标签:排名 地方 class 网页 优秀 读取 地图 htm bsp
数据分析在现在大数据时代里,已经成为了不可或缺的一部分。以下介绍对《世界计算机科学技术专业排名前五的大学在顶尖期刊论文数》的简单的数据分析
(数据来源:最好大学网)
要先获得数据有两种方式:1.是直接从网站上下载下来,保存为一种文件,对文件进行读取分析,2.是使用爬虫在网络上爬取数据。在这里我使用的是第二种。

引入爬虫和可视化的第三方库

获取近三年的数据的URL,建立两个空列表,分别存储大学名称和所占比例,cols为确定可视化的颜色,后面会用到!
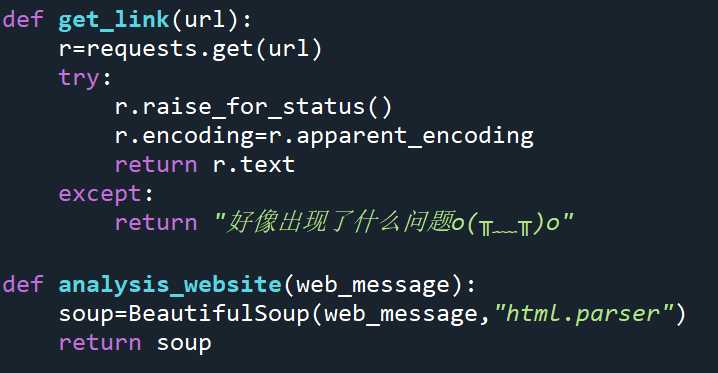
建立好爬虫的框架,这里不多解释,都做过爬虫大作业!
检查网页的元素

