机器学习 参数 ova net 文章 AMM normal
to do
https://zhuanlan.zhihu.com/p/34879333
https://zhuanlan.zhihu.com/p/69659844
https://zhuanlan.zhihu.com/p/54530247


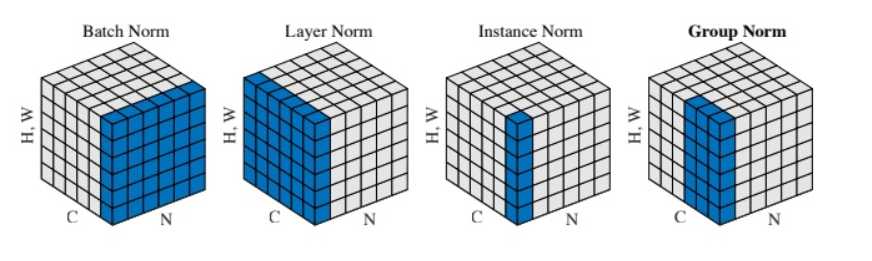
比如给定[N,C,HW],在[N,HW]上计算均值向量[C], 方差向量[C]
我们解决了第一个问题,即用更加简化的方式来对数据进行规范化,使得第 [公式] 层的输入每个特征的分布均值为0,方差为1。
Normalization操作我们虽然缓解了ICS问题,让每一层网络的输入数据分布都变得稳定,但却导致了数据表达能力的缺失。也就是我们通过变换操作改变了原有数据的信息表达(representation ability of the network),使得底层网络学习到的参数信息丢失。

最好不要在测试阶段用,因为

非要用的话

BN通过规范化与线性变换使得每一层网络的输入数据的均值与方差都在一定范围内,使得后一层网络不必不断去适应底层网络中输入的变化,从而实现了网络中层与层之间的解耦,允许每一层进行独立学习,有利于提高整个神经网络的学习速度。
当学习率设置太高时,会使得参数更新步伐过大,容易出现震荡和不收敛。但是使用BN的网络将不会受到参数数值大小的影响

在神经网络中,我们经常会谨慎地采用一些权重初始化方法(例如Xavier)或者合适的学习率来保证网络稳定训练。
在不使用BN层的时候,由于网络的深度与复杂性,很容易使得底层网络变化累积到上层网络中,导致模型的训练很容易进入到激活函数的梯度饱和区;通过normalize操作可以让激活函数的输入数据落在梯度非饱和区,缓解梯度消失的问题;另外通过自适应学习 \(\gamma\) 与 \(\beta\) 又让数据保留更多的原始信息。
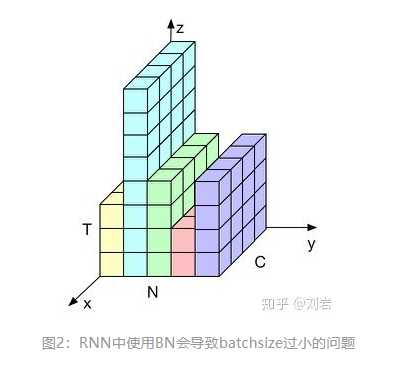
在Batch Normalization中,由于我们使用mini-batch的均值与方差作为对整体训练样本均值与方差的估计,尽管每一个batch中的数据都是从总体样本中抽样得到,但不同mini-batch的均值与方差会有所不同,这就为网络的学习过程中增加了随机噪音,与Dropout通过关闭神经元给网络训练带来噪音类似,在一定程度上对模型起到了正则化的效果。
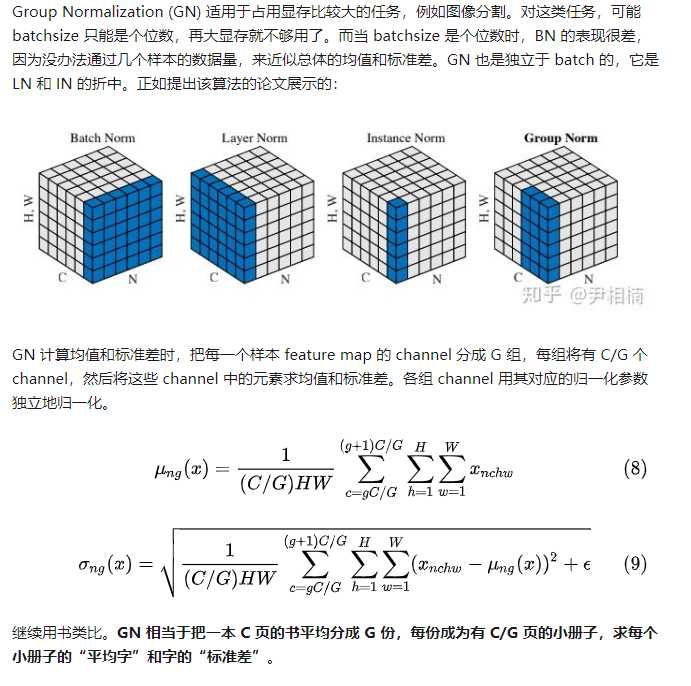
神经网络中有各种归一化算法:Batch Normalization (BN)、Layer Normalization (LN)、Instance Normalization (IN)、Group Normalization (GN)。从公式看它们都差不多,如 (1) 所示:无非是减去均值,除以标准差,再施以线性映射。


