标签:inf 存在 com 常见 style 改变 tms 覆盖 状态
文献名:Large-scale Identification of N-linked Intact Glycopeptides in Human Serum using HILIC Enrichment and Spectral Library Search
(利用HILIC富集和谱图库搜索对人血清中N-连接完整糖肽的大规模鉴定)
期刊名:Molecular & Cellular Proteomics??
发表时间:(2020年4月)
IF:4.8
单位:
物种:人血清
技术:N糖基化
一、 概述:
由于血清中的蛋白质丰度在在较大的动态变化范围以及缺少完整的血清N-多糖数据库和蛋白质组,通过LC-MS/MS对N-连接完整糖肽的大规模鉴定仍然具有挑战性。针对这一问题,本文提出了谱图库检索方法,利用正反库和特异性motif的FDR控制在人血清鉴定N-连接完整糖肽,以及在蛋白提取过程中通过乙腈沉淀蛋白分离血清中低丰度和高丰度的蛋白的方法。提取后的蛋白经过酶解后,用HILIC进行N-连接完整糖肽的富集,富集后的糖肽一部分用PNGase F处理产生N-连接去糖肽,然后用LC-MS/MS分析N-连接完整糖肽和去糖肽。从N-连接去糖肽的数据集中,764个N-糖蛋白,1699个N-连接糖基化位点和3328个唯一的N-连接脱糖肽被鉴定。N-连接糖基化motif的4种类型的(NXS / T / C / V, X≠P)被用来识别N-连接去糖肽。这些N-连接去糖肽被用来构建N-连接去糖肽库和鉴定N-连接完整糖肽。另外本文建立了含有739个N-糖基的数据库并用于N-连接完整糖肽的谱图库搜索。在1%FDR的条件下,本研究在人血清中共鉴定出526个N-连接糖蛋白、1036个N-连接糖基化位点、22,677个N-连接完整糖肽和738个糖型,这是利用LC-MS/MS在N-连接完整糖肽水平最深入的血清N-糖蛋白组的研究。
二、 研究背景:
人血清中的N-连接糖蛋白用于疾病诊断已有数十年,如前列腺特异性抗原(PSA)和癌症抗原125 (CA-125)等,而准确鉴定N-连接完整的糖肽是监测其在不同疾病状态下变化的前提。目前LC-MS/MS已广泛应用于N-连接糖肽的识别和定量,DDA模式用于数据采集。在DDA模式下,根据在MS1上母离子的相对强度来选择MS/MS采集,为了分离母离子,其m/z值作为一个分离窗口的中心点,该窗口中的所有离子同时被碎片化。因此,仪器记录的母离子包含母离子在其洗脱区间中信号最强的同位素峰。然而,N-连接完整糖肽的单同位素峰很少是其同位素簇中信号最强的峰,与其他同位素峰相比,不太可能被选为DDA采集的母离子m/z。因此,在糖蛋白组学研究中,需要一种能够准确识别N-连接完整糖肽单同位素峰的软件工具。另外,糖基的结合会增加肽段的亲水性,通过RPLC进行分离糖基化肽段的难度大于非糖基化肽段。因而N-连接完整糖肽在LC中共洗脱以及母离子在MS中共碎裂在利用LC-MS分析糖肽中很常见。这可能会改变每个母离子的同位素分布,使其难以确定各自的单同位素峰或母离子m/z。