优点:
1. 可以用来解决分类和回归问题:随机森林可以同时处理分类和数值特征。
2. 抗过拟合能力:通过平均决策树,降低过拟合的风险性。
3. 只有在半数以上的基分类器出现差错时才会做出错误的预测:随机森林非常稳定,即使数据集中出现了一个新的数据点,整个算法也不会受到过多影响,它只会影响到一颗决策树,很难对所有决策树产生影响。
4. 能够处理很高维度(feature很多)的数据,并且不用做特征选择(特征列采样)
5. 对于不平衡的分类资料集来说,它可以平衡误差。
缺点:
1. 据观测,如果一些分类/回归问题的训练数据中存在噪音,随机森林中的数据集会出现过拟合的现象。
2. 比决策树算法更复杂,计算成本更高。
3. 由于其本身的复杂性,它们比其他类似的算法需要更多的时间来训练。
相关概念:
1.分裂:在决策树的训练过程中,需要一次次的将训练数据集分裂成两个子数据集,这个过程就叫做分裂。
2.特征:在分类问题中,输入到分类器中的数据叫做特征。以上面的股票涨跌预测问题为例,特征就是前一天的交易量和收盘价。
3.待选特征:在决策树的构建过程中,需要按照一定的次序从全部的特征中选取特征。待选特征就是在目前的步骤之前还没有被选择的特征的集合。例如,全部的特征是 ABCDE,第一步的时候,待选特征就是ABCDE,第一步选择了C,那么第二步的时候,待选特征就是ABDE。
4.分裂特征:接待选特征的定义,每一次选取的特征就是分裂特征,例如,在上面的例子中,第一步的分裂特征就是C。因为选出的这些特征将数据集分成了一个个不相交的部分,所以叫它们分裂特征。
问:随机森林随机在哪里?
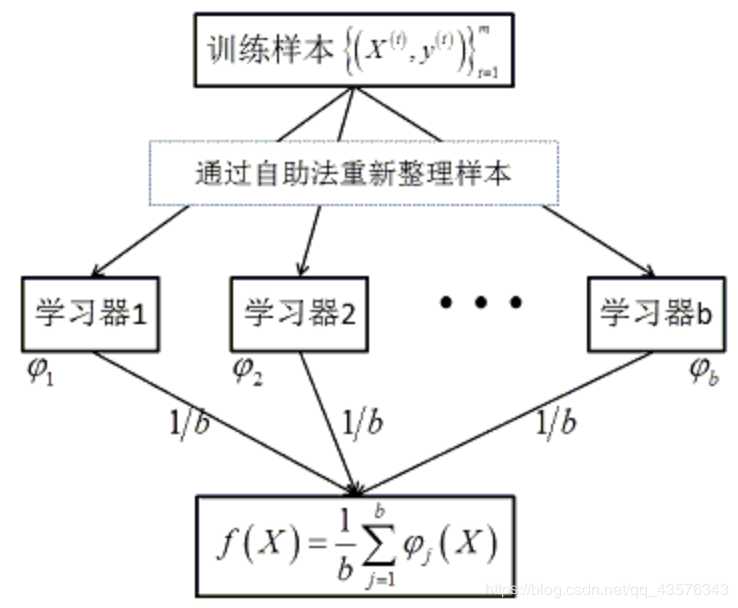
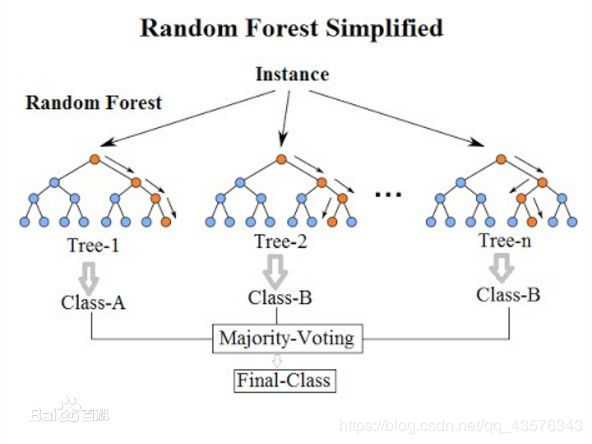
1.随机森林是一种组合方法,由许多的决策树组成,对于每一颗决策树,随机森林采用的是有放回的对N个样本分N次随 机取出N个样本,即这些决策树的形成采用了随机的方法,因此也叫做随机决策树。随机森林中的树之间是没有关联 的。当测试数据进入随机森林时,其实就是让每一颗决策树分别进行分类,最后取所有决策树中分类多的那类为最终 的结果。
2.随机森林的另一个"随机"点是对于每一个决策树,节点是按照从样本所有属性中随机抽取一定数量的属性进行分裂 的,并不是对所有属性进行考量,按照这种思路,其中不同的决策树就拥有了对样本中某些属性强有力判断的能力, 相当于每一颗决策树就是一个精通某些特定领域的专家,所有这些专家组合起来形成“强分类器”对样本进行投票。
和极限森林(ExtraForest)
extra trees是RF的一个变种, 原理几乎和RF一模一样,仅有区别有:
- 对于每个决策树的训练集,RF采用的是随机采样bootstrap来选择采样集作为每个决策树的训练集,而extra trees一般不采用随机采样,即每个决策树采用原始训练集。
- 在选定了划分特征后,RF的决策树会基于基尼系数,均方差之类的原则,选择一个最优的特征值划分点,这和传统的决策树相同。但是extra trees比较的激进,他会随机的选择一个特征值来划分决策树。
从第二点可以看出,由于随机选择了特征值的划分点位,而不是最优点位,这样会导致生成的决策树的规模一般会大于RF所生成的决策树。也就是说,模型的方差相对于RF进一步减少,但是偏倚相对于RF进一步增大。在某些时候,extra trees的泛化能力比RF更好。