标签:drop 代码 编码 dex self 泛化 add 位置 基础
keras允许自定义Layer层, 大大方便了一些复杂操作的实现. 也方便了一些novel结构的复用, 提高搭建模型的效率.
通过继承keras.engine.Layer类, 重写其中的部分方法, 实现层的自定义. 主要需要实现的方法及其意义有:
_ init _(self, **kwargs)
作为类的初始化方法, 一般将需要传入的自定义参数存为对象的属性. 需要注意的有以下几点:
由于继承Layer类, 所以在处理完自定义的参数之后, 仍可能还有参数需要父类处理, 所以需要调用父类的初始化方法, 将kwargs参数传入:
class DecayingDropout(Layer):
def __init__(self, initial_keep_rate=1., decay_interval=10000, decay_rate=0.977,
noise_shape=None, seed=None, **kwargs):
super(DecayingDropout, self).__init__(**kwargs)
对象的self.supports_masking方法的作用是本层中是否涉及到使用mask或对mask矩阵进行计算. mask的作用是屏蔽传入Tensor的部分值, 常常在NLP问题中, 对句子padding之后, 不想让填补的0值对应的位置参与运算而使用. 这个参数默认为False, 如果有使用到, 需要将其值为True:
self.supports_masking = True
build(self, input_shape, **kwargs)
这里是定义权重的地方, 需要注意的有以下几点:
通过self.add_weight方法定义权重, 且需要将权重存为类的属性, 例如:
self.iterations = self.add_weight(name=‘iterations‘, shape=(1,), dtype=K.floatx(),
initializer=‘zeros‘, trainable=False)
其中self.iterations需要在初始化时设置为None, 符合类编程的习惯. self.add_weight方法有若干参数, 常用的即为上面几个.
由于要求build方法必须设置self.built = True, 而这个方法在父类中实现, 因此, 在方法的最后需要调用:
super(DecayingDropout, self).build(input_shape)
call(self, inputs, **kwargs)
这里是编写层的功能逻辑的地方, 传入的第一个参数即输入张量, 即调用_ call _方法传入的张量. 除此之外, 需要注意的点有:
如果需要在计算的过程中使用mask, 则需要传入mask参数:
def call(self, x, mask=None):
if mask is not None:
mask = K.repeat(mask, x.shape[-1])
mask = tf.transpose(mask, [0,2,1])
mask = K.cast(mask, K.floatx())
x = x * mask
return K.sum(x, axis=self.axis) / K.sum(mask, axis=self.axis)
else:
return K.mean(x, axis=self.axis)
如果该层在训练和预测时的行为不一样(如Dropout)函数, 需要传入指定参数training, 即使用布尔值指定调用的环境. 例如在Dropout层的源码中, call方法是这样实现的:
def call(self, inputs, training=None):
if 0. < self.rate < 1.:
noise_shape = self._get_noise_shape(inputs)
def dropped_inputs():
return K.dropout(inputs, self.rate, noise_shape,
seed=self.seed)
return K.in_train_phase(dropped_inputs, inputs,
training=training)
K.in_train_phase()方法就是用来区别在不同环境调用时, 返回的不同值的. 这个函数通过training参数区别调用环境, 如果是训练环境, 则返回第一个参数对应的结果, 预测环境则返回第二个参数对应的结果. 可以传入函数, 返回这个函数对应的返回结果.
除了计算之外, 这个函数也是更新层内参数的地方, 即build方法中增加的参数. 通过self.add_update方法进行更新, 例如:
def call(sekf, x):
self.add_update([K.moving_average_update(self.moving_mean, mean,self.momentum),
K.moving_average_update(self.moving_variance,variance,self.momentum)],
inputs)
或者:
def call(self, inputs, training=None):
self.add_update([K.update_add(self.iterations, [1])], inputs)
可以看到, self.add_update方法传入一个列表, 包含一些列更新的动作. 这些更新的动作需要借助K的一些函数实现, 如K.moving_average_update, K.update_add等等.
另外还可以传入inputs函数, 作为更新的前提条件.
