标签:二进制 name 网址 load 打印 下载 右键 direct with
/1 前言/上篇文章 手把手教你爬取天堂网1920*1080大图片(批量下载)——理论篇我们谈及了天堂网站图片抓取的理论,这篇文章将针对上篇文章的未尽事宜进行完善,完成图片的批量抓取。
/2 图片网址解析/
1. 我们首先来分析一下这个图片的地址在哪里。我们选择图片,然后右击网页检查,可以看到图片的路径,如下图所示。
2. 将其单独放出来,如下图所示。
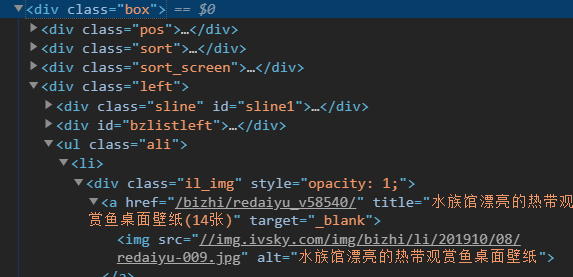
3. 可以看到<a href>就是图片的链接,而src就图片的地址,所以我们可以找它的上一级标签<ul>。如果再找不到那就再找上一级以此类推(找到越详细内容更准确)。使用选择器xpath,获取到src的值(网址后缀)之后,将后缀加上“https前缀”就可以得到每一个网址,如下图所示:
4. 之后尝试运行,如下图所示,可以获取到具体的网址。
5. 我们再对这个网址进行请求(参考一个请求的方法)分析数据。
6. 我们以这个鱼的图片为例,点击它来到二级页面。
7. 右键检查 可以看到我们要获取的是src的地址,如下图所示。
8. 获取图片的源码,如下图所示。
9. Xpath 获取到路径,为了方便区分图片的名字,如下图所示。
/3?下载图片/
1. 为方便储存,新建一个filename来作为保存的路径,如下图所示。
2. 也就是说你需要在Python代码的同级目录,提前新建一个文件夹,名叫“天堂网爬的图片”,如果没有这个文件夹的话,将会报下图的错。

3. 使用with函数进行文件的打开和写入,下方代码的含义是创建一个文件,代码框里边有具体的注释。

"wb" # 意思是以二进制格式打开一个文件只用于写入。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。
"as f" # 意思是写入一个叫f的文件。
"f.wirite(html)" # 意思是说把html的内容写入f这个文件。4. 下面是各个编码代表的含义,可以学习一下。

5. 基于以上代码,基本上就可实现批量下载。接下来,我们继续优化一下。我们导入一个叫fake_useragent的库 fake_useragent第三方库,来实现随机请求头的设置。
fromfake_useragent import UserAgent
ua =UserAgent()
print(ua.ie) #随机打印ie浏览器任意版本
print(ua.firefox)#随机打印firefox浏览器任意版本
print(ua.chrome) #随机打印chrome浏览器任意版本
print(ua.random) #随机打印任意厂家的浏览器6. 我们可以再初始化init方法,添加ua.random,让它随机的产生;其中UserAgent代码如图:(这里设置随机产生50个挑选其中一个进行请求)
7. 最终实现的效果图,终端显示如下图所示。
8.?将图片自动下载到本地后的效果图,高清的噢~
9. 至此,针对解析出来的图片地址予以批量下载的任务已经完成,接下来自己可以开心的去浏览图片啦。
10. 不建议大家爬取太多数据,这样会给服务器增大负载,浅尝辄止即可。
/4 小结/
本文基于理论篇,通过Python 中的爬虫库?requests 、lxml、fake_useragent,带大家进行网页结构的分析以及网页图片地址数据的提取,并且针对解析出来的图片地址予以批量下载,方法行之有效,欢迎大家积极尝试。
如果需要本文源码的话,请在公众号【Python爬虫与数据挖掘】后台回复“高清图片”四个字进行获取,觉得不错,记得给个star噢。
往期精彩文章推荐:
手把手教你爬取天堂网1920*1080大图片(批量下载)——实战篇
标签:二进制 name 网址 load 打印 下载 右键 direct with
原文地址:https://blog.51cto.com/13389043/2494517