标签:当前目录 -name 三次 补充 最大 不难 end exp 内容
作用:
1.用于取出变量中的内容
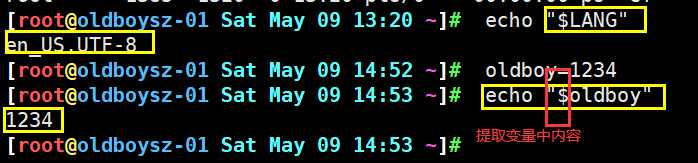
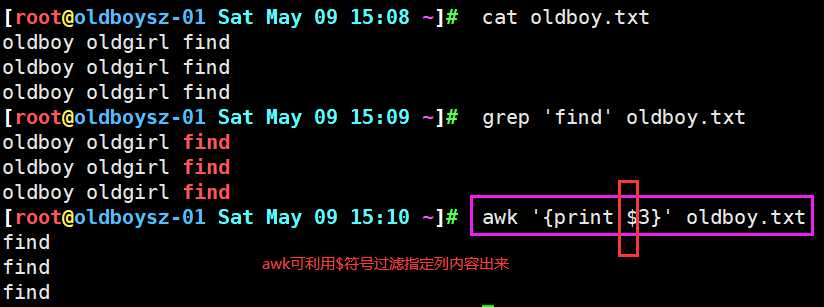
2.用于取出指定列的信息(awk)
3.表示用户命令提示符

4.表示一行的结尾
在vim 中利用$符号可将光标跳转到当前行行尾
1.用于表示取反(逻辑非)或者排除的意思
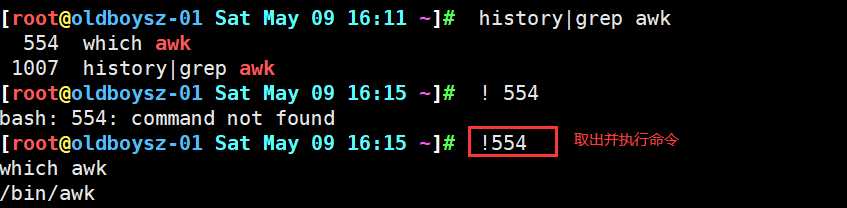
2.命令行中表示取出最近命令
3.用于表示强制操作处理 vim 底行模式用于保存退出 :wq! :q!
1.表示 管道符号,前一个命令的执行结果交给后一个命令处理
2.经常配合xargs命令使用 xargs:将信息进行分组显示
1.表示文件内容注释符号
2.表示用户命令提示符: 超级用户 # 普通用户 $
输出信息所见即所得

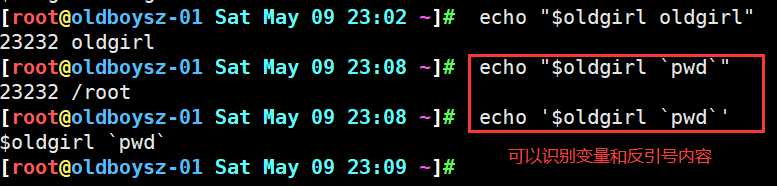
和单引号功能类似.但对特殊信息会做解析(调取变量$ 反引号中的内容)
和双引号功能类似,但是可以直接识别通配符信息

先执行引号里面的命令,将结果交给引号外面的命令执行

等价于反引号
< 标准输入重定向
tr "测试""替换" < oldboy/oldboy.txt 利用tr替换命令时会用到输入重定向
<< 标准输入追加重定向
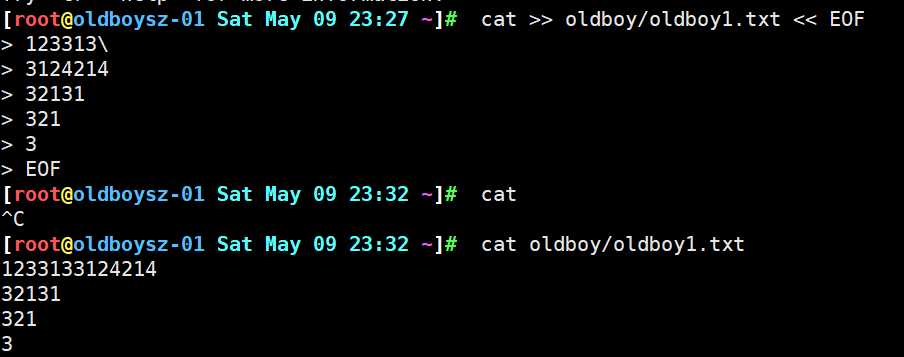
