标签:穷举 端到端 应该 数值范围 链式 工作 错误 做了 中间
一.相关知识
1.背景:从一颗受精卵成长为一个复杂的多细胞生物,神经系统在生物的成长中起着主导作用,神经系统分为中枢神经系统和周围神经系统两大部分主要组成。其中中枢系统主要分布在脑和脊髓中,分布在脑部的神经系统主要起传递、储存和加工信息,产生各种心理活动,支配与控制生物行为的作用。我们把人的这种特性拿出来放到计算机中,也就是让计算机像人脑一样能较精确地处理信息,人脑中的神经系统变成计算机中的人工神经网络,生物神经系统的基本组成单位--神经细胞,对应人工神经网络中的神经元。生物神经系统的主要功能是通过经验能对外界的信息作出正确的回应,比如一个人小时候不会用筷子,但是看得多了,别人教导,他就会用筷子了,我们想让人工神经网络也能通过学习经验(已有的训练数据)来对外界作出正确回应(预测正确未知样本),人类的学习过程相当于神经网络的训练过程。
2.神经网络的特点:(1)对于监督学习来说,在数据量小时,模型的精确度大概率取决于算法的设计,而当数据量足够大时,一般而言,一个规模足够大的神经网络非常擅长计算从样本数据到真实值的精确映射函数,所以比机器学习的算法效果好;(2)对于非结构化数据,神经网络能更好的解释它(结构化数据:每个特征都有明确定义;非结构化数据:比如图像的像素或文本的文字、语音序列之类)(3)神经网络对很多好的算法的兼容性很好,这使得神经网络的计算增快,提高了迭代速度
3.相关应用:真实预测、推荐广告(标准的神经网络)、计算机视觉(图像数据-CNN)、语言识别(序列数据-RNN)、机器翻译(RNN)、无人驾驶(混合)
二.神经网络简介
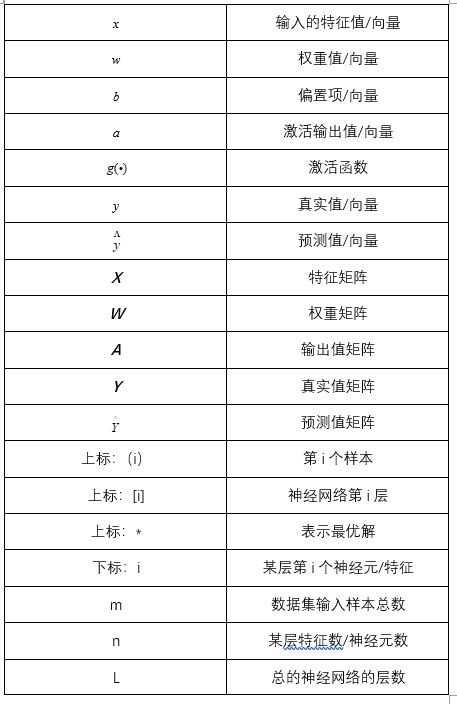
1.符号定义
2.神经网络演变
(1)神经元:神经元是神经网络的基本组成单元,它从前面的神经元处接收信息,处理完信息后将结果传给后面的神经元,是信息的处理单元。传输信息的通道在生物神经网络上为“突触”,在人工神经网络中用赋予权重的连接线来表示。