除此之外, 还有一些常常需要重新定义的方法:
get_config(self):
返回层的一些参数. 对于自定义的参数, 需要在此指定返回:
def get_config(self):
config = {‘initial_keep_rate‘: self.initial_keep_rate,
‘decay_interval‘: self.decay_interval,
‘decay_rate‘: self.decay_rate,
‘noise_shape‘: self.noise_shape,
‘seed‘: self.seed}
base_config = super(DecayingDropout, self).get_config()
return dict(list(base_config.items()) + list(config.items()))
compute_output_shape(input_shape):
计算输出shape. input_shape是输入数据的shape.
compute_mask(self, input, input_mask=None):
计算输出的mask, 其中input_mask为输入的mask. 需要注意的有:
如果input_mask为None, 说明上一层没有mask. 可以在本层创建一个新的mask矩阵.
如果以后的层不需要使用mask, 返回None即可, 之后就不存在mask矩阵了
def compute_mask(self, input, input_mask=None):
# need not to pass the mask to next layers
return None
如果经过本层, mask矩阵没有变化, 不用实现该函数, 只需要在初始化时, 指定self.supports_masking = True即可.
Keras编写自定义层--以GroupNormalization为例
在使用 callbacks.ModelCheckpoint() 并进行多 gpu 并行计算时,callbacks 函数会报错:
TypeError: can‘t pickle ...(different text at different situation) objects
这个错误形式其实跟使用多 gpu 训练时保存模型不当造成的错误比较相似:
To save the multi-gpu model, use .save(fname) or .save_weights(fname)
with the template model (the argument you passed to multi_gpu_model),
rather than the model returned by multi_gpu_model.
这个问题在我之前的文章中也有提到:[Keras] 使用 Keras 调用多 GPU,并保存模型
。显然,在使用检查点时,默认还是使用了 paralleled_model.save() ,进而导致错误。为了解决这个问题,我们需要自己定义一个召回函数。
original_model = ...
parallel_model = multi_gpu_model(original_model, gpus=n)
class MyCbk(keras.callbacks.Callback):
def __init__(self, model):
self.model_to_save = model
def on_epoch_end(self, epoch, logs=None):
self.model_to_save.save(‘model_at_epoch_%d.h5‘ % epoch)
cbk = MyCbk(original_model)
parallel_model.fit(..., callbacks=[cbk])
class ParallelModelCheckpoint(ModelCheckpoint):
def __init__(self,model,filepath, monitor=‘val_loss‘, verbose=0,
save_best_only=False, save_weights_only=False,
mode=‘auto‘, period=1):
self.single_model = model
super(ParallelModelCheckpoint,self).__init__(filepath, monitor, verbose,save_best_only, save_weights_only,mode, period)
def set_model(self, model):
super(ParallelModelCheckpoint,self).set_model(self.single_model)
check_point = ParallelModelCheckpoint(single_model ,‘best.hd5‘)
class CustomModelCheckpoint(keras.callbacks.Callback):
def __init__(self, model, path):
self.model = model
self.path = path
self.best_loss = np.inf
def on_epoch_end(self, epoch, logs=None):
val_loss = logs[‘val_loss‘]
if val_loss < self.best_loss:
print("\nValidation loss decreased from {} to {}, saving model".format(self.best_loss, val_loss))