cat >> oldboy/oldboy1.txt << EOF 在文件中输入多行内容时会用到输入追加重定向
>=1> 标准输出重定向
>>=1>> 标准输出追加重定向
2> 错误输出重定向
2>> 错误输出追加重定向
1.如何将正确信息和错误信息都输出到文件中(日志文件)
命令 oldboy > oldboy.ok.txt 2> oldboy.error.txt

利用一条命令将正确与错误的结果输出到不同的文件中,当命令执行正确的时候,正确结果将输出到ok也就是正确文件中,当命令执行不正确的时候,错误记过将输出到error也就是错误文件中,这就实现了命令执行正确与否结果都会输出
2.如何将正确信息和错误信息同时保留到文件中
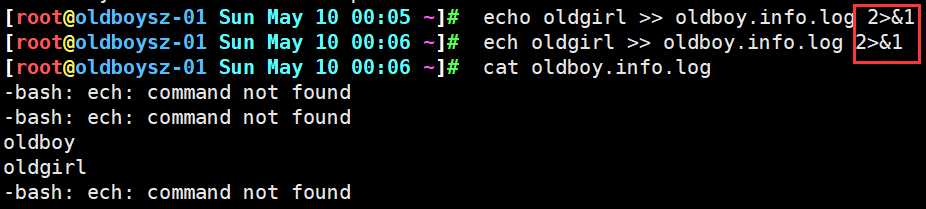
方法一:命令 oldboy >> oldboy.info.log 2>> oldboy.info.log

方法二:命令 oldboy &>> oldboy.info.log
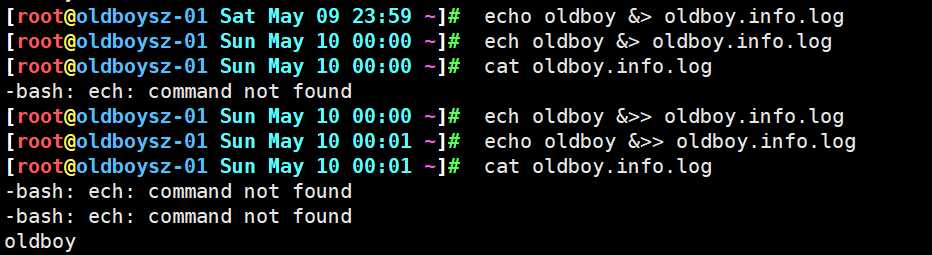
方法三:命令 oldboy >> oldboy.info.log 2>>&1
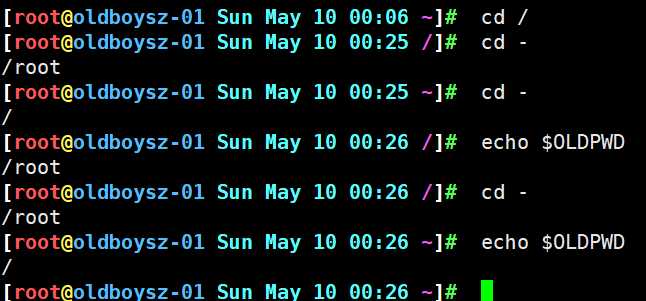
两个目录中间进行切换其实是借助于一个变量实现的
表示前面的命令执行成功,再执行后面的命令
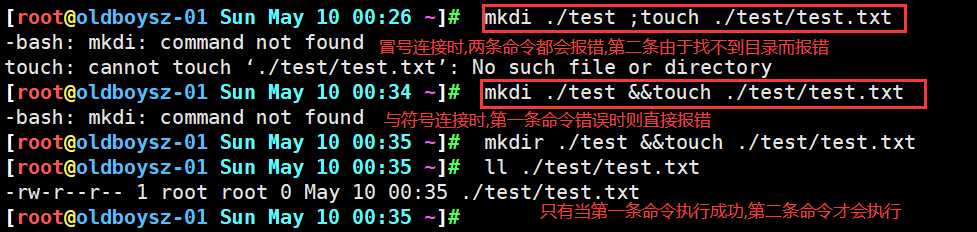
当前面的命令执行错误的时候,则直接报错,后面的命令被忽略,只有前面的命令正确执行时,后面的命令才会执行
表示前面的命令执行失败,在执行后面的命令