【1】单输入单输出的单个神经元:接收前输入a,用线性或非线性转换对输入进行处理,得到新的特征a‘并输出。
首先,对于传递过来的某个数据信息a,该神经元在接受信息时,由于信息不可能都是重要的以及传输过程中信息的损耗等问题,我们对输入的信息a作线性变化,保留其中对本层神经元有用的信息z,其次可以对信息作进一步处理,用一个激活函数对其进行非线性变换,使得输出的信息变成对下一层更有意义的信息,比如把苹果这个信息变成水果。
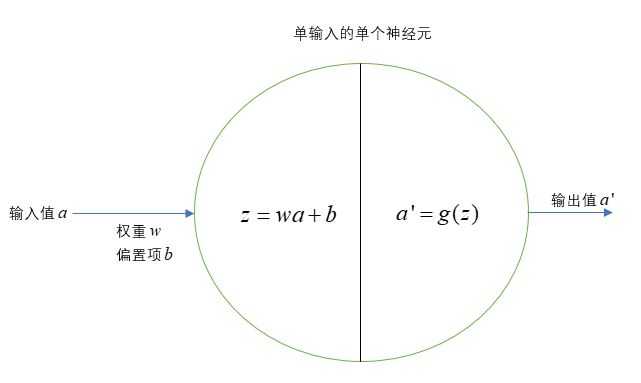
【2】多输入的第l层神经元:一个神经元可以接收其他多个神经元的输入,但只能输出一个信息a,用来表示该神经元。权重向量和输入特征的个数有关,每个输入对应一个权重,他们维度相同
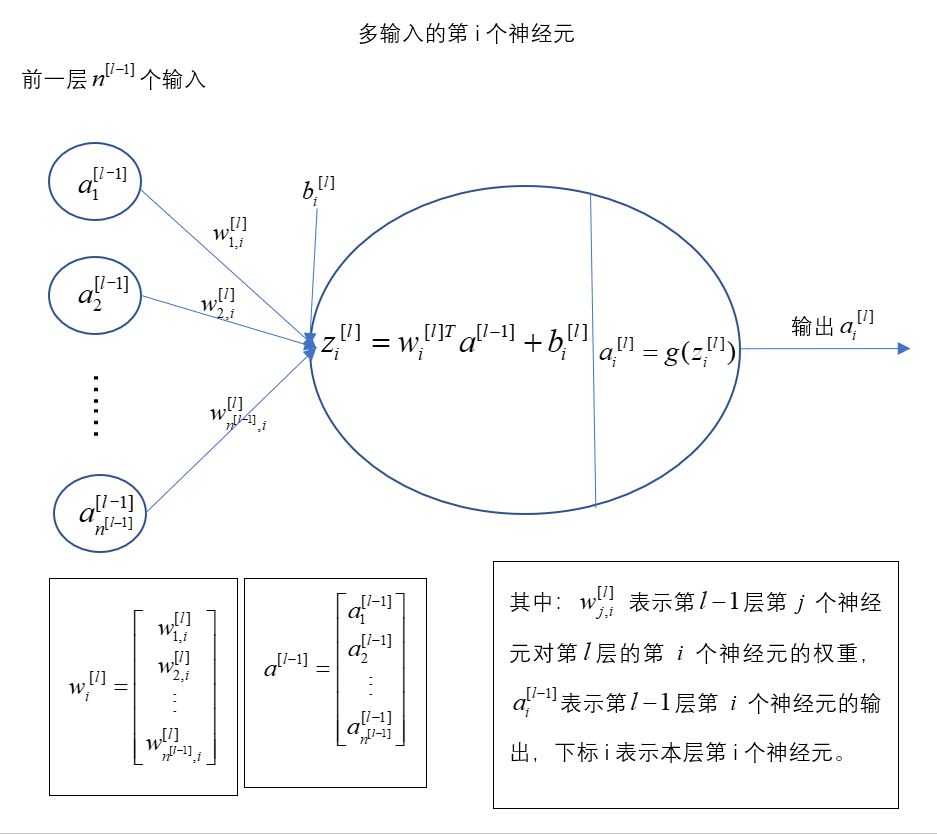
(2)神经层:具有多个神经元的一层,这些神经元有相同或相似的输入和输出
【1】多个神经元的某一层网络:该层中神经元可以有多个,每个神经元可以接收到上层多个神经元的信息,每个神经元输出一个信息,可以被下一层多个神经元接受使用。而且注意,一层的激活函数只有一个,但它对该层所有的神经元都进行激活。
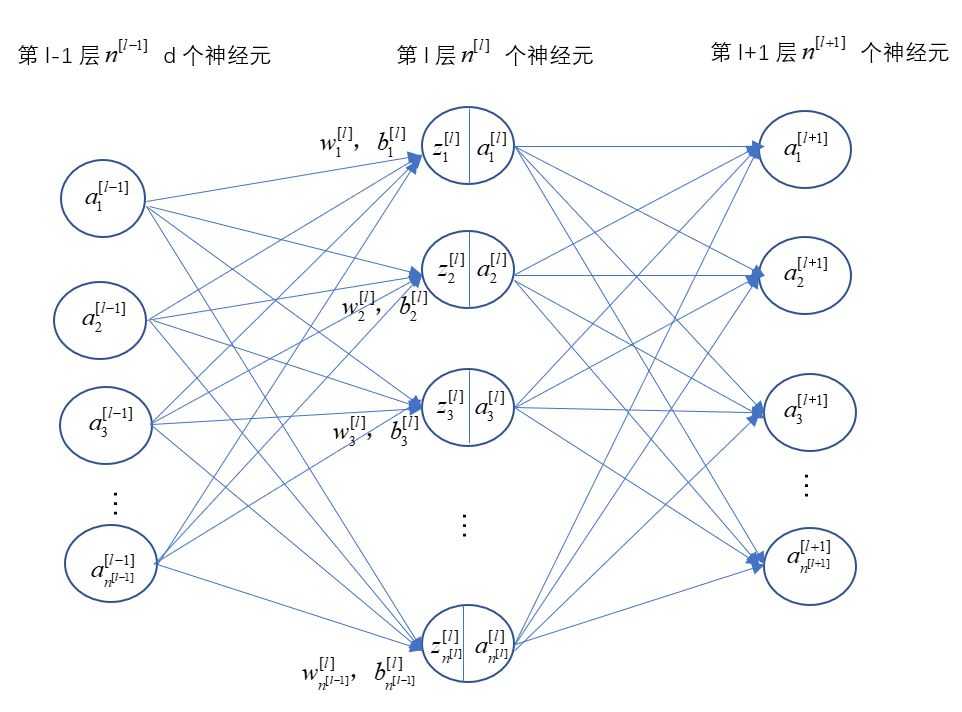

(3)神经网络:由多层组合而成的神经网络,第一层为数据的初始输入层,作第0层--a[0],一般不放入神经网络层数中计算,因此神经网络的层数是从第二层开始一直到最后的输出预测层。输入和输出层中间的被称为隐藏层(因为在训练集中无法看到相关的值,所以被称为隐藏层),每层的神经元数目和一共有多少隐藏层可以自己设置,它们是超参数,每个隐藏层有两个模型参数W和b。
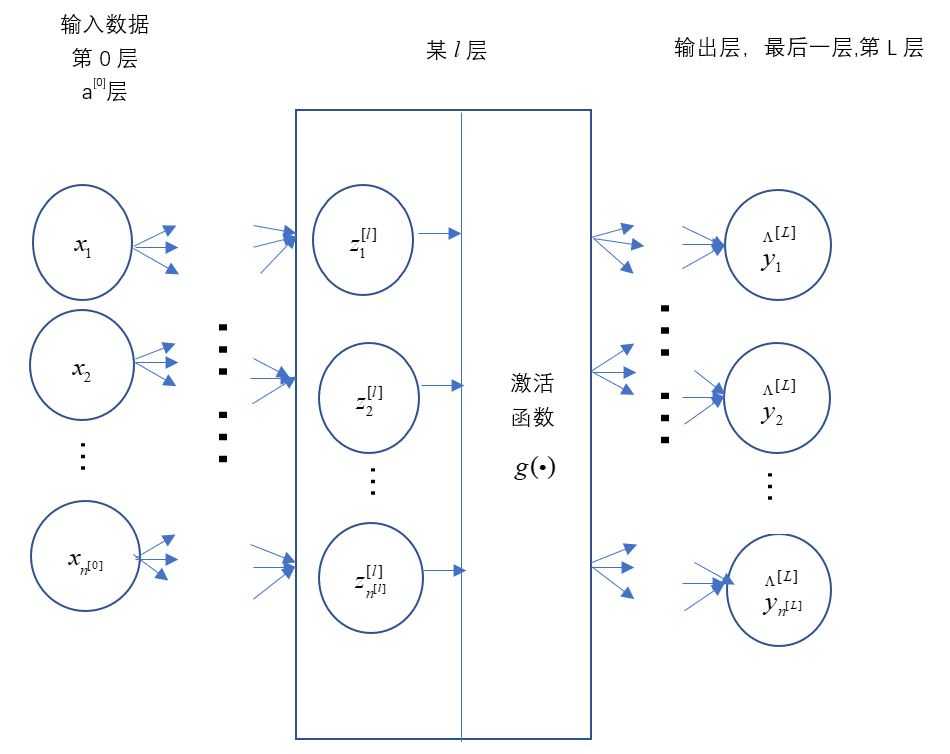
(4)多个样本的神经网络:对于样本,将训练样本横向堆到各列,用矩阵化来表示。由于每个输入的神经元(特征)对应一个权重,所以W*A时,权重矩阵的列数要对应特征矩阵的行数,权重矩阵的行数代表本层有多少神经元,对应输出特征矩阵的行数。输出矩阵的每一列对应一个样本的输出,输出矩阵的每一行对应该层的输出神经元数。
