标签:border false ble nbsp img http idt pos 一个
机器学习(ML),自然语言处理(NLP),信息检索(IR)等领域,评估(Evaluation)是一个必要的 工作,而其评价指标往往有如下几点:准确率(Accuracy),精确率(Precision),召回率(Recall)和F1-Measure。
TP: Ture Positive 把正的判断为正的数目 True Positive,判断正确,且判为了正,即正的预测为正的。
FN: False Negative 把正的错判为负的数目 False Negative,判断错误,且判为了负,即把正的判为了负的
FP: False Positive 把负的错判为正的数目 False Positive, 判断错误,且判为了正,即把负的判为了正的
TN: True Negative 把负的判为负的数目 True Negative,判断正确,且判为了负,即把负的判为了负的
【举例】一个班里有男女生,我们来进行分类,把女生看成正类,男生看成是负类。我们可以用混淆矩阵来描述TP、TN、FP、FN。
| 相关(Relevant),正类 | 无关(NonRelevant),负类 | |
| 被检索到(Retrieved) | True Positives(TP,正类判定为正类。即女生是女生) | False Positives(FP,负类判定为正类,即“存伪”。男生判定为女生) |
| 未被检索到(Not Retrieved) | False Negatives(FN,正类判定为负类,即“去真”。女生判定为男生) | True Negatives(TN,负类判定为负类。即男生判定为男生) |
准确率是指有在所有的判断中有多少判断正确的,即把正的判断为正的,还有把负的判断为负的;总共有 TP + FN + FP + TN 个,所以准确率:Acc = (TP+TN) / (TP+TN+FN+FP)
精确率是相对于预测结果而言的,它表示的是预测为正的样本中有多少是对的;那么预测为正的样本就有两种可能来源,一种是把正的预测为正的,这类有TruePositive个, 另外一种是把负的错判为正的,这类有FalsePositive个,因此精确率即:P= TP / (TP+FP)
召回率是相对于样本而言的,即样本中有多少正样本被预测正确了,这样的有TP个,所有的正样本有两个去向,一个是被判为正的,另一个是错判为负的,因此总共有TP+FN个,所以,召回率 R= TP / (TP+FN)
我们当然希望检索的结果P越高越好,R也越高越好,但事实上这两者在某些情况下是矛盾的。比如极端情况下,我们只搜出了一个结果,且是准确的,那么P就是100%,但是R就很低;而如果我们把所有结果都返回,那么必然R是100%,但是P很低。因此在不同的场合中需要自己判断希望P比较高还是R比较高。如果是做实验研究,可以绘制Precision-Recall曲线来帮助分析。
4.F-Measure
P和R指标有的时候是矛盾的,那么有没有办法综合考虑他们呢?我想方法肯定是有很多的,最常见的方法应该就是F-Measure了
F-Measure是Precision和Recall加权调和平均:
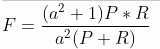
当参数a=1时,就是最常见的F1了:
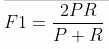
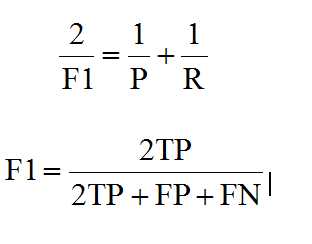
F1综合了P和R的结果,当F1较高时则比较说明实验方法比较理想。将Precision和Recall的上述公式带入会发现,当F1值小时,True Positive相对增加,而false相对减少,即Precision和Recall都相对增加,即F1对Precision和Recall都进行了加权。
准确率(Accuracy),精确率(Precision),召回率(Recall)和F1-Measure。
标签:border false ble nbsp img http idt pos 一个
原文地址:https://www.cnblogs.com/oliyoung/p/APRF.html