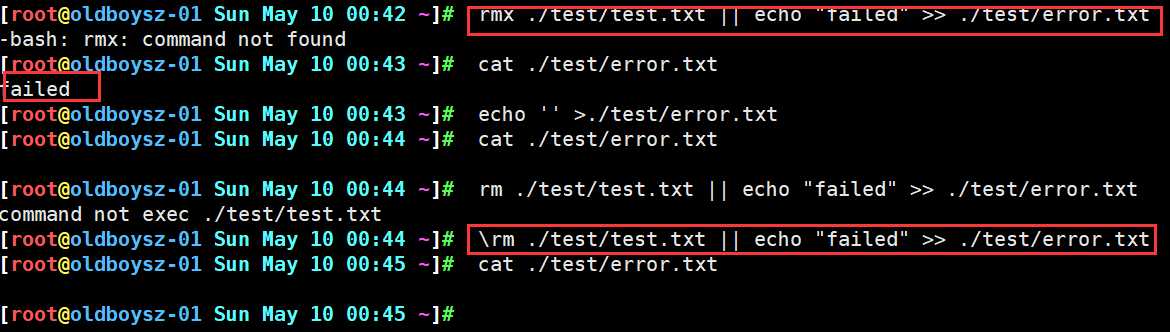
当前面的命令执行错误时,后面的命令才会执行,当前面的的命令执行成功时,后面的命令不会执行
方便匹配找出多个数据文件(按照文件名称进行匹配查找)
表示匹配所有内容信息
find / -type f -name "*.txt" --- 表示以什么结尾的文件
find / -type f -name "old*" --- 表示以什么开始的文件
1.生成序列信息
01.生成连续序列 echo {1..4} echo {a..d} echo {A..D} echo {01..10}
02.生成不连续序列 echo {1..10..2}奇数 echo {2..10..2}偶数
2.生成组合信息
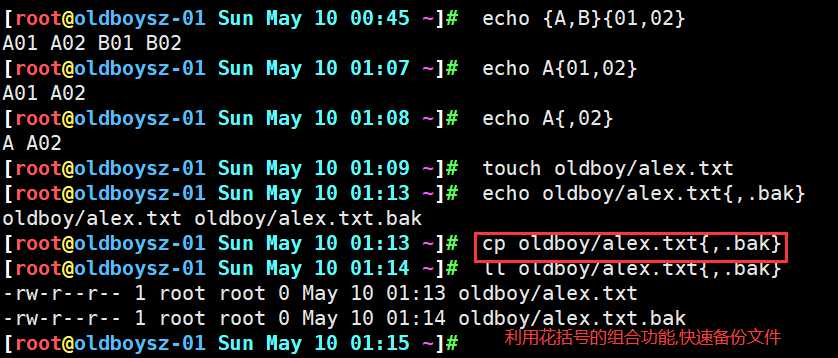
echo A{,02}用来衍生出另一个常用功能

如何实现快速备份文件
cp oldboy/alex.txt{,.bak}
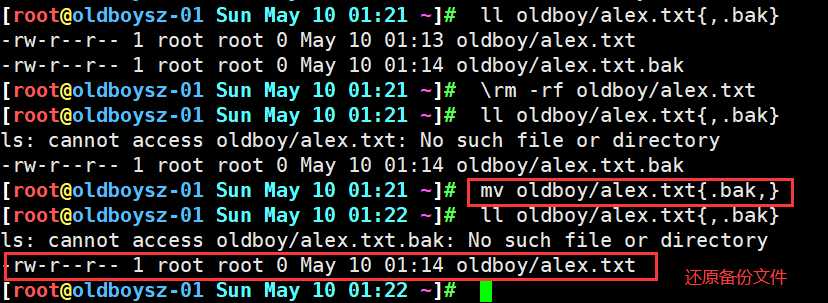
如何实现快速还原备份文件
mv oldboy/alex.txt{.bak,}
方便匹配找出文件中的内容信息
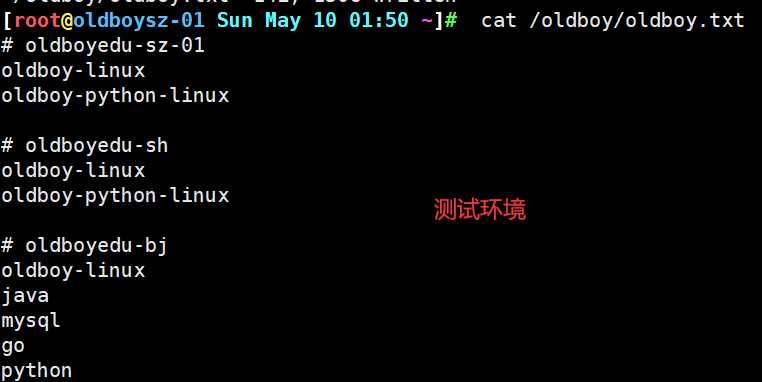
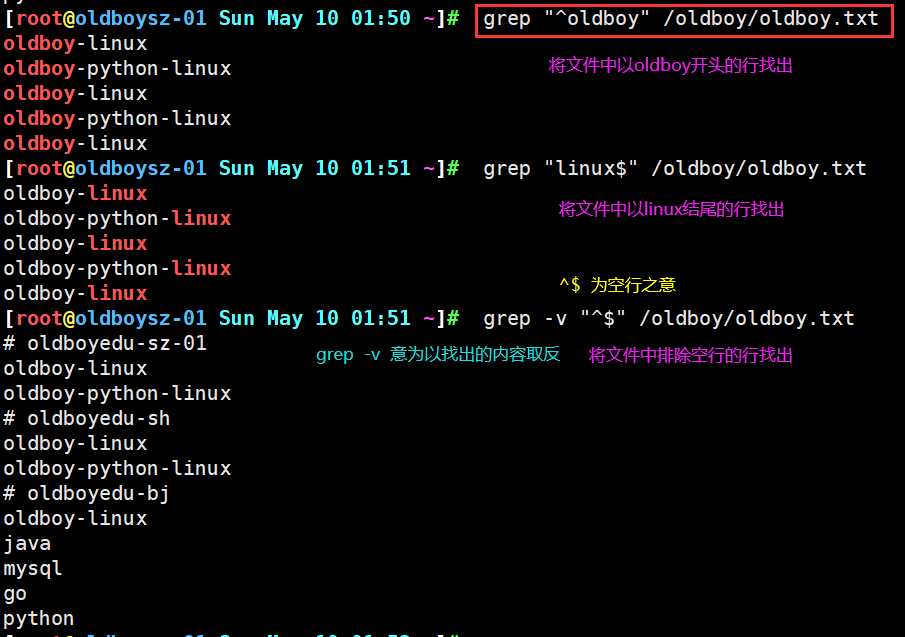
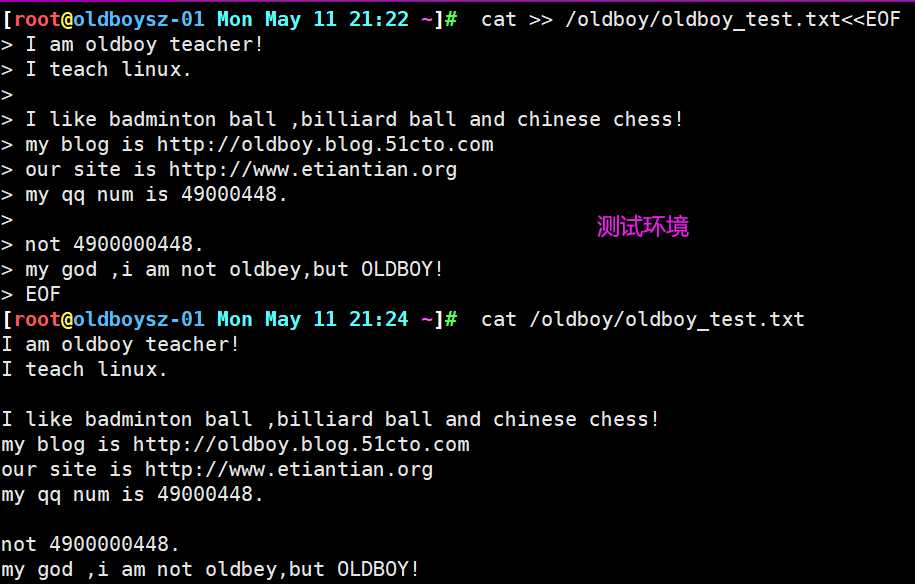
上述为以下内容的测试环境
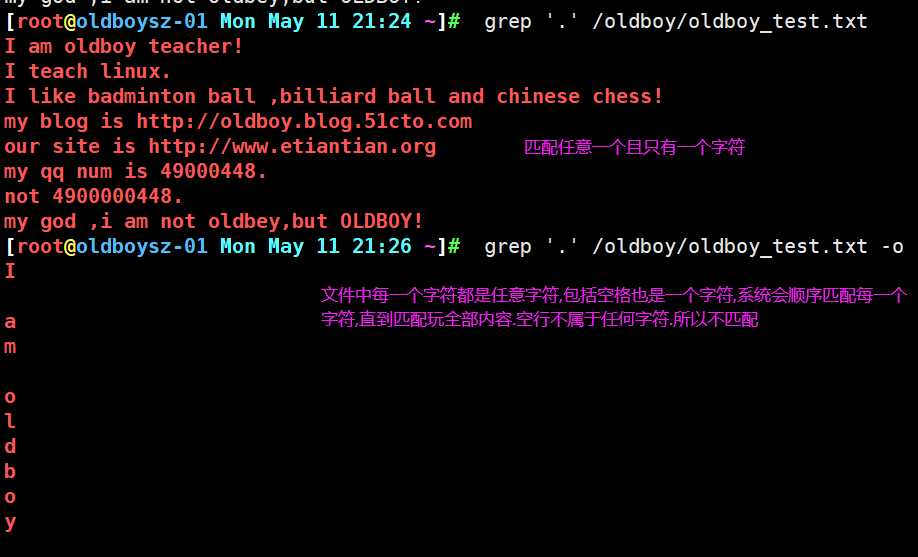