A矩阵每个元素代表第几个样本在该层的第几个神经元(特征)的输出。W(输出维度,输入维度),b(输出维度,样本数)

二.人工神经网络
1.激活函数:进行非线性变换(某个激活函数是对某层所有神经元进行统一的非线性变化,使得原来的线性函数能够变成任意非线性函数,神经网络也就可以确定非线性决策边界,若无激活函数,到最后无论多少层,输出值只是特征的线性组合,就相当于无隐藏层)
(1)sigmod函数:将函数映射到(0,1),主要用于输出层二分类问题,在特征相差比较复杂或是相差不是特别大时效果比较好。
【1】优点:平滑、易于求导。
(2)tanh函数:sigmod平移的函数,映射到(-1,1),有数据中心化的功能,可以用于隐藏层,
【1】优点:比sigmod收敛快,梯度消失更慢,有类似数据中心化的功能,
【2】缺点:和sigmod一样,当值很大或很小时,梯度会变得很小,这会拖累梯度下降
(3)relu函数(修正线性单元):把负值变为0,代表神经元不激活,正值不变,神经元激活,这就相当于减少了神经元,缩小了网络的规模,这是通常的选择。
【1】优点:梯度下降速度快,而且由于右边梯度不会趋于0,无梯度消失问题,削减了一些神经元来提高训练效率高,相当于减弱了过拟合
【2】缺点:当z为负时,梯度为0,有可能导致很多神经元消失,使得模型无法学习到有效特征
(4)leaky relu:当z为负时,梯度是缓慢的,而不是0,是relu的改进
2.前向和反向传播:
(1)前向传播:从输入到输出计算出预测值
(2)误差反向传播:利用导数链式法则和梯度下降法对误差函数反向更新参数
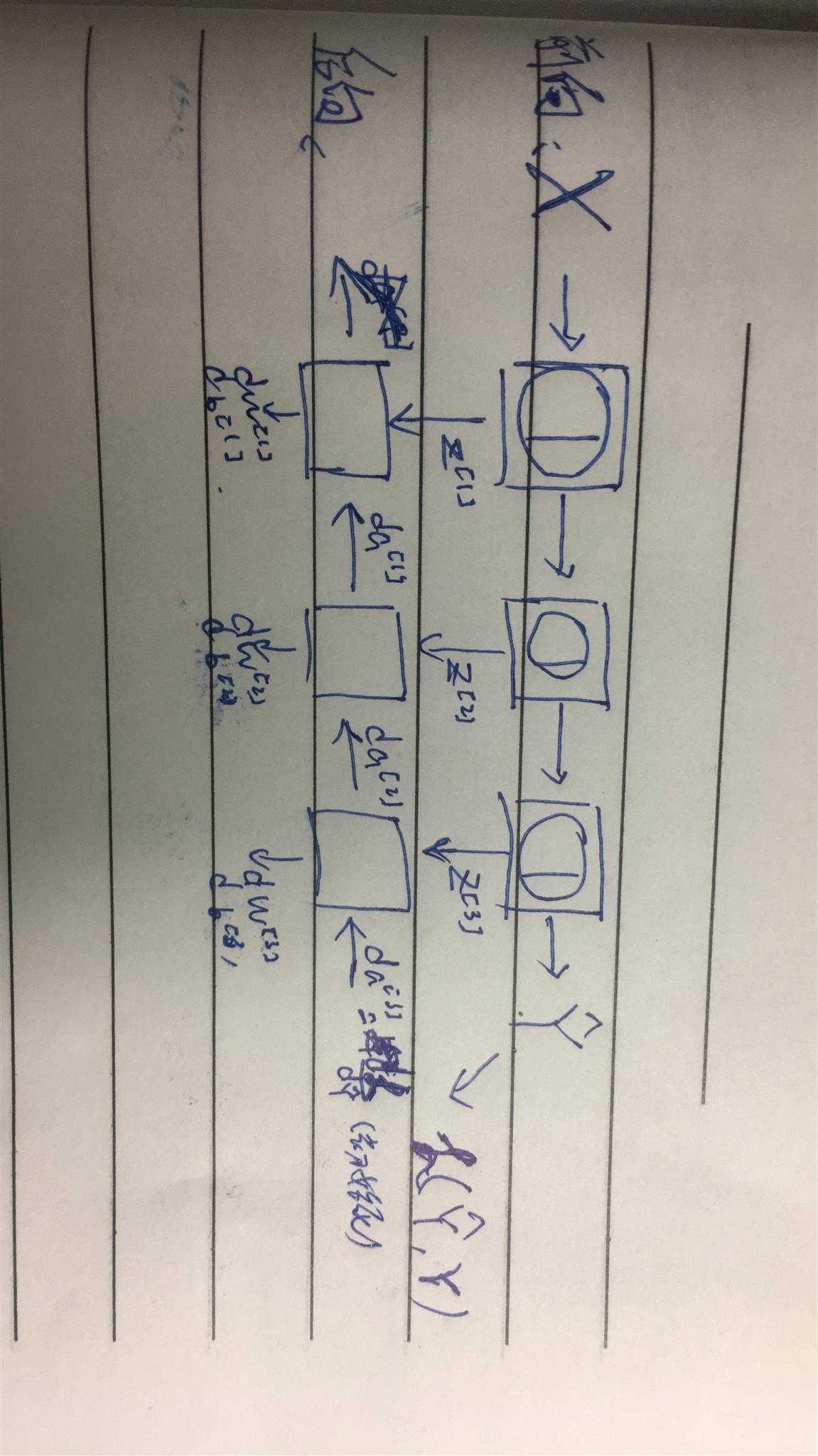