self.model.save_weights(self.path, overwrite=True)
self.best_loss = val_loss
model.fit(X_train, y_train,
batch_size=batch_size*G, epochs=nb_epoch, verbose=0, shuffle=True,
validation_data=(X_valid, y_valid),
callbacks=[CustomModelCheckpoint(model, ‘/path/to/save/model.h5‘)])
keras 的所有层的基类定义在 keras/engine/topology.py 文件中的 Layer 类中。
用到的装饰器:
@property 让类函数能像类变量一样操作@interfaces.legacy_xxx_support 让函数支持 keras 1.x 的 API@classmothod 类函数,属于整个类,类似于 C++/JAVA 中的静态函数。类方法有类变量 cls 传入,从而可以用 cls 做一些相关的处理。子类继承时,调用该类方法时,传入的类变量 cls 是子类,而非父类。既可以在类内部使用 self 访问,也可以通过实例、类名访问。@staticmethod 将外部函数集成到类体中, 既可以在类内部使用 self 访问,也可以通过实例、类名访问。基本上等同于一个全局函数。magic 函数:
__call__ 让类的实例可以像函数一样调用,正是 python 的这种特性让我们可以像这样进行层之间的连接:inputs = Input(shape=(784,))
# 前面的Dense(64, activation=‘relu‘)生成了类Dense的一个实例
# 后面的(input)将调用类Dense的__call__函数
x = Dense(64, activation=‘relu‘)(inputs)
InputSpec: 确定层的 ndim,dtype,shape,每一层都应有一个 input_spec 属性,保存 InputSpec 的实例的 list(每一个输入 tensor 都对应一个)
每层的参数通过这个函数来设定。可以看到它最终调用的是 K.variable 来生成变量,打开 keras/backend/tensorflow_backend.py 可以看到它生成变量的方式:
v = tf.Variable(value, dtype=tf.as_dtype(dtype), name=name)
让人惊讶的是,keras 从居然不是使用 tf.get_variable 的方式生成变量,可见 keras 在设计时就根本没有考虑到变量共享,从之前的经验来看,要用 keras 设计多 GPU 程序是非常棘手的。(要想让 Keras 支持多 GPU 并行,必须从这一步开始修改代码,而这里已经是 keras 非常底层的代码了。)
“tf.get_variable() 会检查当前命名空间下是否存在同样name的变量,可以方便共享变量。而tf.Variable 每次都会新建一个变量。”
call 是最重要的函数,它用于实现层的功能,子类必须实现。
魔法函数 __call__ 会将收到的输入传递给 call 函数,然后调用 call 函数实现具体的功能。
根据 input_shape 计算输出的 shape,子类必须实现。用于自动推断下一层的输入尺寸。
用来创建当前层的 weights,子类必须实现。
get_config 返回一个字典,获取当前层的参数信息。
from_config 使用根据参数生成一个新的层。代码只有一行:
@classmethod
def from_config(cls, config):
return cls(**config)
可见 from_config 是一个 classmethod,根据传入的参数,使用当前类的构造函数来生成一个实例。通过子类调用时,cls 是子类而不是基类 Layer。
官方文档的说明:
对于简单的定制操作,我们或许可以通过使用 layers.core.Lambda 层来完成。但对于任何具有可训练权重的定制层,你应该自己来实现。
build(input_shape):这是定义权重的方法,可训练的权应该在这里被加入列表self.trainable_weights中。其他的属性还包括self.non_trainabe_weights(列表)和self.updates(需要更新的形如(tensor, new_tensor)的 tuple 的列表)。你可以参考 BatchNormalization 层的实现来学习如何使用上面两个属性。这个方法必须设置 self.built = True,可通过调用 super([layer],self).build() 实现call(x):这是定义层功能的方法,除非你希望你写的层支持 masking,否则你只需要关心 call 的第一个参数:输入张量compute_output_shape(input_shape):如果你的层修改了输入数据的 shape,你应该在这里指定 shape 变化的方法,这个函数使得 Keras 可以做自动 shape 推断最简单的层 Activation 层 (没有参数):
class Activation(Layer):
def __init__(self, activation, **kwargs):
super(Activation, self).__init__(**kwargs)
self.supports_masking = True