文件中每一个字符都是任意字符,包括空格也是一个字符,系统会顺序匹配每一个字符,直到匹配完全部内容,空行不属于任何字符,所以不匹配,
上述grep -o grep命令添加参数-o 意为显示匹配过程
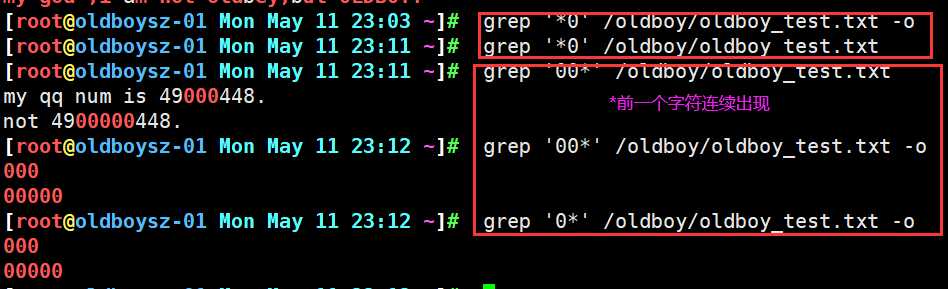
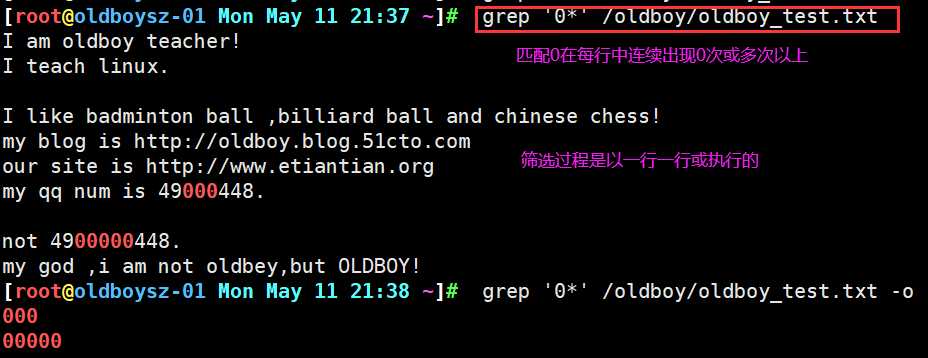
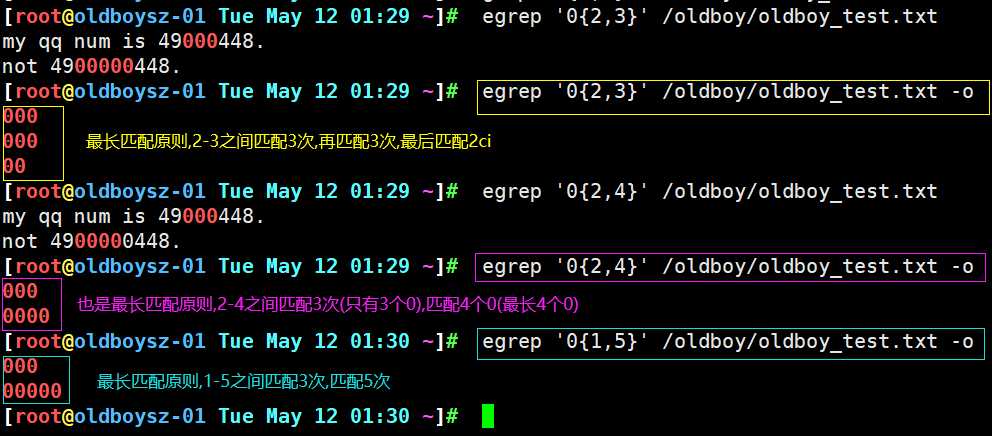
grep命令查询文件中0在每行连续出现的次数,可以看出连续出现三次的行,和连续出现5次的行被准确匹配,之所以会显示其他行,是因为*的特性,会匹配0连续出现次数为0的行即为没有0连续出现的行,所以其他行及空行也会被显示出来.
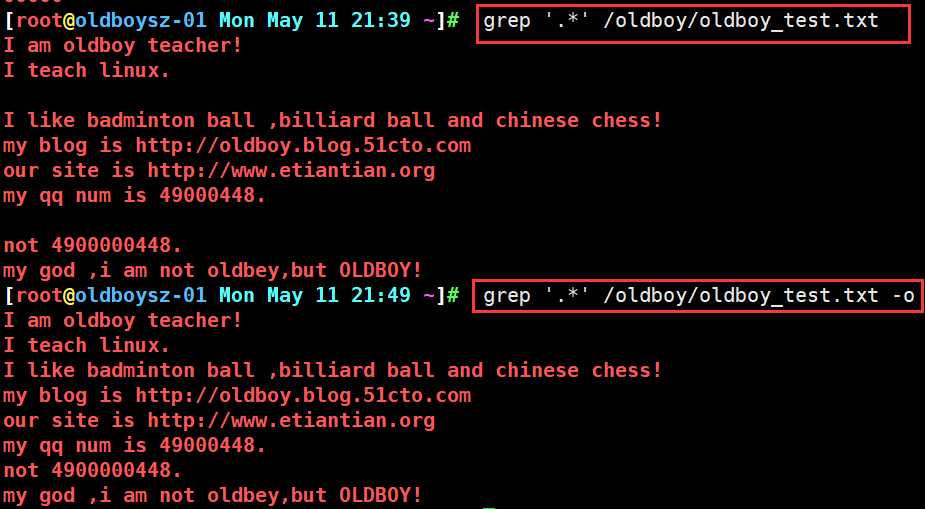
. 会匹配出任意内容,而*会匹配.连续出现那几行,没有出现的空行也会被显示出来. .* 一般用来匹配文件全部内容
此处会衍生出一个贪婪匹配问题:
#此时需要匹配以m开头以o结尾的内容 即 my blo和my go 内容
grep ‘^m.* o‘ ---- 以开头以o结尾,中间任意内容

上述我们利用^ 和 .* 结合,匹配出以m 开头 以o 结尾 ,中间任意内容的信息.理论上来说只会出现,我们需要的内容,但显然不是,此时我们若想解决此类问题,必须必须对指定匹配内容进行修改
#解决办法:指定具体信息阻止贪婪匹配

将需要匹配的内容进行具体描述用来加以区别,‘^m.* blo‘ 意为以m开头 以 blo结尾的内容.
