标签:googl sub epo 实践 思想 lct target tail 故障
前一段时间写了使用keepalived+haproxy部署k8s高可用集群,核心思想是利用keepalived生成vip实现主备容灾,以及haproxy负载k8s-apiserver流量。k8s高可用部署:keepalived + haproxy
这种方式是自己实现了负载均衡。本文将探讨在用户已有SLB的场景下如何实现k8s高可用
阿里云文档中SLB(Server Load Balancer)介绍如下:
负载均衡基础架构是采用集群部署,提供四层(TCP协议和UDP协议)和七层(HTTP和HTTPS协议)的负载均衡,可实现会话同步,以消除服务器单点故障,提升冗余,保证服务的稳定性。
负载均衡作为流量转发服务,将来自客户端的请求通过负载均衡集群转发至后端服务器,后端服务器再将响应通过内网返回给负载均衡。
本文还涉及到SLB的一个关键技术限制:
在 4 层(TCP 协议)服务中,不支持添加进后端的服务器既作为 Real Server,又作为客户端向所在的 SLB 实例发送请求。因为,返回的数据包只在服务器内部转发,不经过负载均衡,所以通过配置在 SLB 后端的 服务器去访问其 VIP 是不通的。
另外对于SLB的健康检查、调度算法等最佳实践不做探讨,请查阅相关文档。文本探讨的范围仅限于架构可行性验证。
由于4层SLB不支持后端服务访问其VIP,根据kubeadm官方安装文档:

指定vip会发生如下超时错误:
[etcd] Creating static Pod manifest for local etcd in “/etc/kubernetes/manifests”
[wait-control-plane] Waiting for the kubelet to boot up the control plane as static Pods from directory “/etc/kubernetes/manifests”. This can take up to 4m0s
[kubelet-check] Initial timeout of 40s passed.
查看kubele日志:
# sudo journalctl -u kubelet.service
k8s.io/kubernetes/pkg/kubelet/kubelet.go:442: Failed to list *v1.Service: Get https://172.16.105.26:9443/api/v1/services?limit=500&resourceVersion=0: dial tcp 172.16.105.26:9443: connect: connection refused
还记得之前说的4层负载的技术限制吗?
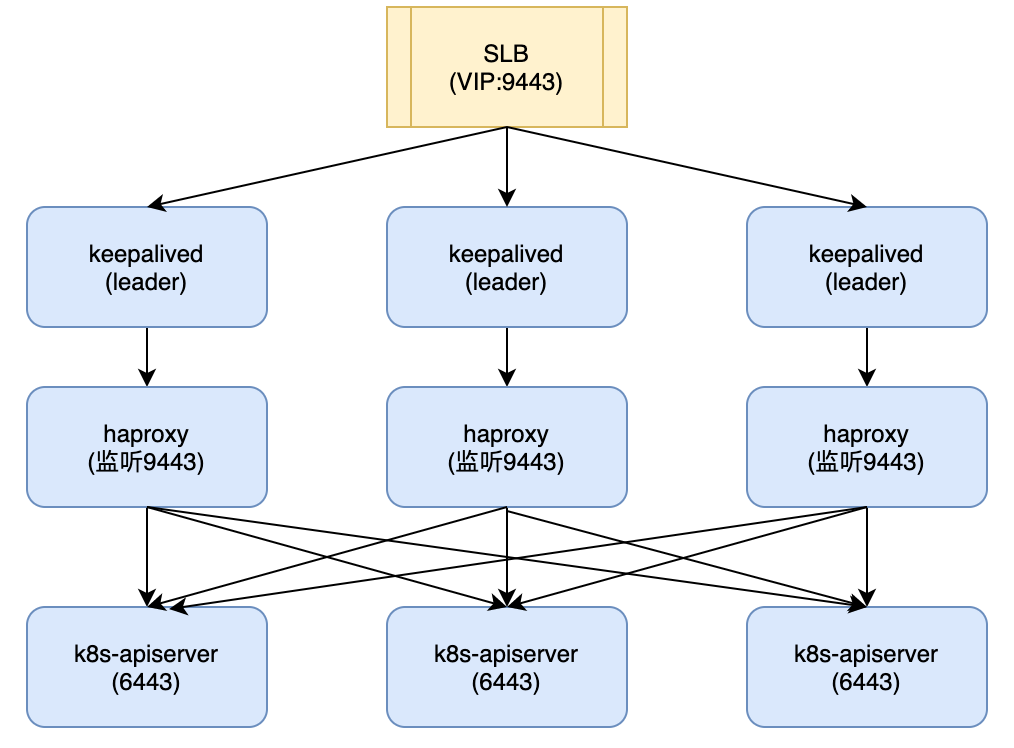
基于此我们出了一个比较”脏”的方案:keepalived+haproxy。安装步骤与上一篇文章一样,只是结果不同:
问题:
1. 这种实现方式相当于在LB的后端又实现一次LB,但是用户请求多了一次转发, 显然不是一个令人满意的方案。
2. 这种keepalived全主模式不能应用在纯vip场景下(如openstack)。这种情况安装是没问题的,master1先绑定vip,master2,3通过vip访问apiserver时走本地流量,由于本地apiserver:6443还未启动,被haproxy负载到健康节点。这么做安装是没问题的。但是不能保证高可用。当master1 done时,子网内部访问vip还是能找到另外两台健康节点,但是子网外部访问时,路由器还是会路由到master1。
keepalived的解决方式其实是将vip绑定三台k8s-master,使得三台主机初始化时走本地网络,解决后端访问不了slb的问题。那么其实我们不需要在keepalived后面再加一层haproxy,使得请求多一次转发,更进一步,我们不需要keepalived来绑定vip,手动绑定就好了。
