标签:ict referer ade company cookies image format head bsp
第一步:分析网页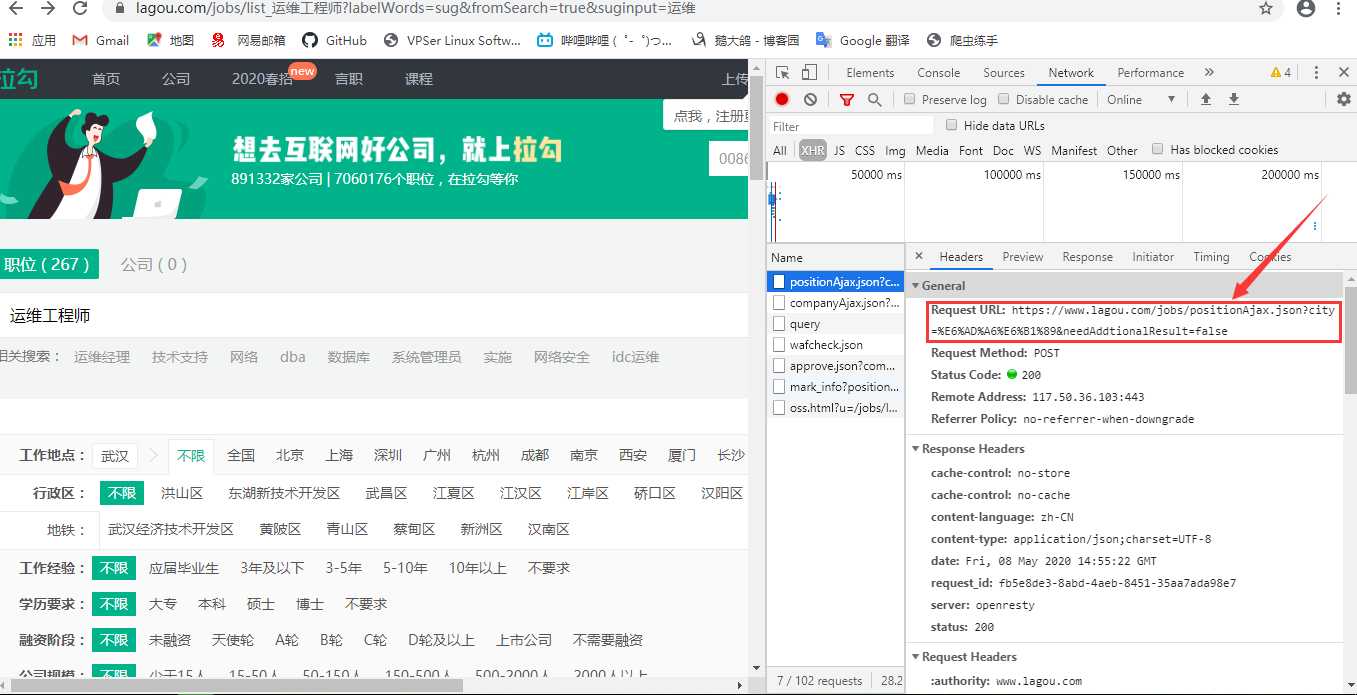
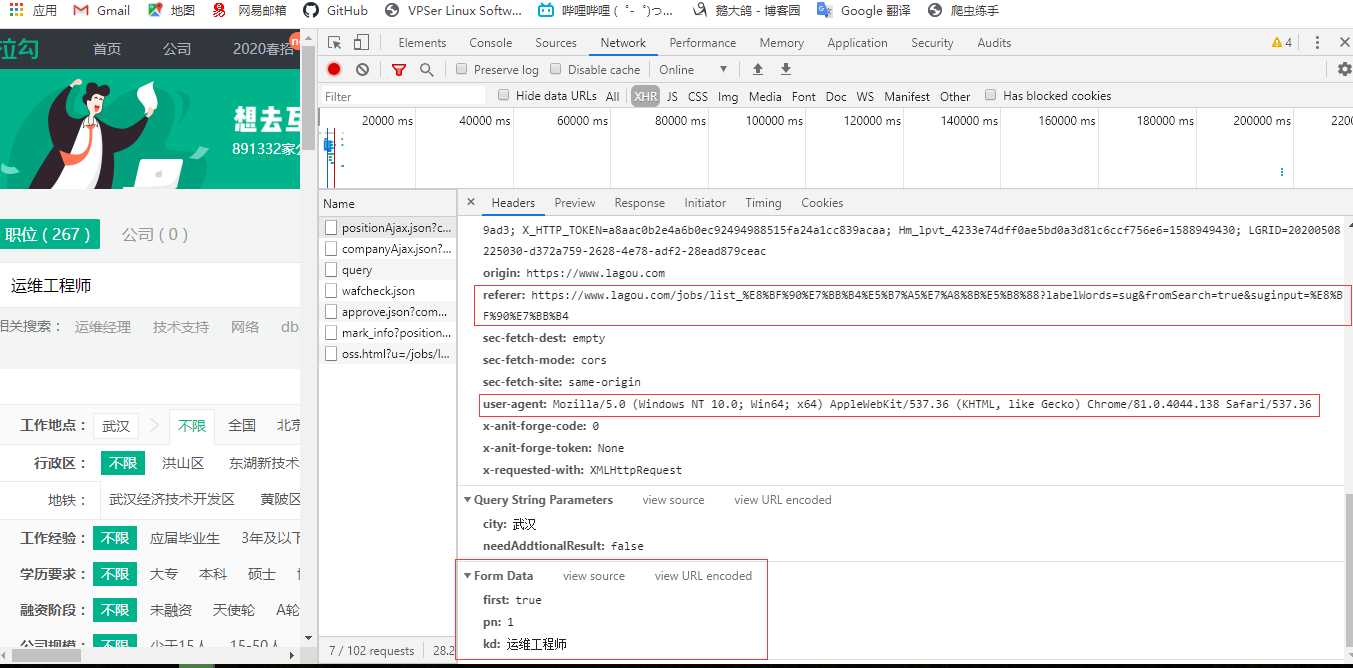
直接上代码
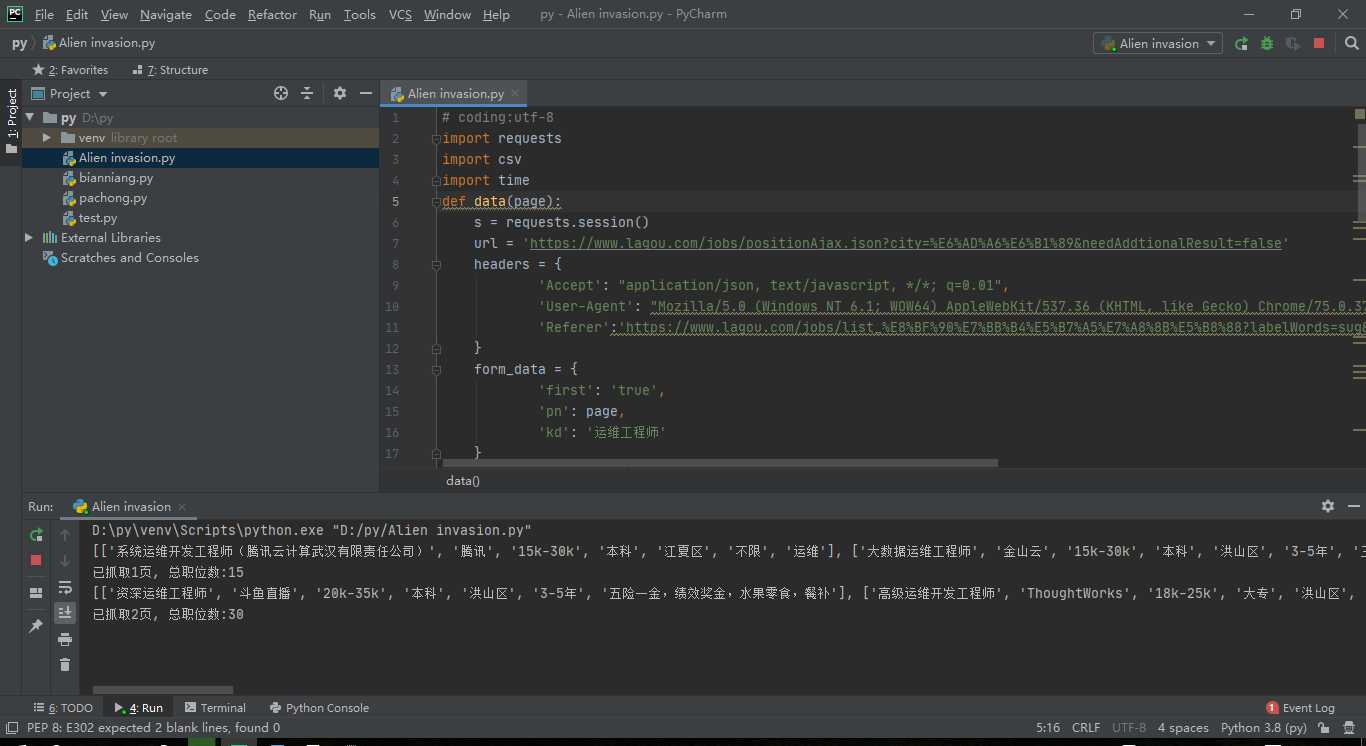
1 import requests 2 import csv 3 import time 4 def data(page): 5 s = requests.session() 6 url = ‘https://www.lagou.com/jobs/positionAjax.json?city=%E6%AD%A6%E6%B1%89&needAddtionalResult=false‘ 7 headers = { 8 ‘Accept‘: "application/json, text/javascript, */*; q=0.01", 9 ‘User-Agent‘: "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36", 10 ‘Referer‘:‘https://www.lagou.com/jobs/list_%E8%BF%90%E7%BB%B4%E5%B7%A5%E7%A8%8B%E5%B8%88?labelWords=sug&fromSearch=true&suginput=%E8%BF%90%E7%BB%B4‘ 