作用:
1.将有特殊意义的符号,转义为普通信息进行识别
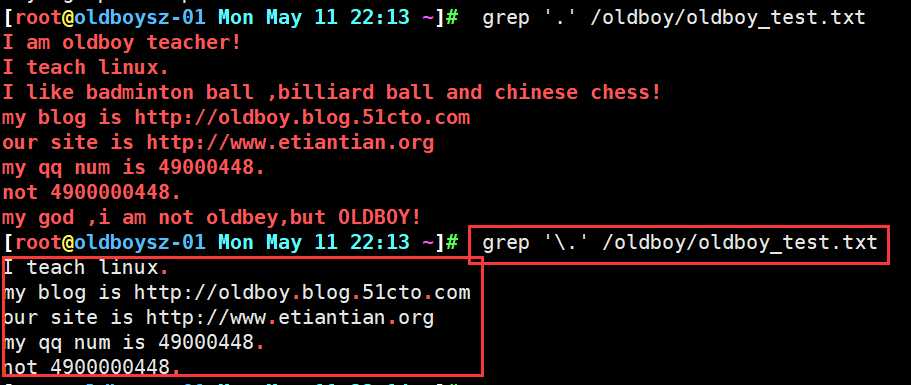
2.将没有意义的信息转义为有特殊意义的信息 \n(换行) \t(制表)=tab

echo 打印输出一行内容,利用\n的转义含义再对内容进行输出,此时内容还是一行显示,此时需要利用echo 的-e参数允许输出的内容进行转义,然后得到多行内容
补充说明:系统中两种方法输入多行内容到文件中
1 cat >> oldboy.txt << EOF
>oldboy01
>oldboy02
>oldboy03
>EOF
2 echo -e "oldboy01\noldboy02\noldboy03">oldboy.txt
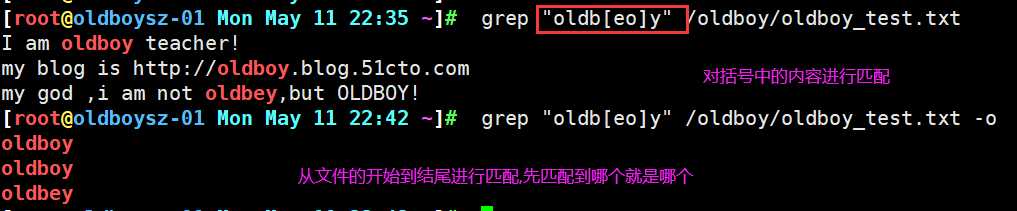
对括号中多个字符进行匹配,在文件内容中从第一行往下进行匹配,首先发现中括号中o字符进行匹配.再往下又发现一个o在进行匹配,最后匹配到括号中e字符,所以对于括号中字符,grep 会一个一个全部匹配上
扩展问题:找出文件中以特定字符开头的内容
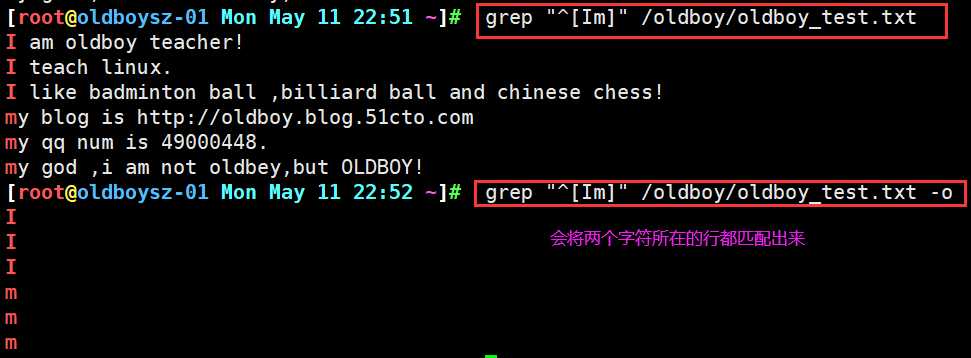
1.找出以 I 和 m 开头的行 ^[Im] 以I和m开头的行
2.找出selinux中除去注释行的全部内容 ^[a-Z] 以字母开头的内容
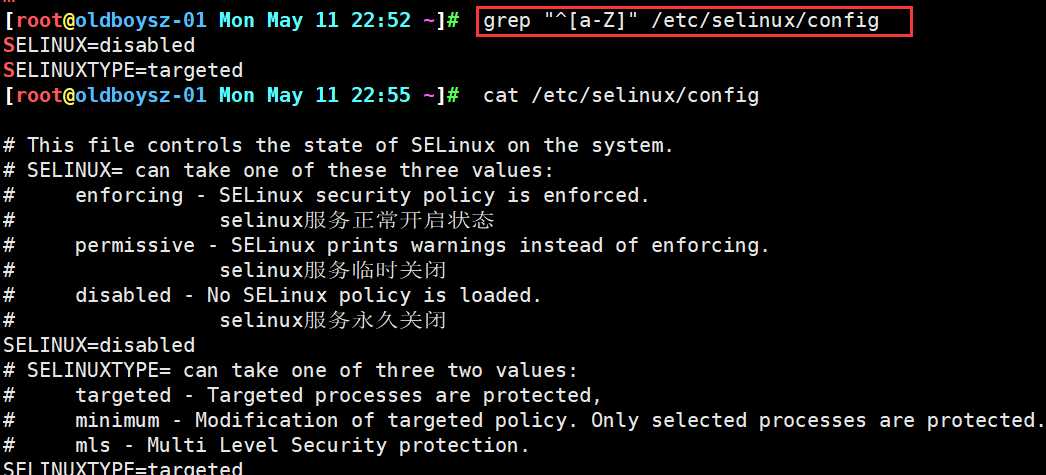