# coding=utf8
import torch
from torch import nn
# track_running_stats=False,求当前 batch 真实平均值和标准差,而不是更新全局平均值和标准差
# affine=False, 只做归一化,不乘以 gamma 加 beta(通过训练才能确定)
# num_features 为 feature map 的 channel 数目
# eps 设为 0,让官方代码和我们自己的代码结果尽量接近
bn = nn.BatchNorm2d(num_features=3, eps=0, affine=False, track_running_stats=False)
# 乘 10000 为了扩大数值,如果出现不一致,差别更明显
x = torch.rand(10, 3, 5, 5)*10000
official_bn = bn(x)
# 把 channel 维度单独提出来,而把其它需要求均值和标准差的维度融合到一起
x1 = x.permute(1,0,2,3).view(3, -1) # [N,C,H,W]==>[C,N,H,W]==>[C=3, N*H*W]
mu = x1.mean(dim=1).view(1,3,1,1) # [C, N*H*W]==>[C]==>[1, C, H, W]
std = x1.std(dim=1, unbiased=False).view(1,3,1,1)
# unbiased=False, 求方差时不做无偏估计(除以 N-1 而不是 N),和原始论文一致,个人感觉无偏估计仅仅是数学上好看,实际应用中差别不大
my_bn = (x-mu)/std
diff=(official_bn-my_bn).sum()
print(‘diff={}‘.format(diff)) # 差别是 10-5 级的,证明和官方版本基本一致
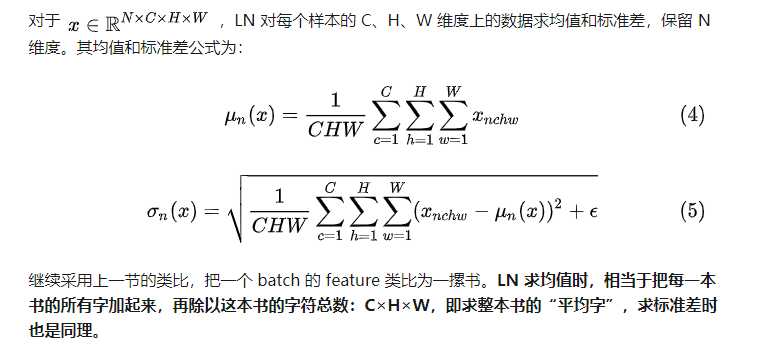
import torch
from torch import nn
x = torch.rand(10, 3, 5, 5)*10000
# normalization_shape 相当于告诉程序这本书有多少页,每页多少行多少列
# eps=0 排除干扰
# elementwise_affine=False 不作映射
# 这里的映射和 BN 以及下文的 IN 有区别,它是 elementwise 的 affine,
# 即 gamma 和 beta 不是 channel 维的向量,而是维度等于 normalized_shape 的矩阵
ln = nn.LayerNorm(normalized_shape=[3, 5, 5], eps=0, elementwise_affine=False)
official_ln = ln(x)
x1 = x.view(10, -1)
mu = x1.mean(dim=1).view(10, 1, 1, 1)
std = x1.std(dim=1,unbiased=False).view(10, 1, 1, 1)
my_ln = (x-mu)/std
diff = (my_ln-official_ln).sum()
print(‘diff={}‘.format(diff)) # 差别和官方版本数量级在 1e-5

import torch
from torch import nn
x = torch.rand(10, 3, 5, 5) * 10000
# track_running_stats=False,求当前 batch 真实平均值和标准差,
# 而不是更新全局平均值和标准差
# affine=False, 只做归一化,不乘以 gamma 加 beta(通过训练才能确定)
# num_features 为 feature map 的 channel 数目
# eps 设为 0,让官方代码和我们自己的代码结果尽量接近
In = nn.InstanceNorm2d(num_features=3, eps=0, affine=False, track_running_stats=False)
official_in = In(x)
x1 = x.view(30, -1)
mu = x1.mean(dim=1).view(10, 3, 1, 1)
std = x1.std(dim=1, unbiased=False).view(10, 3, 1, 1)
my_in = (x-mu)/std
diff = (my_in-official_in).sum()
print(‘diff={}‘.format(diff)) # 误差量级在 1e-5
import torch
from torch import nn
x = torch.rand(10, 20, 5, 5)*10000
# 分成 4 个 group
# 其余设定和之前相同
gn = nn.GroupNorm(num_groups=4, num_channels=20, eps=0, affine=False)
official_gn = gn(x)
# 把同一 group 的元素融合到一起
x1 = x.view(10, 4, -1)
mu = x1.mean(dim=-1).reshape(10, 4, -1)
std = x1.std(dim=-1).reshape(10, 4, -1)
x1_norm = (x1-mu)/std
my_gn = x1_norm.reshape(10, 20, 5, 5)
diff = (my_gn-official_gn).sum()
print(‘diff={}‘.format(diff)) # 误差在 1e-4 级

标签:耦合性 form 机器学习 参数 ova net 文章 AMM normal
原文地址:https://www.cnblogs.com/doragd/p/12827090.html