【1】解释:当模型初始建立后,通过前向传播得到数据集对于这个模型的评估,与真实值的差距为误差,我们的目标是最小化误差,因此要对模型参数进行调整使模型效果更好。又:求最优解时最常用的方法时一般用梯度下降法,同时前向传播实质上是参数的链式变量,因此我们从后往前,对于关于参数的链式变量求梯度,最后得到目标函数对于参数的梯度,最后用梯度下降法更新参数
【2】对某一层的反向传播:da,dw,db,dz是误差对a,w,b,z的求偏导

【3】神经网络的反向传播:多层的链式求导,注意初始化:对误差在预测值项求导,而且为了减少计算量,还需对所有已完成计算的元素进行复用
3.参数抉择
(1)模型参数:模型参数若相同,则代表对应的神经元一样
【1】W:权重,每层初始化不可为0,一般小随机数初始化--高斯分布随机变量:np.random.random((n,n))*0.01(把权重初始化为较小的值,若权重很大,当计算激活函数时,比如sigmod和tanh,则预测的值很大或很小,此时可能落在激活函数平缓的部分,梯度很小,学习就变慢了;也不能过小,可能会生成零梯度网络)
【2】b:偏置项,初始化可为0,np.zero((2,1))
(2)超参数:基于经验调整超参数,超参数是对模型参数有影响的,以下较重要性排序
【1】学习率:指在优化算法中更新参数的步长,太大或太小都不好,我们一般使用对数标尺搜素该参数(比如【0.001,0.01.,0.1,1】在这上面取对数变为【-4-0】,然后随机均匀取值),看损失函数随时间的变化曲线判断学习速率是否合适
【2】动量系数β:0.9-0.999,β接近1时比较敏感。β涉及到指数的加权均值,0.999到0.995 这表示第1000值的均值到第2000个值的均值,
【3】每批大小(2的次方数,[16,128],敏感),隐藏层的神经元数(过少会导致欠拟合,过多会导致过拟合,一般采取方法解决过拟合--正则化等)
【4】层数,学习率衰减系数(随时间减少学习率,本质在于在收敛前期可以承受较大步伐,在后期,步伐变小,在最优解附近收敛),迭代次数,激活函数,adm (0.9,0.09,10^-8)...
(3)调参方法
【1】网格搜索-参数少时--通过穷举法列出不同的参数组合,确定性能最优的结构