查看selinux配置文件可以发现除去以#开头的注释行之外.其他行都是字母开头的当然这个文件只有一个字母S,由此我们可以利用一种正则符号^[a-Z] 在利用 grep 筛选.将以任意字母开头的文件都筛选出来
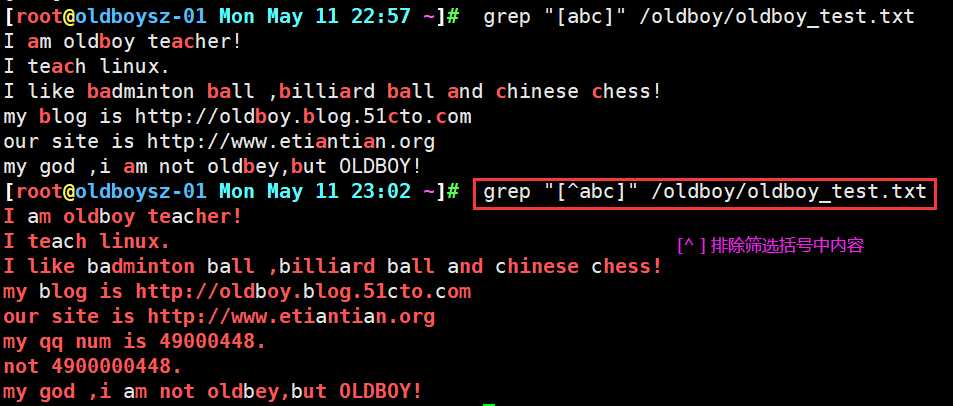
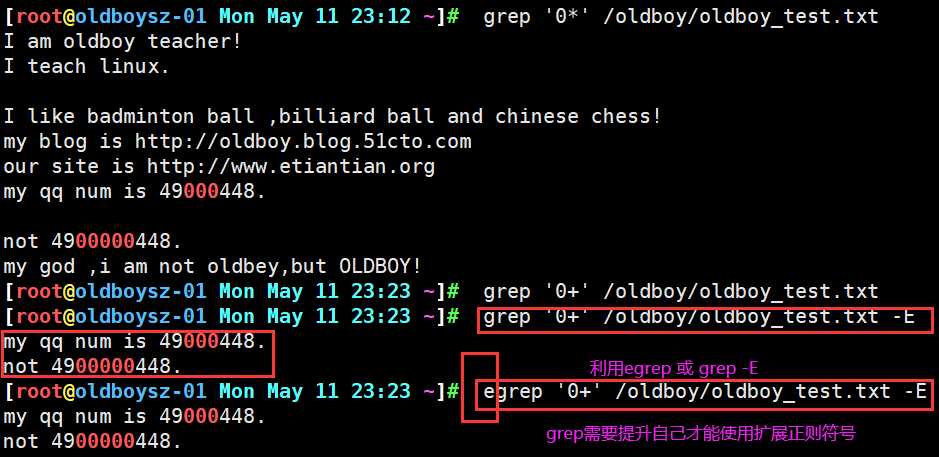
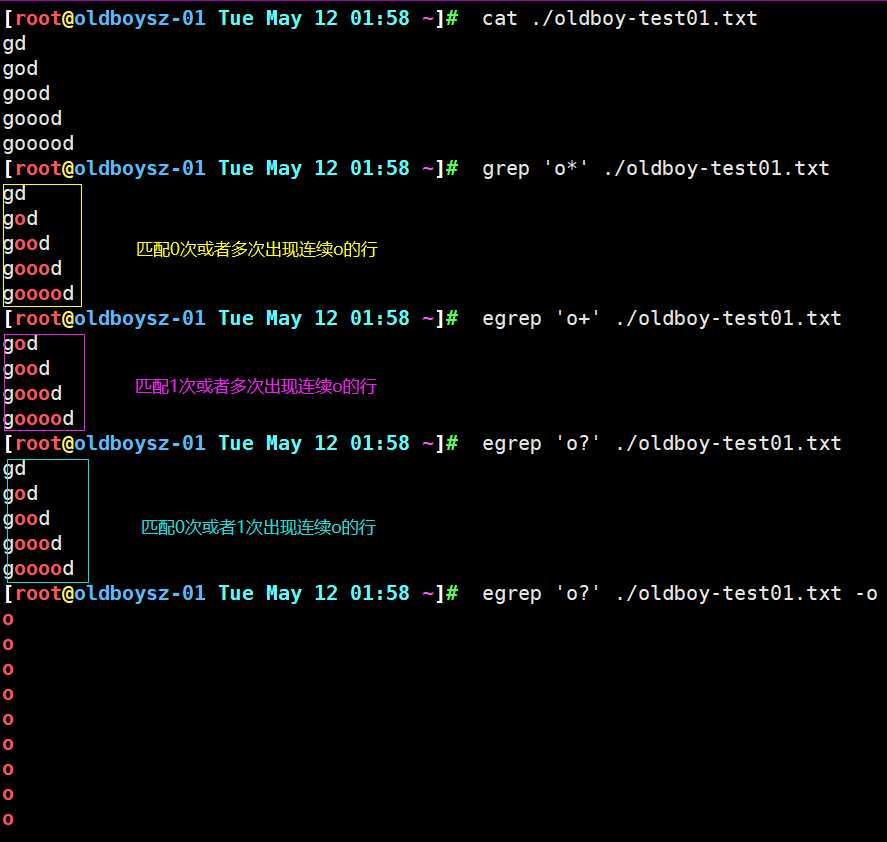
对比 * 的匹配原则不难发现, + 匹配的 + 号前一个字符连续出现一次或多次以上行, 由上 0 连续出现一次的行唯有两行, 所以只列出此两行 , 对于grep 来说 要想使用 扩展正则符号需要加 -E 参数或者领用 egrep 命令
补充总结说明 : 一般 + 符号经常是与 [] 使用, 可以匹配出多个不同的连续字符
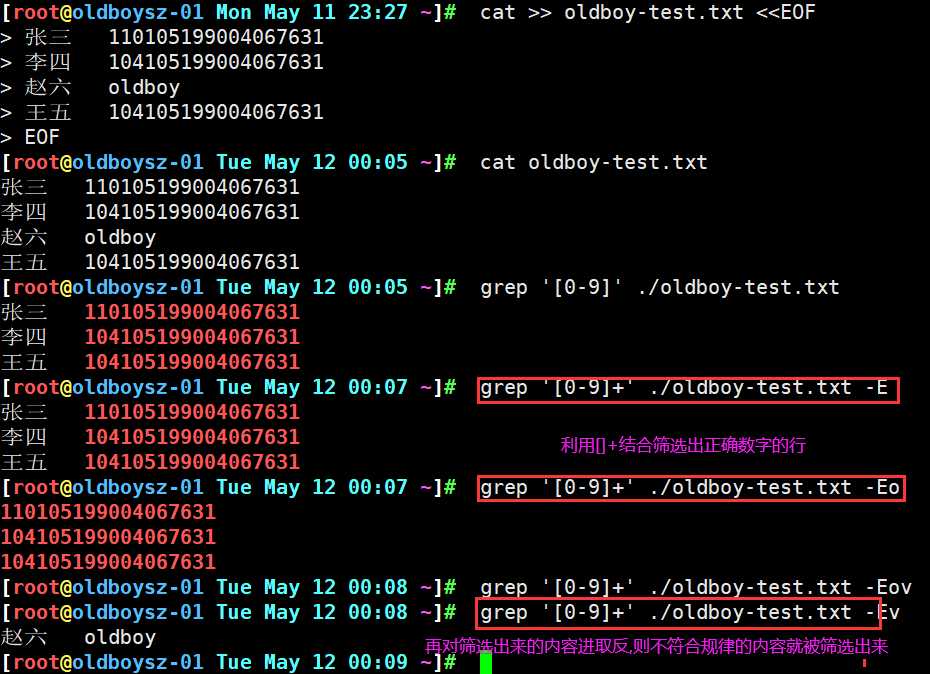
一般网站会出现身份证号及手机号的输入提示框,此时如果我们输入其他非数字的内容时,系统会报错,那如何对输入的内容进行判断筛选,就是利用[]+对输入的信息进行匹配查看
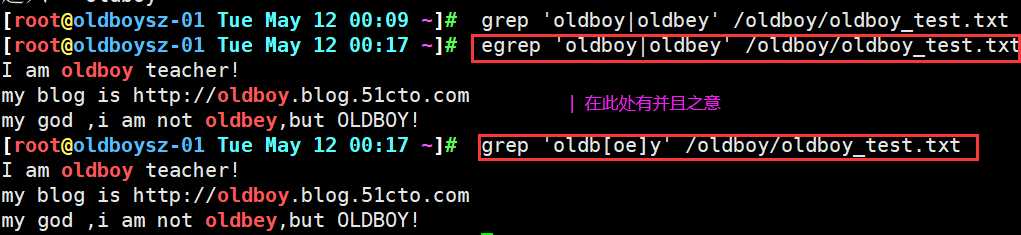
作用:
1.指定信息进行整体匹配
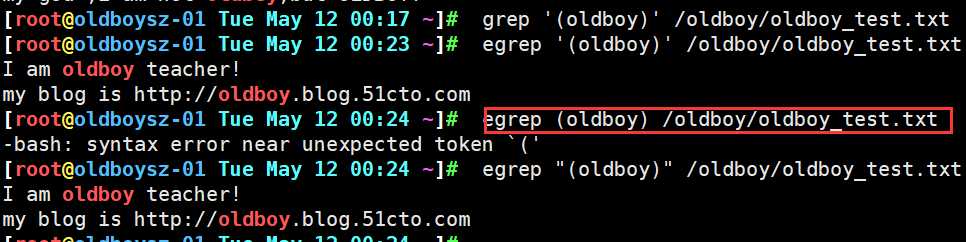
对()中的内容进行整体匹配, 此间注意一点 grep 利用扩展正则符号进行匹配时, 需要加引号 将正则符号引起来,不然系统无法正确判断正则符号作用