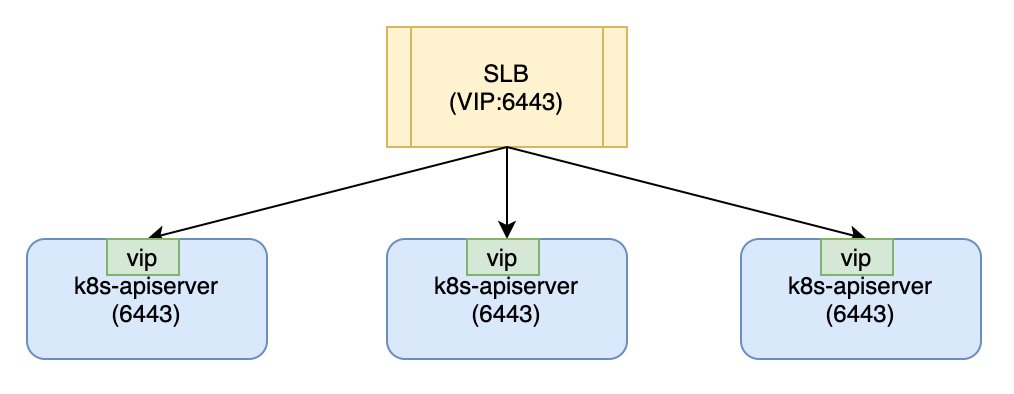
安装步骤:
2.1 init k8s-master-leader
绑定vip:
# ip addr add 172.16.105.26/32 dev eth0
查询绑定结果:
#ip a| grep eth0
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
inet 172.16.104.54/24 brd 172.16.104.255 scope global eth0
inet 172.16.105.26/32 scope global eth0
kubeadm-config.yaml
apiVersion: kubeadm.k8s.io/v1beta1
kind: ClusterConfiguration
kubernetesVersion: v1.14.1
imageRepository: registry.aliyuncs.com/google_containers
networking:
podSubnet: 10.244.0.0/16
controlPlaneEndpoint: 172.16.105.26:6443
join
sudo kubeadm init –config=kubeadm-config.yaml –experimental-upload-certs
记录下日志中的join命令
2.2 join k8s-master-follower
分别将k8s-master-follower加入k8s-master-leader
sudo kubeadm join 172.16.105.26:6443 –token c1d2cb.vx086ez76bpggqj5 \
> –discovery-token-ca-cert-hash sha256:bc749b4e7e75f93ea9c0055d1c6e36c814b04247ca9e5bb6168ec3a27e5693bd \
> –experimental-control-plane –certificate-key cdb31f173bf87a573217a4cd1d6e22dc1d396a4da5050e36bdec407bd2aab29d
2.3 为k8s-master-follower绑定vip
您可能注意到follower join时没有先绑定vip。原因是follower join时需要访问k8s-apiserver获取证书等信息,绑定vip直接走本地,获取失败。而此时slb健康检查认为k8s-master-leader是可以负载的,所以直接访问前端slb会负载到k8s-master-leader,可以访问k8s-apiserver。
那为什么还要为k8s-master-follower绑定vip呢?在每个k8s-master-follower请求slb时有1/3的几率负载到自身,此时访问不通。绑定vip后,每个k8s-master-follower访问slb都是访问的本机。
第一篇文章讲述了只有vip,没有实际slb设备的模式下,采用keepalived+haproxy实现高可用的方式。本篇讲述了依赖云厂商SLB高可用和负载均衡时安装k8s。方案一并不完美,通过改良后形成了方案二。当然业内肯定还有很多其他的解决方案,作者才疏学浅,还没来得及一一拜读。
完成本篇的同时又接到了一个新的需要:SLB不是以vip形式提供,而是域名。域名SLB当然比IP要强,大部分云厂商负载均衡肯定不是一台设备,背后都是大规模的集群,会保证SLB服务本身的高可用。这种场景下已经不能通过绑定vip来实现,如何解决呢?敬请期待第三篇。
标签:googl sub epo 实践 思想 lct target tail 故障
原文地址:https://www.cnblogs.com/guarderming/p/12876852.html