数据科学概论
一、爬虫(Web Scraping)
1.网络爬虫(Web Scraping),又称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者,是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
使用Python可以很方便地编写出爬虫程序,进行互联网信息的自动化检索。
2.理解为一段代码(一个程序)。比如说,当我们要在网上获得一些数据,可以通过搜索引擎来获取,然后将内容和地址存储到本地。通常情况下得到的结果有很多,但需要我们一个一个去点开获取,十分麻烦。此时,我们可以利用爬虫。爬虫先进行页面分析,找到目标链接的为止,然后模拟请求目标链接,获取跳转的新的URL(地址)和网页的标题,循环进行下去,直到数据获取完毕。
3.网络蜘蛛
我们可以将互联网上的每一个网页比喻成蜘蛛网上的点,点与点之间有“蛛丝”联系,每一个网站之间都有或多或少的关联。而我们写的那个程序,就好比网上的那只蜘蛛,可以在蛛网上爬取每一个网站的信息,所以把网络爬虫比喻成蜘蛛更加形象。
例子:百度蜘蛛,它每天会在海量的互联网信息中进行爬取,爬取优质信息并收录,当用户在百度搜索引擎上检索对应关键词时,百度将对关键词进行分析处理,从收录的网页中找出相关网页,按照一定的排名规则进行排序并将结果展现给用户。

4.应用
(1)搜索引擎;
比如360的爬虫叫360Spider,搜狗的爬虫叫Sogouspider,必应的爬虫叫Bingbot。
(2)根据采集的数据,进行数据分析;
比如:从商品的评论中总结出该商品的质量如何、股票趋势等等, 还可以将网络爬虫应用于舆情监测与分析、目标客户数据的收集等
(3)做一些小程序、网站;比如:抢票、比价、微信的小程序
(4)丰富资源;
借鉴其他网站的优质内容来丰富自己网站