【2】随机法--参数多时。因为各个参数对模型的影响是不同的,有的大,有的小 ,随机法能看出各个参数的影响力。从具有特定分布的参数空间中抽取出一定数量的候选组合
【【1】】先随机取值,再比较效果,得出效果较好的参数取值范围,再放大这个范围,在这个范围中再次随机取值,这样不断缩小参数的取值范围-----------随机取值,精确搜索,由粗糙到精确
(4)其他:
【1】每隔一段时间要重新训练模型和更新参数
【2】设定不同的超参数,同时训练几个模型来比较选择其中最好的超参数
4.神经网络的改进
(1)F范数正则化:在损失函数中加入正则项,避免参数过大,降低模型复杂度,解决过拟合问题
【1】重新定义损失函数

【2】影响:若λ变大,则权重衰减程度变大,则权重变小,降低了隐藏单元的影响,同时线性值z变小,此时若激活函数为tanh或sigmod,则表示激活函数接近线性函数,相当于没有对z进行非线性变换,此时模型无论多深,都接近为一个线性网络,模型变简单,拟合能力降低。因此其和激活函数也有关。
(2)dropout正则化:随机使部分神经元失活,从而精简神经网络,降低模型复杂度
【1】正向随机失活:在正向传播中,遍历每一层,设置神经网络中每个节点失活的概率,用随机数来和其比较,从而消除一些节点,减小网络规模
【2】反向随机失活:对于某一层,设定激活阈值keep_prob(0-1之间),它表示保留某个神经元的概率,则1-keep_prob表示消除某个神经元的概率,设置一个随机向量d(其中有keep_prob%的值为1,其余为0)(np.random.rand(a.shape[0],a.shape[1)<keep_prob),把a变成a*d(a=np.multiply(a,d)),则代表神经元中平均有(1-keep_prob)%的点变为0,即消除节点,而且为了不影响下一层的z值,我们对a进行修补让它的期望不变,即a=a/keep_prob,以此确保即使在测试阶段不执行dropout来调整数值范围,激活函数的预期结果也不会发生变化