self.activation = activations.get(activation)
def call(self, inputs):
return self.activation(inputs)
def get_config(self):
config = {‘activation‘: activations.serialize(self.activation)}
base_config = super(Activation, self).get_config()
return dict(list(base_config.items()) + list(config.items()))
Dropout 层:
class Dropout(Layer):
@interfaces.legacy_dropout_support
def __init__(self, rate, noise_shape=None, seed=None, **kwargs):
super(Dropout, self).__init__(**kwargs)
self.rate = min(1., max(0., rate))
self.noise_shape = noise_shape
self.seed = seed
self.supports_masking = True
def _get_noise_shape(self, inputs):
if self.noise_shape is None:
return self.noise_shape
symbolic_shape = K.shape(inputs)
noise_shape = [symbolic_shape[axis] if shape is None else shape
for axis, shape in enumerate(self.noise_shape)]
return tuple(noise_shape)
def call(self, inputs, training=None):
if 0. < self.rate < 1.:
noise_shape = self._get_noise_shape(inputs)
def dropped_inputs():
return K.dropout(inputs, self.rate, noise_shape,
seed=self.seed)
return K.in_train_phase(dropped_inputs, inputs,
training=training)
return inputs
def get_config(self):
config = {‘rate‘: self.rate,
‘noise_shape‘: self.noise_shape,
‘seed‘: self.seed}
base_config = super(Dropout, self).get_config()
return dict(list(base_config.items()) + list(config.items()))
Dense 层:
class Dense(Layer):
@interfaces.legacy_dense_support
def __init__(self, units,
activation=None,
use_bias=True,
kernel_initializer=‘glorot_uniform‘,
bias_initializer=‘zeros‘,
kernel_regularizer=None,
bias_regularizer=None,
activity_regularizer=None,
kernel_constraint=None,
bias_constraint=None,
**kwargs):
if ‘input_shape‘ not in kwargs and ‘input_dim‘ in kwargs:
kwargs[‘input_shape‘] = (kwargs.pop(‘input_dim‘),)
super(Dense, self).__init__(**kwargs)
self.units = units
self.activation = activations.get(activation)
self.use_bias = use_bias
self.kernel_initializer = initializers.get(kernel_initializer)
self.bias_initializer = initializers.get(bias_initializer)
self.kernel_regularizer = regularizers.get(kernel_regularizer)
self.bias_regularizer = regularizers.get(bias_regularizer)
self.activity_regularizer = regularizers.get(activity_regularizer)
self.kernel_constraint = constraints.get(kernel_constraint)
self.bias_constraint = constraints.get(bias_constraint)
self.input_spec = InputSpec(min_ndim=2)
self.supports_masking = True
def build(self, input_shape):
assert len(input_shape) >= 2
input_dim = input_shape[-1]