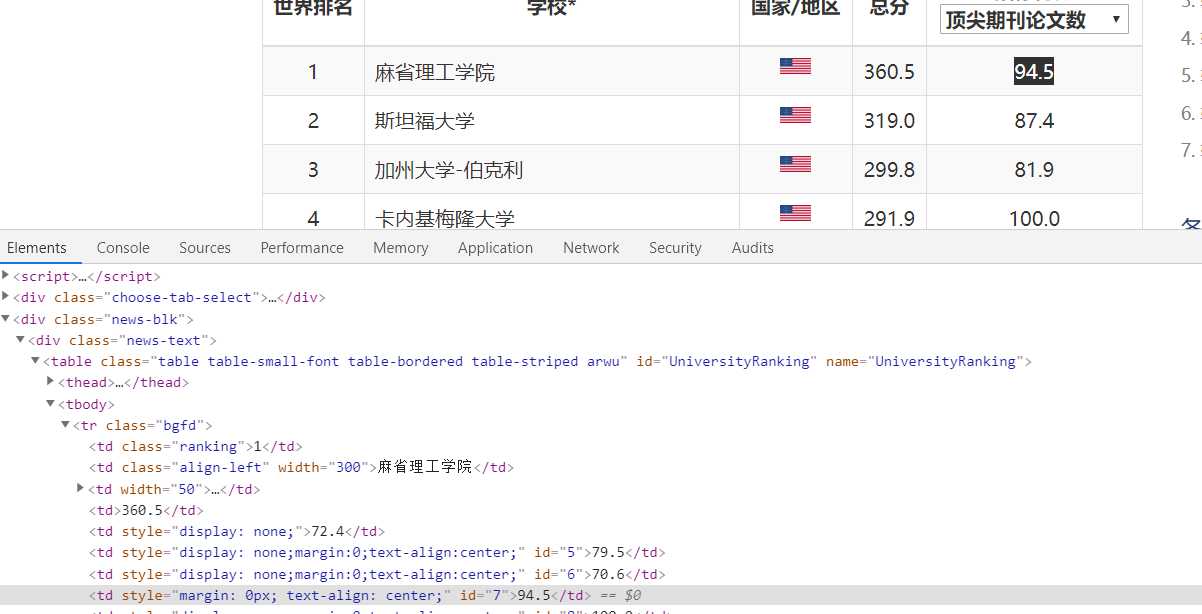
找到其标签的特殊点:class和style、id
对网页的元素进行提取:
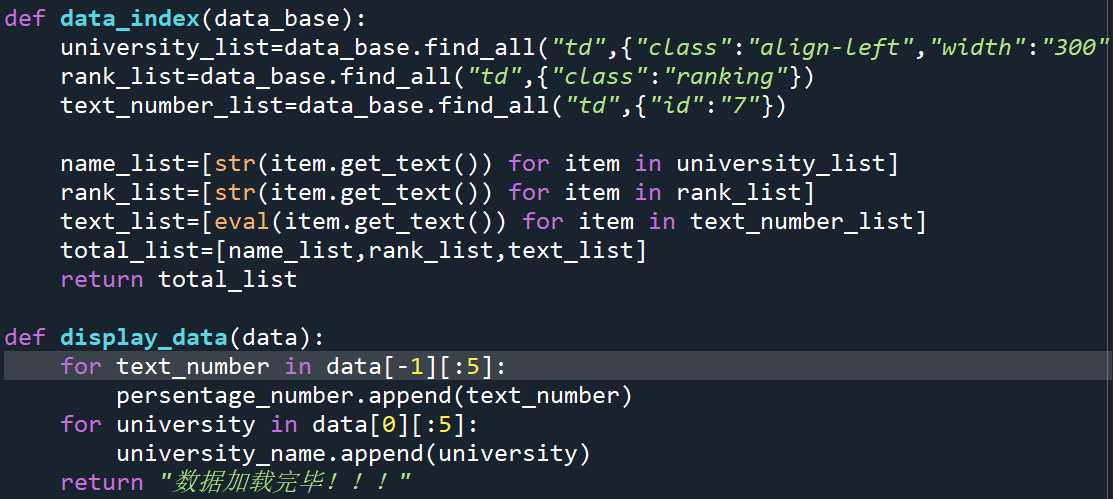
将数据存储到分别建立的两个空列表中(只需要提取前5个)
各个部分已经编写完毕,下面编写主函数
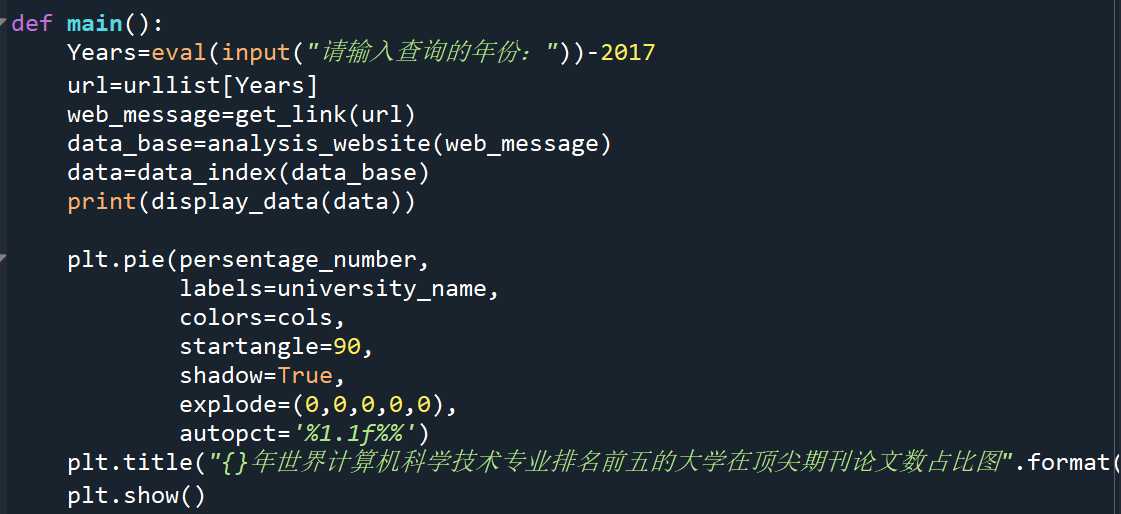
我采用数据可视化的方法是绘制饼状图
startangle=90的意思是从90度的地方开始画第一条线
shadow=True的意思是保留阴影
explode的意思是控制某一块“饼”是否弹出,这里我不弹出,弹出来不太好看
autopct的意思是建立化成百分数
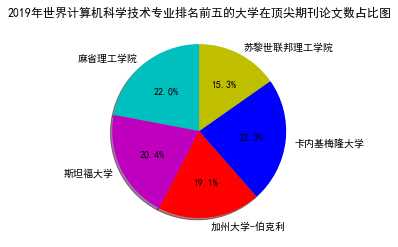
最后成果是(以2019年为例):
反思:
1.在完成这个大作业的时候,最难的部分在于寻找数据,找到了很多统计网站上面的数据,上面很多的数据并不是直接用HTML或者是CSS直接写在网页上的,有很多是直接已经可视化好了的,很不方便提取(也可能是自己水平不够),只好选择了一个简单一点的网站进行爬取和分析。
2.这个分别分析了年份、大学排名和发表的论文数。
3.在这个统计过程中我只统计了前五名大学的统计数据,可是这样是否可以反映出什么情况还有待商榷
还有哪些提高:
还可以形成如同地图一样的图表,并且各个国家的优秀大学数量(可惜我不会,流下没有技术的泪水o(╥﹏╥)o)
标签:排名 地方 class 网页 优秀 读取 地图 htm bsp
原文地址:https://www.cnblogs.com/AhugeCat/p/12840064.html