【3】特点:由于随机性,所有节点都可能被删除,所以输出值不依赖于任何一个特征,所以不会把赌注放在一个节点上,不愿意给任何一个输入加上太大的权重,因此是对所有的输入都加了一点权重,这将产生收缩权重的平方范数的效果,类似F正则化效果。而且不能保证某两个隐含节点每次都同时出现,这样就减少了神经元之间的依赖性。
【4】优点:更适用于不同的输入范围。不同层的keep_prob可以不同(若某层神经元多,拟合能力强,则该层设置较小的keep_prob),也可以对输入层用,限定输入特征的量。只用于过拟合时。
【5】缺点:为了使用交叉验证,要搜索更多的超参数,而且代价函数J不再被明确定义,因为每次迭代都消除了一些节点,所以我们一般训练阶段用交叉验证的方法使用Dropout取均值作为评估结果,测试阶段把Dropout屏蔽
(3)其他降低过拟合的正则化方法:数据扩增、中断迭代(w从小到大选中间)(缺点:不同独立地处理优化函数和过拟合两个问题)、翻转剪裁图片增加数据集、
(4)加快训练速度:特征归一化
【1】归一化训练集特征:0均值化,标准化(方差为1)
【2】注意要用与训练集上相同的均值和方差来归一化测试集,而不是在训练集和测试集上分别估计均值和方差,因为我们希望训练集和测试集都是通过同一均值和方差定义的相同数据转换。
【3】为什么要用归一化:特征取值范围的不同导致对应模型参数的范围和比例将不同,这导致代价函数更加陡峭,若用梯度下降法,所需的时间会更多,下降曲折,还可能导致梯度爆炸。因此归一化特征将使代价函数更对称均衡,我们可以使用较大步长。
【4】特征数据做归一化只是做了映射,并没有改变特征数据与标签数据之间的关系,标签数据是结果做规一化,不会改变结果,而且标签值不会直接影响到参数的梯度下降,因此特征数据最好做归一化,而标签数据不用。
(5)应对梯度消失和梯度爆炸:深度网络可以视为是一个复合的非线性多元函数,若网络很深,正向传播时,若每个|w|>1,则最后的预测值会成指数级增长,若每个|w|<1,则预测值会最终很小,这同样适用于反向梯度计算,
