标签:统一 img src google 进制 英文 问题 爬虫 去重
?就是非贪婪模式。^ : ^b 以b开头的字符串
.???: 匹配任意字符串
*??: 任意长度(次数),≥0
() : 要取出的信息就用括号括起来
? : 非贪婪模式(从左边开始匹配),尽可能少的匹配所搜索的字符串 ‘.*?(b.*?b).*‘----从左至右第一个b和的二个b之间的内容(包含b)
+:+ 前面的字符至少出现一次
{} : 前面字符出现的次数
+:?出现至少一次
{2}?:限定字符出现次数,2次
{2,5}:?出现2-5次之间,后者需大于前者
|?:或”的关系,例如:“z|food”能匹配“z”或“food”(此处请谨慎)。“[z|f]ood”则匹配“zood”或“food”或"zood"。
():提取字符串里的值,(1)“第一个字符串值”
[]:满足中括号内任意字符就行,进入后皆无特殊含义[.*]、区间[0-9]、具体数值[123]、不等于1[^1]
\s:为空格 \S非空格
\w:大小写字、数字以及下划线,等于:[A-Za-z0-9_]
\W:匹配下划线在内的任何单词字符,[^A-Za-z0-9_]
\w:和上一个相反
[\u4E00-\u9FA5]:匹配所有中文
\d?:匹配数字
\D:匹配所有非数字
①贪婪模式
line = "boooobaaaooobbbbby123"
regex_str = ".*?(b.*b).*" #贪婪模式,从右边选择b,.*(一个或者没有),再到左边最前面一个b。
match_obj = re.match(regex_str,line)
if match_obj:
print(match_obj.group(1))#group(1)表示匹配括号里面的第一组,所以输出:boooobaaaooobbbbb
②非贪婪模式
line = "boooobaaaooobbbbby123"
regex_str = ".*?(b.*?b).*" #非贪婪模式,从左边选择b,.*(一个或者没有),再到后面第一个b
match_obj = re.match(regex_str,line)
if match_obj:
print(match_obj.group(1))#group(1)表示匹配括号里面的第一组,所以输出:boooob
③年月日正则案例
line = "XXX出生于2001年6/1"
line = "XXX出生于2001-6-1"
line = "XXX出生于2001-06-01"
line = "XXX出生于2001年6月1日"
line = "XXX出生于2001-6-1"
line = "XXX出生于2001-06-01"
line = "XXX出生于2001-06"
regex_str = ".*(\d{4}[年-]\d{1,2}([月 / -]\d{1,2}|[月 / - ]$|$))" #[月日时],满足于具体数字月、日、时就可以
match_obj = re.match(regex_str,line)
if match_obj:
print(match_obj.group(1))
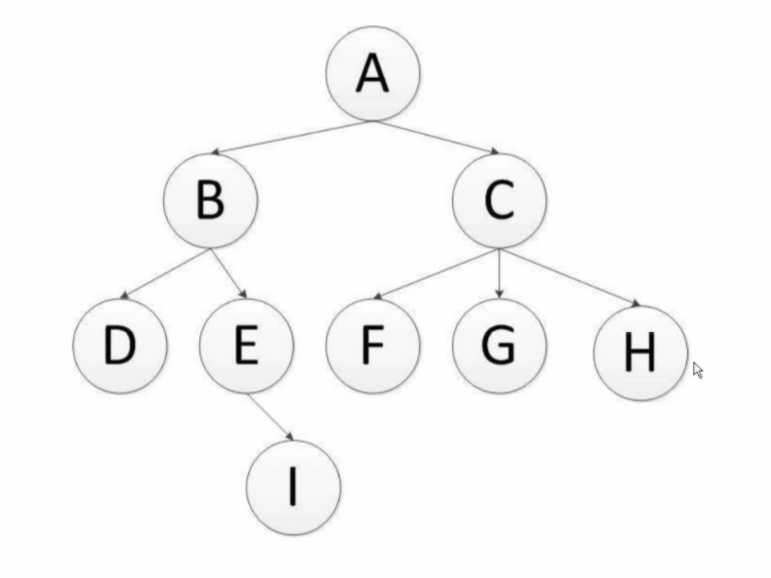
深度优先遍历:对每一个可能的分支路径深入到不能再深入为止,而且每个结点只能访问一次。二叉树的深度优先遍历的非递归的通用做法是采用栈,要特别注意的是,二叉树的深度优先遍历比较特殊,可以细分为先序遍历、中序遍历、后序遍历。具体说明如下:
DFS的Python算法描述:
def depth_tree(tree_node):
"""
# 深度优先过程
:param tree_node:
:return:
"""
if tree_node is not None:
print(tree_node._data)
if tree_node._left is not None:
return depth_tree(tree_node._left)
if tree_node._right is not None:
return depth_tree(tree_node._right)
注:scrapy默认是通过深度优先来实现的。
广度优先遍历:又叫层次遍历,从上往下对每一层依次访问,在每一层中,从左往右(也可以从右往左)访问结点,访问完一层就进入下一层,直到没有结点可以访问为止。广度优先遍历的非递归的通用做法是采用队列。
BFS的算法描述:
def level_queue(root):
"""
# 广度优先过程
:param root:
:return:
"""
if root is None:
return
my_queue = []
node = root
my_queue.append(node)
while my_queue:
node = my_queue.pop(0)
print(node.elem)
if node.lchild is not None:
my_queue.append(node.lchild)
if node.rchild is not None:
my_queue.append(node.rchild)
区别:
通常深度优先搜索法遍历时不全部保留结点,遍历完后的结点从栈中弹出删去,这样,一般在栈中存储的结点数就是二叉树的深度值,因此它占用空间较少。所以,当搜索树的结点较多,用其它方法易产生内存溢出时,深度优先搜索不失为一种有效的求解方法。 但深度优先搜素算法有回溯操作(即有入栈、出栈操作),运行速度慢。
广度优先搜索算法,一般需存储产生的所有结点,占用的存储空间要比深度优先搜索大得多,因此,程序设计中,必须考虑溢出和节省内存空间的问题。但广度优先搜索法一般无回溯操作,即入栈和出栈的操作,所以运行速度比深度优先搜索要快些。
bitmap方法,将访问过的URL通过hash函数映射到某一位。(但是容易发生哈希冲突,,即不同url哈希值相同。)1亿bit = 12.5MB内存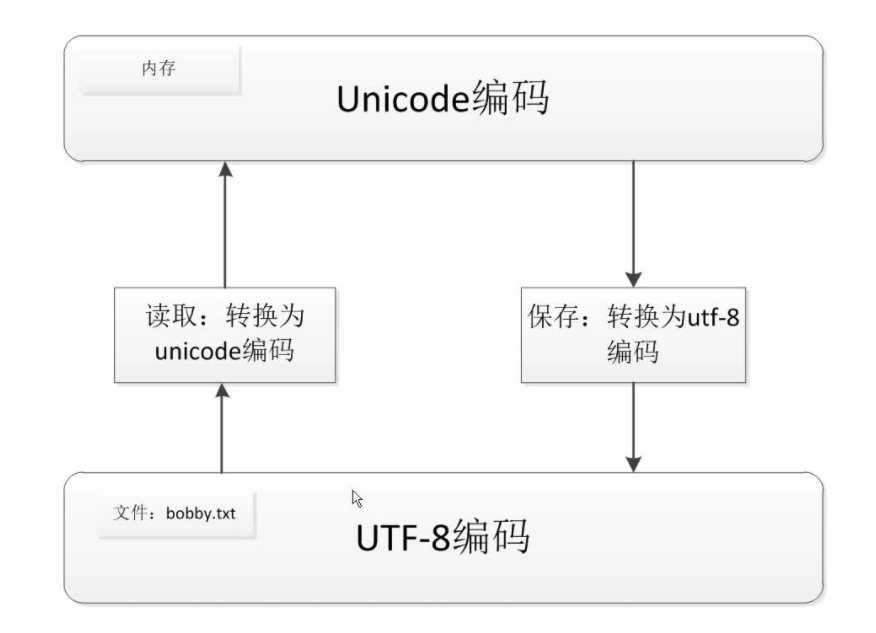
decode 的方法是将bytes类型转换为str类型(解码)encode的方法是将str类型转换为bytes类型(编码)stingc = "我爱python"
print(stingc.encode(‘utf-8‘))#encode的方法是将str类型转换为bytes类型
string = stingc.encode(‘utf-8‘)
print(string.decode(‘utf-8‘))#encode的方法是将str类型转换为bytes类型(编码)
标签:统一 img src google 进制 英文 问题 爬虫 去重
原文地址:https://www.cnblogs.com/shy-kevin/p/12859380.html