能够准确测定MS1谱图中N-连接完整糖肽母离子m/z的软件工具仍在开发中。为了提高母离子的准确性,在最近的研究中增加了母离子选择的校正步骤。该研究中利用谱图库搜索策略的软件GPQuest对人细胞裂解液中的N-连接完整糖肽进行识别。不同于对母离子m/z 进行校正,另一个软件pParse的是精确地找到前体m/z,并基于机器学习进一步分离共洗脱肽。该软件嵌入到pGlyco 2.0中,并通过数据库搜索成功应用于小鼠组织N-连接完整的糖肽识别。这两项研究都在生物样本中对N-连接完整糖肽进行了深入的识别,尽管他们运用的识别策略不同。与细胞和组织裂解物的蛋白质组不同,人血清蛋白质组具有更广泛的动态变化范围,因此深入鉴定人血清中N-连接完整糖肽是一个巨大的挑战。
三、 实验设计:
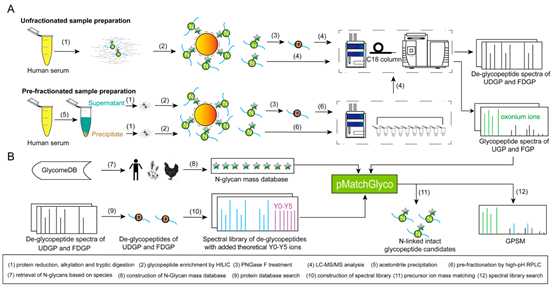
Fig1.人血浆中N连接完整糖肽鉴定的实验策略
四、研究成果:
1.N-连接去糖肽的鉴定
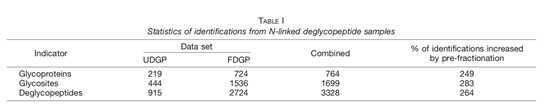
通过pFind v2.8.8 对FDGP和UDGP两组数据进行数据库搜索,在1% FDR条件下,UDGP和FDGP数据组中分别鉴定到915和2724个N-连接脱糖肽对应444和1536个N-连接糖蛋白位点来自于219和724个N-连接糖蛋白(表1)。ACN沉淀与高pH值RP-LC分组分相结合,使N-连接糖蛋白、糖基化位点和糖肽的数量分别增加了249%、283%和264%。该结果表明,分离低丰度和高丰度的蛋白质分离联合N-连接去糖肽分组可显著增加血清N-糖蛋白组的深度。
表1. 样本中N-连接去糖肽的鉴定统计
2. 通过pMatchGlycol和2个N-糖基数据库对N-连接完整糖肽的鉴定
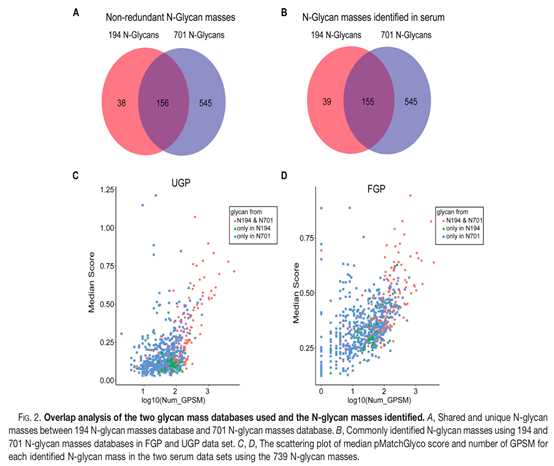
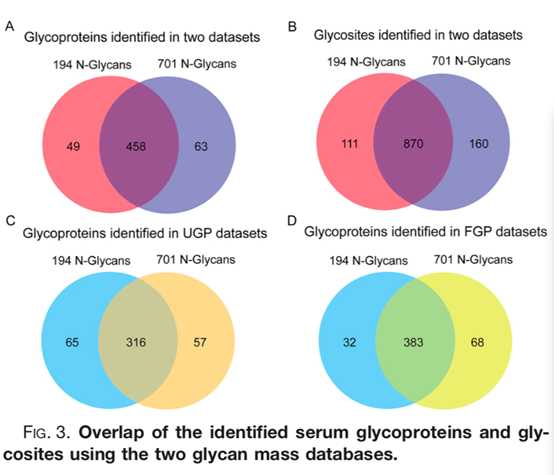
通过pMatchGlyco建立相对完整的人特异性N-糖基数据库对N-糖蛋白质组学的鉴定是非常重要的一步。该研究选择了2种糖基质量数据库,一个为来源于GlycomeDB在去除同分异构体糖基结构的冗余含有194个N-糖基,另外一个来源于GlycomeDB在人和未知物种中的701个N-糖基注释,两者共有156个非修饰N-糖基(图2A)。通过1%FDR过滤和每个糖肽对应的GPSM数目,利用701N-糖基质量的数据库,1030个N-连接糖基化位点和22,194个N-连接完整糖肽来源于521个N-连接糖蛋白在UGP和FGP中被鉴定到(表2)。相比之下,在使用194个N-糖基质量数据库时,981个N-连接糖基化位点和13874个N-连接完整糖肽来源于507个N-连接糖蛋白被鉴定到。在FGP和UGP两组数据中,通过194和701这2个不同数量糖基质量数据库进行搜索,155个N-糖基在两个数据库中共同被鉴定到(图2B)。与其他N-糖基质量相比,这155个N-糖基质量显示出更高的pMatchGlyco评分中指和更多的GPSMs(图2C和2D)。