【1】梯度消失:我们一般初始化|w|<1,若每个激活函数的梯度都小于1,比如sigmod,则计算到输入层的梯度时,梯度会小到接近0,使得权重和偏差参数无法被更新,导致神经网络无法被优化,训练永远不会收敛到良好的解决方案。
【2】梯度爆炸:第l-1层的梯度是由第l层的梯度和|w|共同决定的,若初始化|w|很大,而第l层梯度很小,其中|w|占主导,两者之积大于1,则最后到输入层的梯度会很大
【3】解决:减小权重wi=每次神经元特征数量分之一 *随机正太分布变量、选择其他激活函数relu、梯度剪切、正则、批量规范化、预训练和微调
【4】梯度检验用于检验前向和反向的正确性:调试时,用双边极限逼近的方法检验梯度,若检验出错误,则要查找每个值,而且梯度检验不要和dropout一起使用
(6)batch normalization(批量规范化bn):对每一层的z规范化到某种正态分布(自设定均值和方差),同minibatch的方法,使得神经网络对超参数的选择更稳定

5.softmax回归:对所有输出作类别的概率映射,选择最大的对应的类别作为最后的预测输出,一般和交叉熵损失一起使用。另外hardmax就是在输出向量中取最大的那个概率作为1,其余为0,这样看来softmax就比较平和
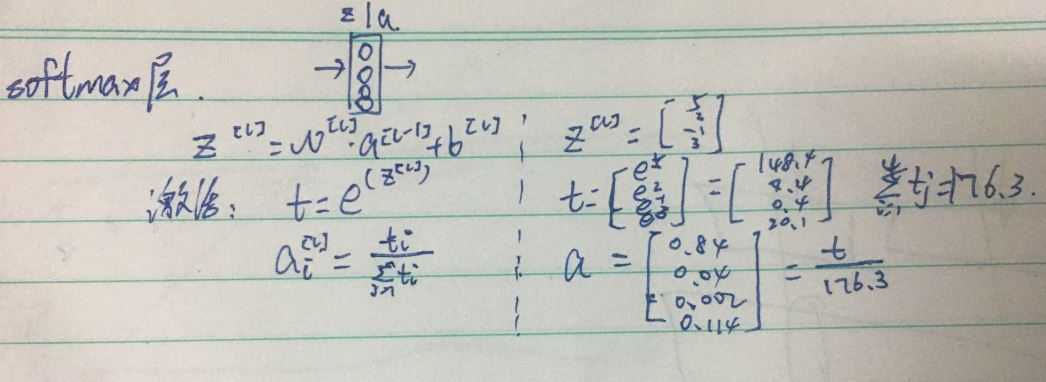
6.整个流程
(1) 开发过拟合网络:添加更多层、添加更多神经元、增加训练次数
(2)网络训练:初始化随机权重、前向计算、代价函数、反向传播算法计算偏导值、梯度检测、最优化算法最小化代价(全局最小)
(3)抑制过拟合:dropout、正则化(控制网络规模)、图像增强
(4)调节超参数:学习率、神经元数,层数,训练轮次
(5)进一步改进:调整正则化参数(优)、训练更多样本(效果差),添加更多特征(效果差)、减少特征(防止过拟合)
7.注意事项
(1)能向量化尽量向量化,少用for循环,加快计算速度。而且代码最好要注意检查声明维度(assert(a.shape == (5,1)) 声明变量维度)或者重设维度(reshape)