self.kernel = self.add_weight(shape=(input_dim, self.units),
initializer=self.kernel_initializer,
name=‘kernel‘,
regularizer=self.kernel_regularizer,
constraint=self.kernel_constraint)
if self.use_bias:
self.bias = self.add_weight(shape=(self.units,),
initializer=self.bias_initializer,
name=‘bias‘,
regularizer=self.bias_regularizer,
constraint=self.bias_constraint)
else:
self.bias = None
self.input_spec = InputSpec(min_ndim=2, axes={-1: input_dim})
self.built = True
def call(self, inputs):
output = K.dot(inputs, self.kernel)
if self.use_bias:
output = K.bias_add(output, self.bias)
if self.activation is not None:
output = self.activation(output)
return output
def compute_output_shape(self, input_shape):
assert input_shape and len(input_shape) >= 2
assert input_shape[-1]
output_shape = list(input_shape)
output_shape[-1] = self.units
return tuple(output_shape)
def get_config(self):
config = {
‘units‘: self.units,
‘activation‘: activations.serialize(self.activation),
‘use_bias‘: self.use_bias,
‘kernel_initializer‘: initializers.serialize(self.kernel_initializer),
‘bias_initializer‘: initializers.serialize(self.bias_initializer),
‘kernel_regularizer‘: regularizers.serialize(self.kernel_regularizer),
‘bias_regularizer‘: regularizers.serialize(self.bias_regularizer),
‘activity_regularizer‘: regularizers.serialize(self.activity_regularizer),
‘kernel_constraint‘: constraints.serialize(self.kernel_constraint),
‘bias_constraint‘: constraints.serialize(self.bias_constraint)
}
base_config = super(Dense, self).get_config()
return dict(list(base_config.items()) + list(config.items()))
一. 所有 keras 层的基类: Layerpython 语言基础重点关注以下函数1. add_weight2. call / __call__3. comput_output_shape4. build5. get_config / from_config二、实现自己的 keras 层代码示例 (来自 keras 代码库)
本博客旨在给经典的 ResNet 网络进行详解与代码实现,如有不足或者其他的见解,请在本博客下面留言。
在本篇博客中,将对 Resnet 的结构进行详细的解释,并用代码实现 ResNet 的网络结构。同时,本文还将引入另一篇论文 <>,来更加深入的理解 Resnet。本文使用 VOC2012 的数据集进行网络的训练,验证,与测试。为了快速开发,本次我们把 Keras 作为代码的框架。
Pascal VOC 为图像识别,检测与分割提供了一整套标准化的优秀的数据集,每一年都会举办一次图像识别竞赛。下面是 VOC2012,训练集 (包括验证集) 的下载地址。
VOC2012 里面有 20 类物体的图片,图片总共有 1.7 万张。我把数据集分成了 3 个部分,训练集,验证集,测试集,比例为 8:1:1。
下面是部分截图:
接着我们使用 keras 代码来使用这个数据集,代码如下:
IM_WIDTH=224 #图片宽度
IM_HEIGHT=224 #图片高度
batch_size=32 #批的大小
# train data
train_datagen = ImageDataGenerator(
width_shift_range=0.1,
height_shift_range=0.1,
shear_range=0.1,
zoom_range=0.1,
horizontal_flip=True,
rescale=1./255
)
train_generator = train_datagen.flow_from_directory(
train_root,
target_size=(IM_WIDTH, IM_HEIGHT),