2.进行后项引用前项使用 :
1 .多用于sed 命令中的替换作用(一次性创建多个用户--详见系统中如何批量创建用户并设置8位随机密码)
echo oldboy{01..10}|xargs -n1|sed -r ‘s#(.*)#useradd \1#g‘|bash -- 创建用户
seq -w 10|sed -r ‘s#(.*)#useradd oldboy\1;echo 123456|passwd --stdin oldboy\1#g‘ -- 创建用户和密码
2 .将输出的信息转换后输出
echo 123456 ==> 转换为 <123456>进行显示
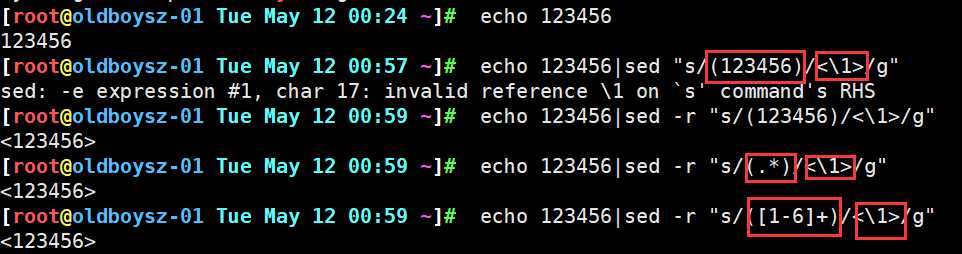
利用sed的替换功能实现()的后项引用前项功能 ( ) \1
echo 123456 ==> 转换为 <12><34><56>进行显示

echo 123456 ==> 转换为 <12>34<56>进行显示

1. x{n,m} 表示前一个字符至少连续出现n次,最多出现m次
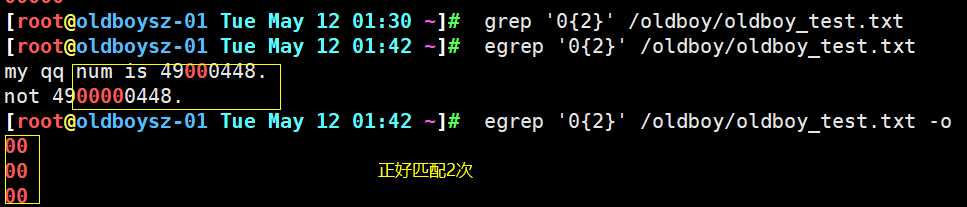
1. x{n} 表示前一个字符正好连续出现n次
1. x{n,} 表示前一个字符至少连续出现n次,最多出现多少次不限
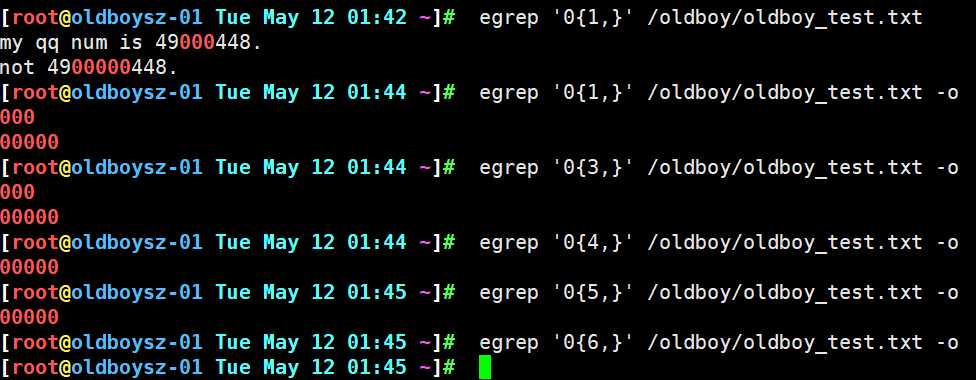