5.总结
简单来讲,爬虫就是一个探测机器,模拟人的行为去各个网站获取数据。爬虫的出现,可以在一定程度上代替手工访问网页,所以,原先我们需要人工去访问互联网信息的操作,现在都可以用爬虫自动化实现,这样可以更高效率地利用好互联网中的有效信息。
二、后羿采集器
自学“后羿数据采集”官网的“流程图模式”4个教学视频,拟定一个数据采集需求,用“后羿数据采集”软件的流程图模式实现目标。
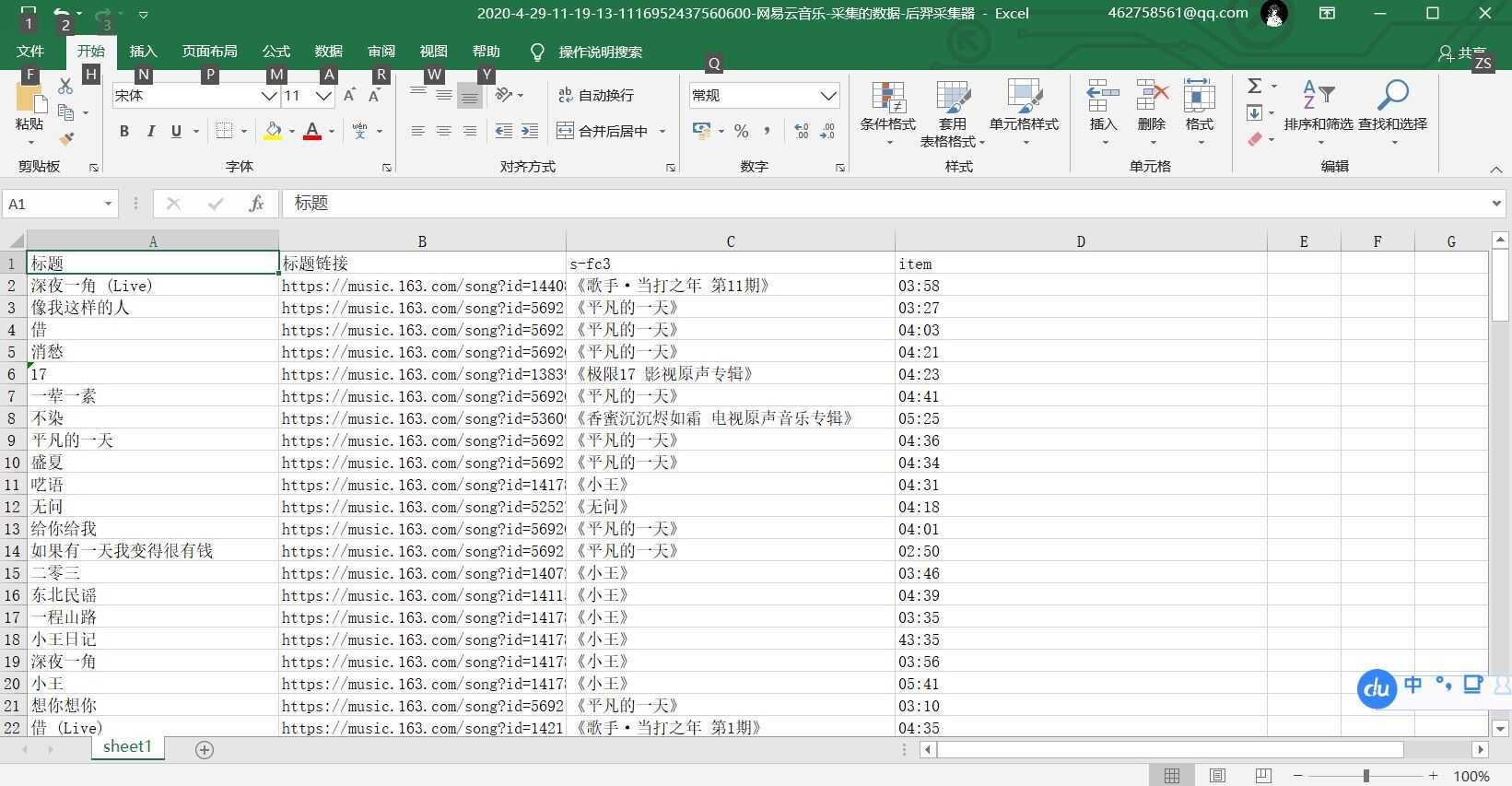
此次练习我打算收集歌手毛不易唱了哪些歌
1.流程图