11 } 12 form_data = { 13 ‘first‘: ‘true‘, 14 ‘pn‘: page, 15 ‘kd‘: ‘运维工程师‘ 16 } 17 url_list = ‘https://www.lagou.com/jobs/list_%E8%BD%AF%E4%BB%B6%E6%B5%8B%E8%AF%95%E5%B7%A5%E7%A8%8B%E5%B8%88?city=%E4%B8%8A%E6%B5%B7&cl=false&fromSearch=true&labelWords=&suginput=‘ 18 s.get(url_list, headers=headers,timeout=3) 19 cookie = s.cookies 20 response = s.post(url, data=form_data, headers=headers,cookies=cookie,timeout=3) 21 response.raise_for_status() 22 response.encoding = response.apparent_encoding 23 job_json = response.json() 24 job_list = job_json[‘content‘][‘positionResult‘][‘result‘] 25 csv_data = [] 26 for i in job_list: 27 job_info = [] 28 job_info.append(i[‘positionName‘]) # 职位 29 job_info.append(i[‘companyShortName‘]) # 公司 30 job_info.append(i[‘salary‘]) # 薪资 31 job_info.append(i[‘education‘]) # 学历 32 job_info.append(i[‘district‘]) # 位置 33 job_info.append(i[‘workYear‘]) # 工作经验要求 34 job_info.append(i[‘positionAdvantage‘]) # 福利待遇 35 csv_data.append(job_info) 36 print(csv_data) 37 csvfile = open(‘运维职业.csv‘, ‘a+‘,encoding=‘utf-8-sig‘,newline=‘‘) 38 writer = csv.writer(csvfile) 39 writer.writerows(csv_data) 40 csvfile.close() 41 return csv_data 42 if __name__ == ‘__main__‘: 43 a = [(‘职位‘,‘公司‘,‘薪资‘,‘学历‘,‘位置‘,‘工作经验要求‘,‘福利待遇‘)] 