在糖蛋白和糖基化位点水平上,分别有80.4%和76.2%的重复鉴定(图3)。通过比较发现,构建的N-连接去糖肽库覆盖了大部分血清N-连接糖基化位点。与使用194个N-糖基质量数据库相比,使用701个N-糖基质量数据库时,N-连接完整的糖肽增加了8320个,这表明在GlycomeDB数据库中,人N-糖基的数量被低估了。需要一个完整的人N-糖基组成来促进人血清N-连接糖蛋白质组的深入研究。


3.鉴定到的N-糖基质量的验证
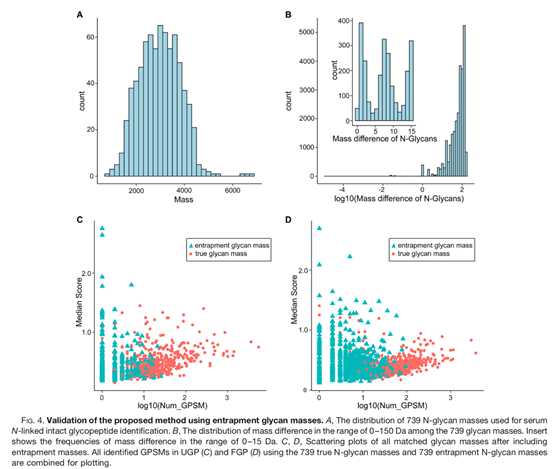
用于血清N-连接完整糖肽鉴定的739个N-糖基质量接近正态分布(图4A)。739个糖基在0-150 Da范围内的不同质量分布如图4B。PSMs的数目和打分鉴定可信度的重要指标。为了评估N-糖基质量鉴定的可信度,对所有匹配的糖基使用GPSM数目的分布图和相应的中位数pMatchGlycop打分。利用739真实的N-糖基质量和739 entrapment N-糖基质量,将所有在UGP(图4C)和FGP(图4D)中识别的GPSMs进行联合散射绘图。结果显示,在entrapment N-糖基质量中鉴定到的与较少的GPSMs和较低的pMatchGlyco中值相对应。
4.使用糖蛋白标准品进行验证
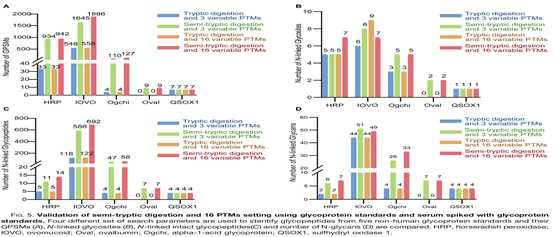
本文用了商业化糖蛋白标准品(HRP、卵清蛋白和血清转铁蛋白)以及将这些蛋白掺入血清来验证鉴定的策略。通过设置不同的搜库参数,发现半胰蛋白酶消化和16个PTMs可使这些蛋白获得最多的GPSMs(图5A-D)。
5.位点特异性糖型
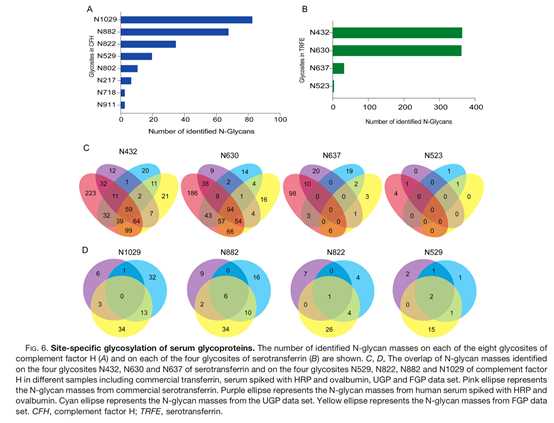
在不同的N-糖基化位点,N-糖基的数目也不同(图6A)。经鉴定,血清转铁蛋白有4个N-连接糖基,分别为N432、N630、N637和N523(图6B)。在商业化转铁蛋白、血清中加入糖蛋白以及UGP和FGP数据集中,转铁蛋白在这些糖基化位点的糖基数目也不相同(图6C)。补体因子H的N529、N822、N882和N1029上的N-糖基数量在血浆添加糖蛋白,UGP和FGP数据集中也存在差异(图6D)。
五、文章亮点:
每个N-糖基组成的准确鉴定对血浆糖蛋白组的位点特异性糖型的功能研究是必不可少的。本文提出了一个完整的操作流程,来增加血清N糖蛋白组的深度。首先,通过ACN沉淀将血清蛋白分为低丰度和高丰度蛋白,随后在胰蛋白酶消化后,用HILIC柱富集糖肽。第二,使用PNGase F将部分富集的N-连接糖肽转变位N-连接去糖肽,并通过高ph RPLC进一步分组分后进行LC-MS/MS检测,利用pFind 2.8.8检索蛋白序列数据库进行鉴定。另外在数据分析中本文通过多个N-糖基数据库进行搜索并用多个商业化的糖蛋白掺入血浆进行验证。
阅读人:陈凌云
标签:inf 存在 com 常见 style 改变 tms 覆盖 状态
原文地址:https://www.cnblogs.com/ilifeiscience/p/12837809.html