batch_size=batch_size,
shuffle=True
)
# vaild data
vaild_datagen = ImageDataGenerator(
width_shift_range=0.1,
height_shift_range=0.1,
shear_range=0.1,
zoom_range=0.1,
horizontal_flip=True,
rescale=1./255
)
vaild_generator = train_datagen.flow_from_directory(
vaildation_root,
target_size=(IM_WIDTH, IM_HEIGHT),
batch_size=batch_size,
)
# test data
test_datagen = ImageDataGenerator(
rescale=1./255
)
test_generator = train_datagen.flow_from_directory(
test_root,
target_size=(IM_WIDTH, IM_HEIGHT),
batch_size=batch_size,
)
我使用了 3 个 ImageDataGenerator,分别来使用训练集,验证集与测试集的数据。使用 ImageDataGenerator 需要导入相应的模块,==from keras.preprocessing.image import ImageDataGenerator==。ImageDataGenrator 可以用来做数据增强,提高模型的鲁棒性. 它里面提供了许多变换,包括图片旋转,对称,平移等等操作。里面的 flow_from_directory 方法可以从相应的目录里面批量获取图片,这样就可以不用一次性读取所有图片 (防止内存不足)。
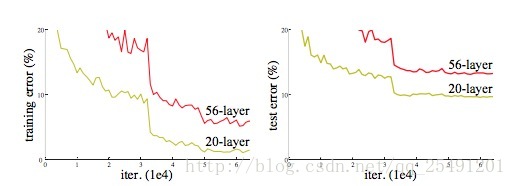
按照我们的惯性思维,一个网络越深则这个网络就应该具有更好的学习能力,而梯度退化是指下面一种现象:随着网络层数的增加,网络的效果先是变好到饱和,然后立即下降的一个现象。在这里,我们引用一幅来自 Resnet 里面的图片,更加直观的理解这个现象:
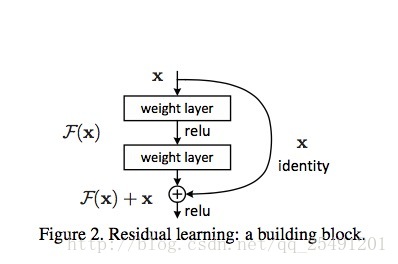
为了解决梯度退化的问题,论文中提出了 Residual learning 这个方法,它通过构造一个 Residual block 来完成。如图 Figure 2 所示,引入残差结构以后,把原来需要学习逼近的未知函数 H(x) 恒等映射 (Identity mapping), 变成了逼近 F(x)=H(x)-x 的一个函数。作者认为这两种表达的效果相同,但是优化的难度却并不相同,作者假设 F(x) 的优化会比 H(x) 简单的多。这一想法也是源于图像处理中的残差向量编码,通过一个 reformulation,将一个问题分解成多个尺度直接的残差问题,能够很好的起到优化训练的效果。
上图的恒等映射,是把一个输入 x 和其堆叠了 2 次后的输出 F(x) 的进行元素级和作为总的输出。因此它没有增加网络的运算复杂度,而且这个操作很容易被现在的一些常用库执行 (e.g.,Caffe,tensorflow)。
下面是一张没有使用普通图 (plain, 即没有加入恒等映射的图),与一张有 shortcut 图的对比:
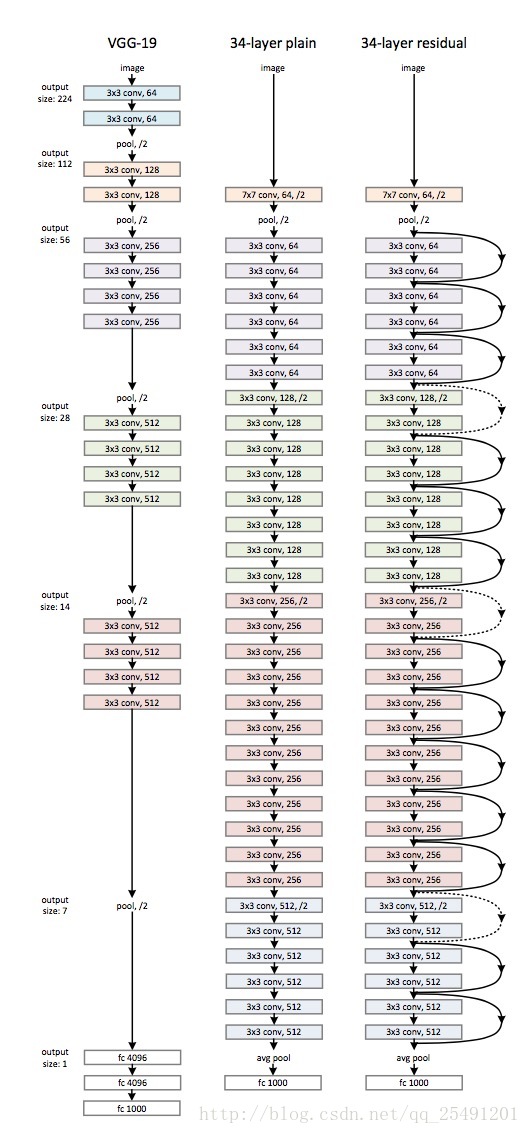
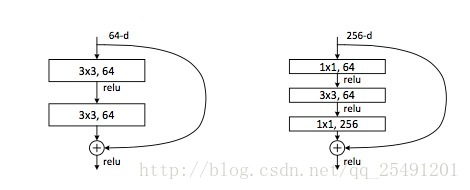
除了最简单的 Identity shortcuts(直接进行同纬度的元素级相加),论文还研究了 Projection shortcuts($ y=F(x,{W_i})+W_sx$). 论文研究了以下 3 种情况:
i. 对于纬度没有变化的连接进行直接相连,对于纬度增加的连接则通过补零填充后进行连接。由于 shortcuts 是恒等的,因此这个连接本身不会带来额外的参数。
ii. 对于纬度没有变化的连接进行直接相连,对于纬度增加的连接则通过投影相连,投影相连会增加参数。
iii. 对于所有的连接都采取投影相连。
作者对以上三种情况都进行了研究,发现 iii 的效果比 ii 好一点点点 (marginly better),发现 ii 的效果比 i 的效果好一点。这是因为$W_s$中带来的额外参数所带来的效果。
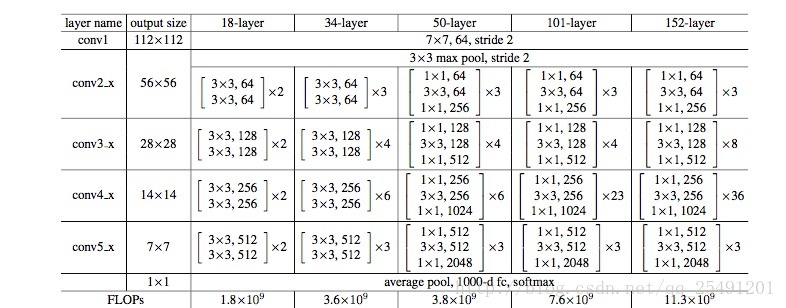
上图是一个 Resnet 的网络构建表,它显示了 resnet 是怎么构成的。同时这个表还提供了各个网络的运算浮点数,虽然 resnet 的层数比较深,但是它的运算量都小于 VGG-19(19.6x10 的 9 次方)。
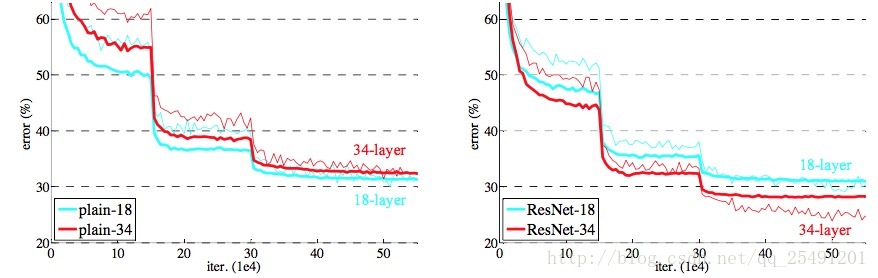
上图左边是普通的网络,右边是残差网络,较细的线代表验证误差,较粗的线则代表训练误差。我们可以看到普通的网络存在梯度退化的现象,即 34 层网络的训练和验证误差都大于 18 层的网络,而残差网络中则不存在这个现象。可见残差网络解决了梯度退化的问题。
graph TD
A(导入相应库) --> Z[模型参数设置以及其它配置]
Z --> B[生成训练集,测试集,验证集的三个迭代器]
B --> C[identity_block函数的编写]
C --> D[bottleneck_block函数的编写]
D --> F[根据resnet网络构建表来构建网络]
F --> G[模型训练与验证]
G --> H[模型保存]
H --> I(模型在测试集上测试)
# coding=utf-8
from keras.models import Model