(2)多层不一定比单层好,但相对来说增加层比增加神经元数要更好,增加层会大大提高网络的拟合能力,单纯地增加神经元个数对于网络性能的提高并不明显,单层的神经元个数不能太小,会造成信息瓶颈,造成模型欠拟合
三.其他
1.迁移学习:从一个任务中学得的模型可以应用到另一个独立的任务中,常用于图像识别(图像的改变)
(1)预训练和微调:预训练就是指预先训练的一个模型或者指预先训练模型得到原任务较好参数;微调就是指将预训练过的模型参数作为新任务的初始参数,在训练进行调整。
(2)迁移学习的本质是把学习到一般特性的模型应用到特定问题上,从而加快学习速度
(3)具体:任务A和任务B是有重合的知识的,若任务A已经训练完一个模型,则可以把这个模型的部分作为任务B的一部分,实现知识的迁移,
(4)注意:【1】只有两个任务有同样或相似输入时,迁移学习才有意义,【2】当B没有很多数据,而A有比B多的数据时,我们可以借用迁移学习,这时候它的作用意义才更大,即当你需要解决一个问题,但你的训练数据很少,所以你需要找到一个数据很多的相关或相似问题来预先学习,并将知识迁移到这个新问题上
2.多任务学习:让单个模型同时做几件事
(1)与softmax的不同:softmax将单个标签分配给单个样本,而多任务学习中一个样本可以有很多不同的标签,输出的是一个向量而不是一个值,这个这个向量包含多个问题的解,可以处理无标记的数据
(2)适用于同时训练任务--相似且数据量对等的任务:【1】若训练的一组任务可以共用低层次特征,【2】如果每个任务的数据量很接近,【3】训练一个足够大的神经网络来同时做好所有的工作
3.端到端的深度学习:输入到输出,数据量大时比较好
(1)优点:让数据说话,减少人类的主观影响,手工组件少
(2)缺点:需要大量训练数据,排出了可能有用的人工步骤
标签:穷举 端到端 应该 数值范围 链式 工作 错误 做了 中间
原文地址:https://www.cnblogs.com/yu-liang/p/12797336.html