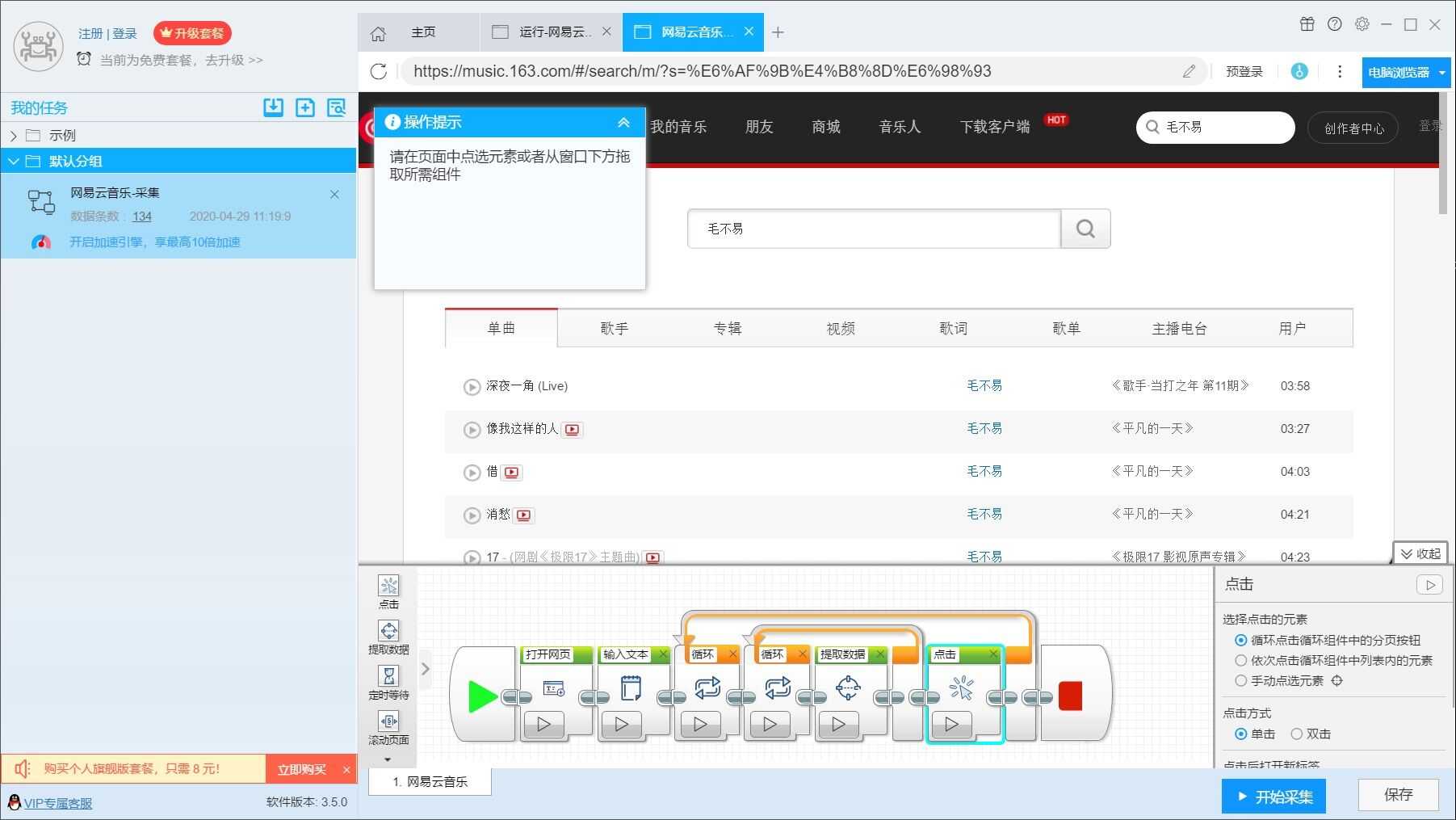
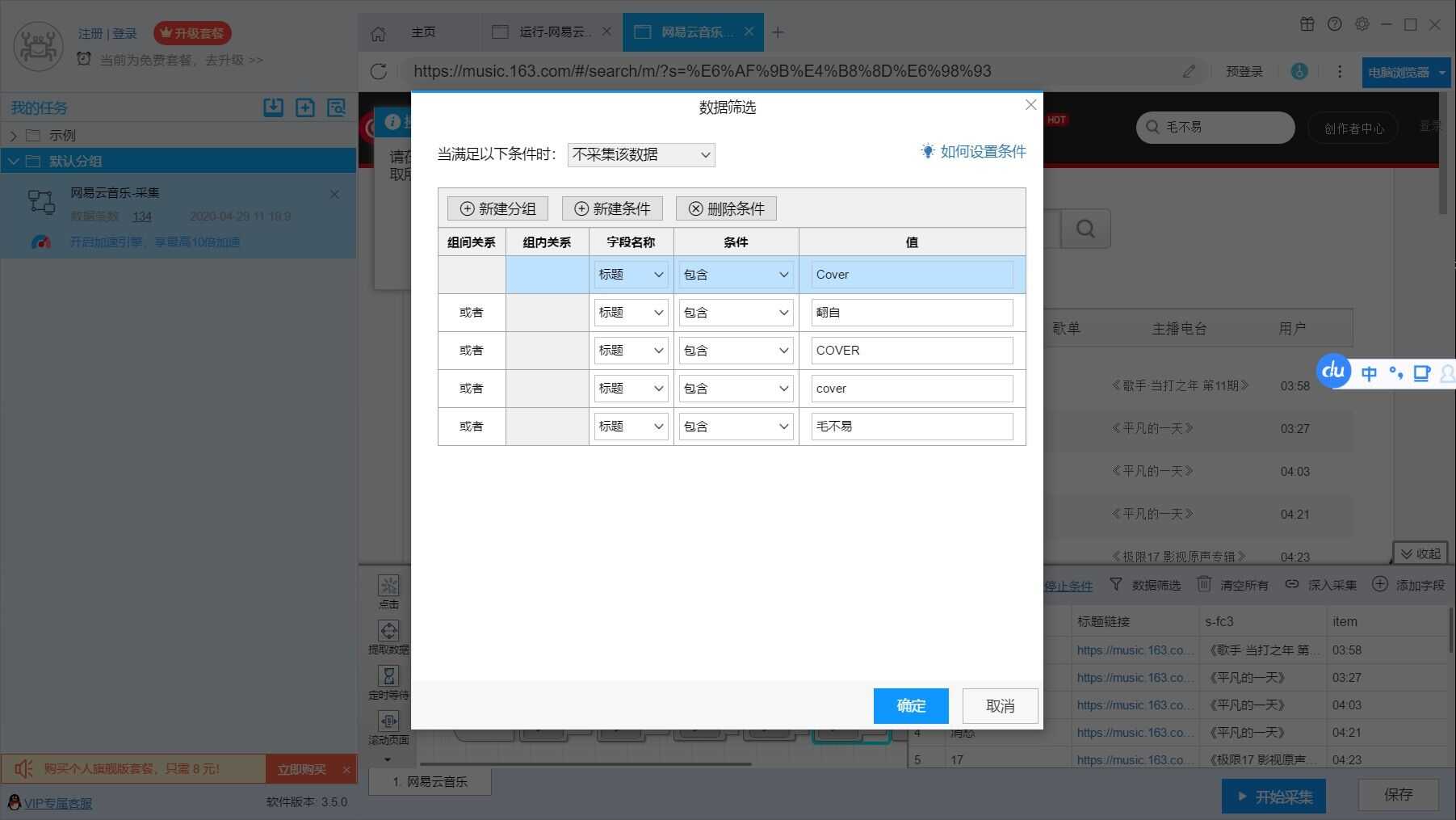
2.在提取数据中,排除一些不需要的元素,例如某些网络歌手等翻唱毛不易的歌。
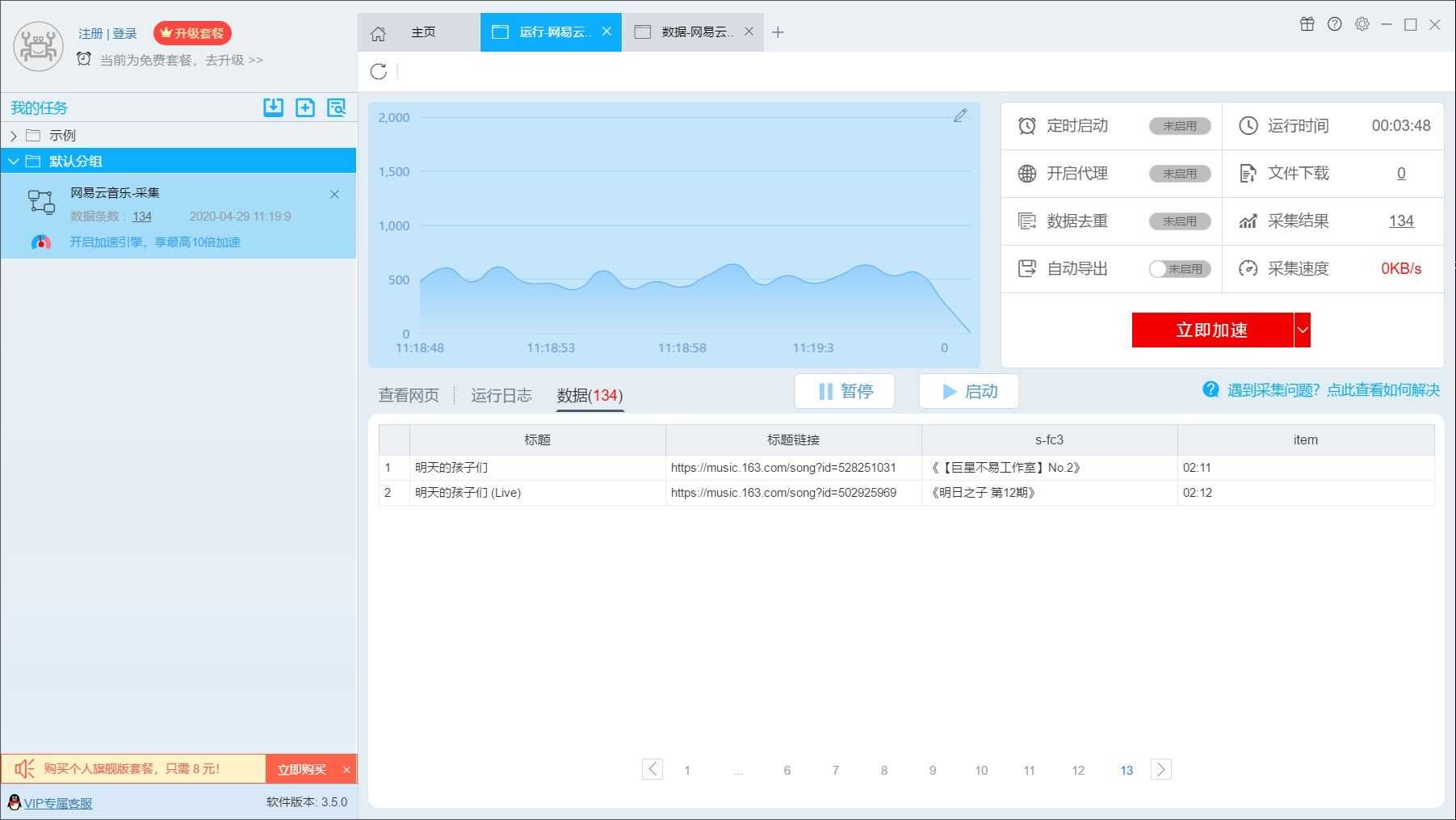
3.采集过程
4.结果
导出为Excel表格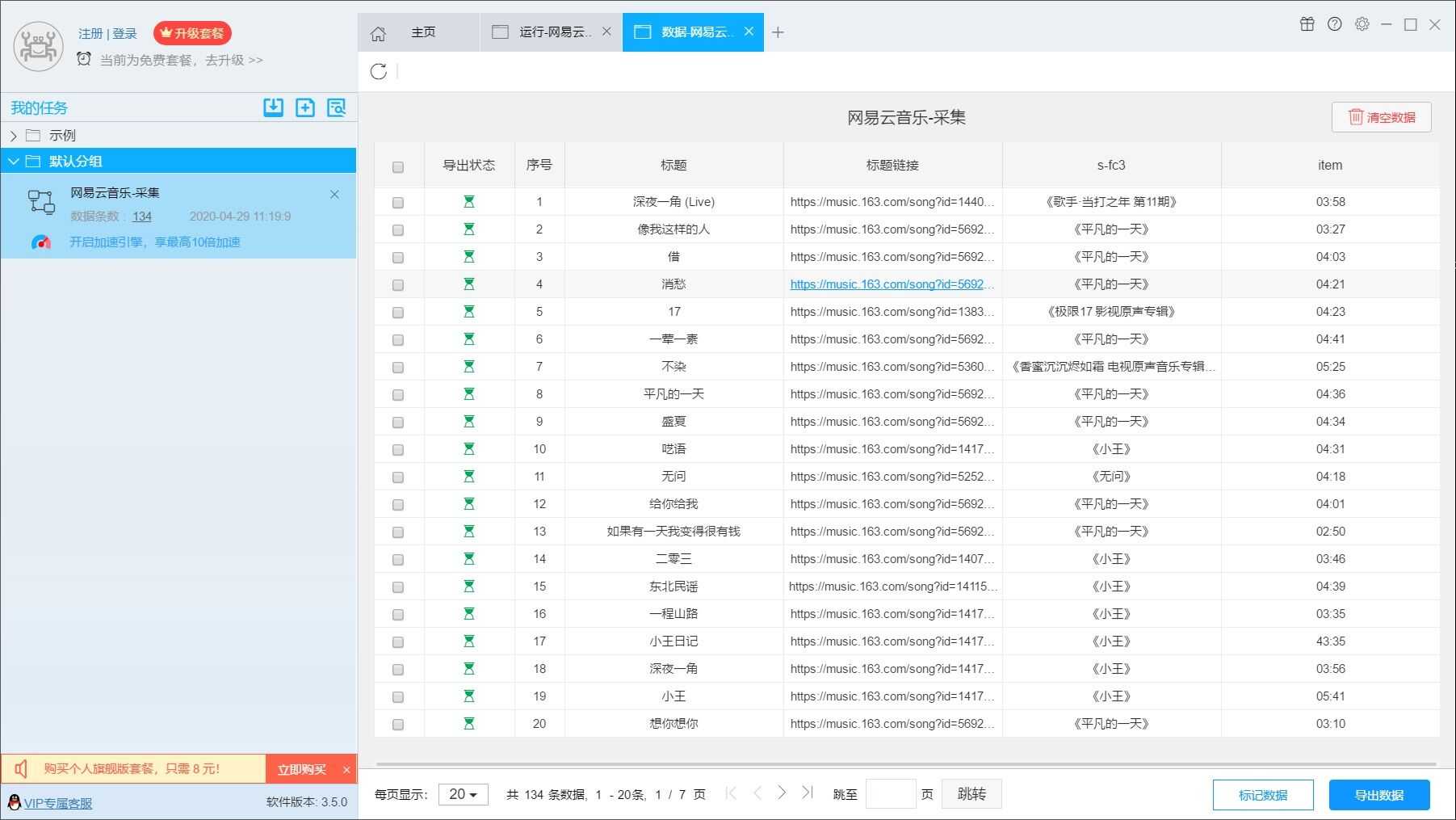
原文地址:https://www.cnblogs.com/kuibaone/p/12838813.html