from keras.layers import Input, Dense, Dropout, BatchNormalization, Conv2D, MaxPooling2D, AveragePooling2D, concatenate, Activation, ZeroPadding2D
from keras.layers import add, Flatten
from keras.utils import plot_model
from keras.metrics import top_k_categorical_accuracy
from keras.preprocessing.image import ImageDataGenerator
from keras.models import load_model
import os
# Global Constants
NB_CLASS=20
IM_WIDTH=224
IM_HEIGHT=224
train_root=‘/home/faith/keras/dataset/traindata/‘
vaildation_root=‘/home/faith/keras/dataset/vaildationdata/‘
test_root=‘/home/faith/keras/dataset/testdata/‘
batch_size=32
EPOCH=60
# train data
train_datagen = ImageDataGenerator(
width_shift_range=0.1,
height_shift_range=0.1,
shear_range=0.1,
zoom_range=0.1,
horizontal_flip=True,
rescale=1./255
)
train_generator = train_datagen.flow_from_directory(
train_root,
target_size=(IM_WIDTH, IM_HEIGHT),
batch_size=batch_size,
shuffle=True
)
# vaild data
vaild_datagen = ImageDataGenerator(
width_shift_range=0.1,
height_shift_range=0.1,
shear_range=0.1,
zoom_range=0.1,
horizontal_flip=True,
rescale=1./255
)
vaild_generator = train_datagen.flow_from_directory(
vaildation_root,
target_size=(IM_WIDTH, IM_HEIGHT),
batch_size=batch_size,
)
# test data
test_datagen = ImageDataGenerator(
rescale=1./255
)
test_generator = train_datagen.flow_from_directory(
test_root,
target_size=(IM_WIDTH, IM_HEIGHT),
batch_size=batch_size,
)
def Conv2d_BN(x, nb_filter, kernel_size, strides=(1, 1), padding=‘same‘, name=None):
if name is not None:
bn_name = name + ‘_bn‘
conv_name = name + ‘_conv‘
else:
bn_name = None
conv_name = None
x = Conv2D(nb_filter, kernel_size, padding=padding, strides=strides, activation=‘relu‘, name=conv_name)(x)
x = BatchNormalization(axis=3, name=bn_name)(x)
return x
def identity_Block(inpt, nb_filter, kernel_size, strides=(1, 1), with_conv_shortcut=False):
x = Conv2d_BN(inpt, nb_filter=nb_filter, kernel_size=kernel_size, strides=strides, padding=‘same‘)
x = Conv2d_BN(x, nb_filter=nb_filter, kernel_size=kernel_size, padding=‘same‘)
if with_conv_shortcut:
shortcut = Conv2d_BN(inpt, nb_filter=nb_filter, strides=strides, kernel_size=kernel_size)
x = add([x, shortcut])
return x
else:
x = add([x, inpt])
return x
def bottleneck_Block(inpt,nb_filters,strides=(1,1),with_conv_shortcut=False):
k1,k2,k3=nb_filters
x = Conv2d_BN(inpt, nb_filter=k1, kernel_size=1, strides=strides, padding=‘same‘)
x = Conv2d_BN(x, nb_filter=k2, kernel_size=3, padding=‘same‘)