44 csvfile = open(‘运维职业.csv‘, ‘a+‘,encoding=‘utf-8-sig‘,newline=‘‘) 45 writer = csv.writer(csvfile) 46 writer.writerows(a) 47 csvfile.close() 48 all_company = [] 49 for page_num in range(1, 100): 50 result = data(page=page_num) 51 all_company += result 52 print(‘已抓取{}页, 总职位数:{}‘.format(page_num, len(all_company))) 53 time.sleep(10) #速度不要太快,免得被bang
基本结构为:
请求网页获取cookies值,携带这网页的cookies再去请求需要爬取的url
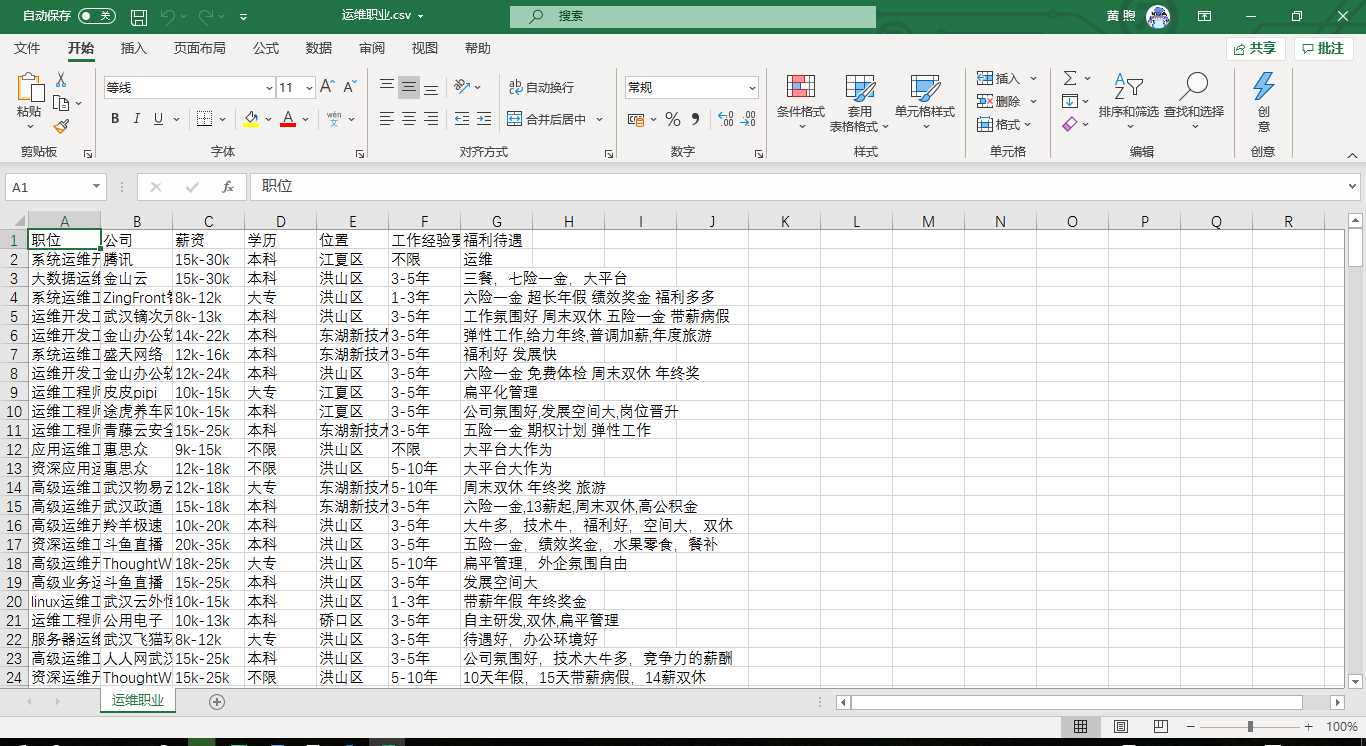
拿到数据后写入csv文件
模拟分页内容,爬取全部数据
部分内容转载自——https://www.cnblogs.com/qican/p/11283954.html
标签:ict referer ade company cookies image format head bsp
原文地址:https://www.cnblogs.com/hxlinux/p/12853770.html