表示0连续次数n-∞ 若 n大于文件中0连续出现的次数,则grep不会匹配任何内容,因为不满足条件
1. x{,m} 表示前一个字符至少连续出现0次,最多出现m次
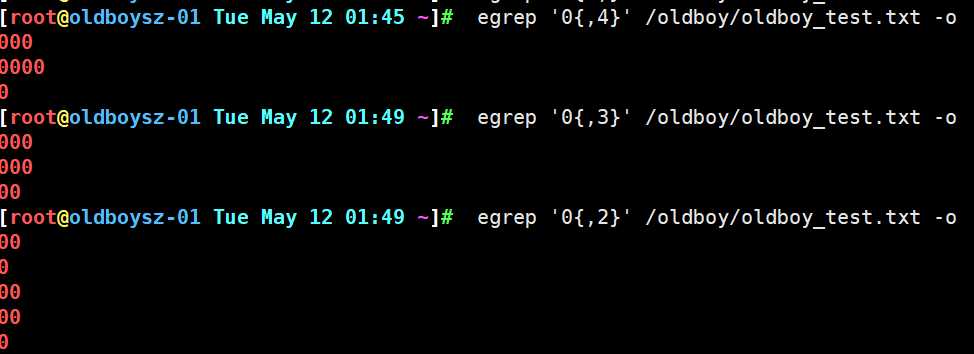
表示0连续出现次0-n 依旧遵循最大匹配原则
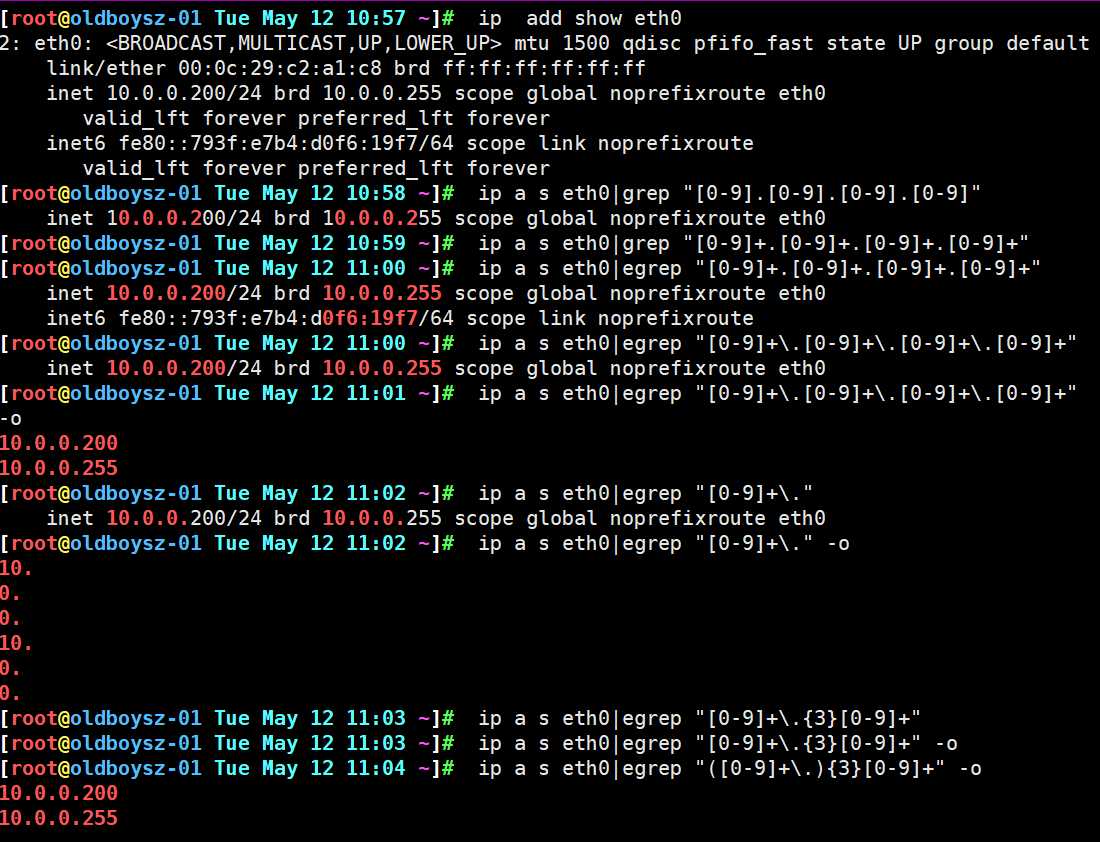
正则符号练习:利用ip address show eth0只把IP地址信息显示出来?
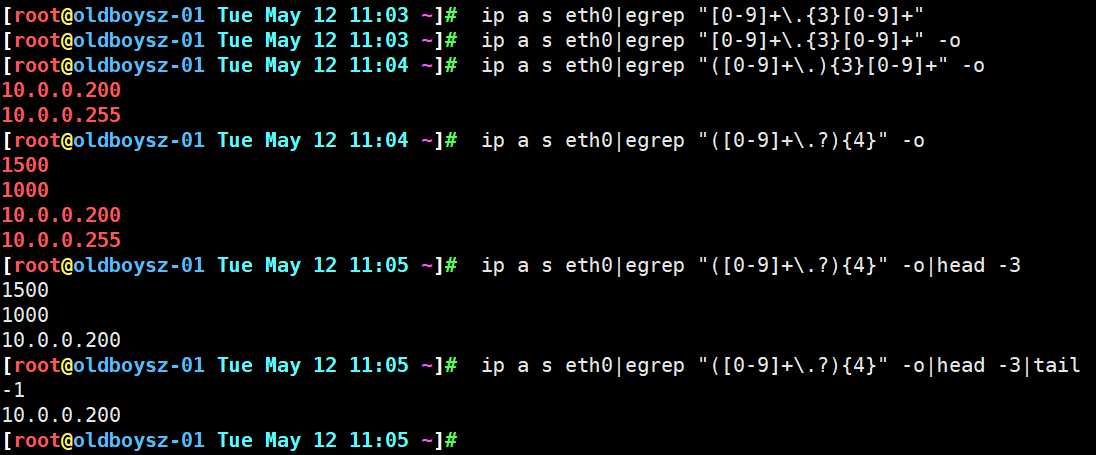
让grep sed命令可以直接识别扩展正则
[root@oldboyedu ~]# grep "o\+" oldboy_test03.txt
god
good
goood
gooood
企业面试常见问题
正则符号与通配符号区别
通配符号
作用说明:查找文件名称信息
使用场景:命令行经常使用
正则符号
作用说明:查找文件内容信息
使用场景:三剑客命令经常使用/各种语言经常使用
学习方法总结说明
正则符号学习与帮助方法
利用手册信息
man grep/sed/awk
info grep/sed/awk(更加详细)
利用官方资料
http://www.gnu.org/software/grep/manual/
标签:当前目录 -name 三次 补充 最大 不难 end exp 内容
原文地址:https://www.cnblogs.com/zp751060301/p/12858747.html