x = Conv2d_BN(x, nb_filter=k3, kernel_size=1, padding=‘same‘)
if with_conv_shortcut:
shortcut = Conv2d_BN(inpt, nb_filter=k3, strides=strides, kernel_size=1)
x = add([x, shortcut])
return x
else:
x = add([x, inpt])
return x
def resnet_34(width,height,channel,classes):
inpt = Input(shape=(width, height, channel))
x = ZeroPadding2D((3, 3))(inpt)
#conv1
x = Conv2d_BN(x, nb_filter=64, kernel_size=(7, 7), strides=(2, 2), padding=‘valid‘)
x = MaxPooling2D(pool_size=(3, 3), strides=(2, 2), padding=‘same‘)(x)
#conv2_x
x = identity_Block(x, nb_filter=64, kernel_size=(3, 3))
x = identity_Block(x, nb_filter=64, kernel_size=(3, 3))
x = identity_Block(x, nb_filter=64, kernel_size=(3, 3))
#conv3_x
x = identity_Block(x, nb_filter=128, kernel_size=(3, 3), strides=(2, 2), with_conv_shortcut=True)
x = identity_Block(x, nb_filter=128, kernel_size=(3, 3))
x = identity_Block(x, nb_filter=128, kernel_size=(3, 3))
x = identity_Block(x, nb_filter=128, kernel_size=(3, 3))
#conv4_x
x = identity_Block(x, nb_filter=256, kernel_size=(3, 3), strides=(2, 2), with_conv_shortcut=True)
x = identity_Block(x, nb_filter=256, kernel_size=(3, 3))
x = identity_Block(x, nb_filter=256, kernel_size=(3, 3))
x = identity_Block(x, nb_filter=256, kernel_size=(3, 3))
x = identity_Block(x, nb_filter=256, kernel_size=(3, 3))
x = identity_Block(x, nb_filter=256, kernel_size=(3, 3))
#conv5_x
x = identity_Block(x, nb_filter=512, kernel_size=(3, 3), strides=(2, 2), with_conv_shortcut=True)
x = identity_Block(x, nb_filter=512, kernel_size=(3, 3))
x = identity_Block(x, nb_filter=512, kernel_size=(3, 3))
x = AveragePooling2D(pool_size=(7, 7))(x)
x = Flatten()(x)
x = Dense(classes, activation=‘softmax‘)(x)
model = Model(inputs=inpt, outputs=x)
return model
def resnet_50(width,height,channel,classes):
inpt = Input(shape=(width, height, channel))
x = ZeroPadding2D((3, 3))(inpt)
x = Conv2d_BN(x, nb_filter=64, kernel_size=(7, 7), strides=(2, 2), padding=‘valid‘)
x = MaxPooling2D(pool_size=(3, 3), strides=(2, 2), padding=‘same‘)(x)
#conv2_x
x = bottleneck_Block(x, nb_filters=[64,64,256],strides=(1,1),with_conv_shortcut=True)
x = bottleneck_Block(x, nb_filters=[64,64,256])
x = bottleneck_Block(x, nb_filters=[64,64,256])
#conv3_x
x = bottleneck_Block(x, nb_filters=[128, 128, 512],strides=(2,2),with_conv_shortcut=True)
x = bottleneck_Block(x, nb_filters=[128, 128, 512])
x = bottleneck_Block(x, nb_filters=[128, 128, 512])
x = bottleneck_Block(x, nb_filters=[128, 128, 512])
#conv4_x
x =